If you’re evaluating multimodal AI systems for tasks that demand deep reasoning—such as solving visual math problems, interpreting charts, or analyzing technical diagrams—you’ve likely hit a wall with models that “see” but don’t truly “think.” Many multimodal large language models (MLLMs) generate plausible-sounding answers but lack structured reasoning, especially when visual and textual inputs must be jointly understood.
Enter Vision-R1, a breakthrough MLLM that significantly enhances reasoning capability through reinforcement learning (RL), without relying on expensive human-annotated data. Built on the insight that reasoning can emerge purely from algorithmic feedback—as demonstrated by DeepSeek-R1-Zero in text-only settings—Vision-R1 adapts this principle to the multimodal domain. The result? A model that doesn’t just answer questions but questions itself, reflects on intermediate steps, and arrives at solutions through a human-like “Aha moment.”
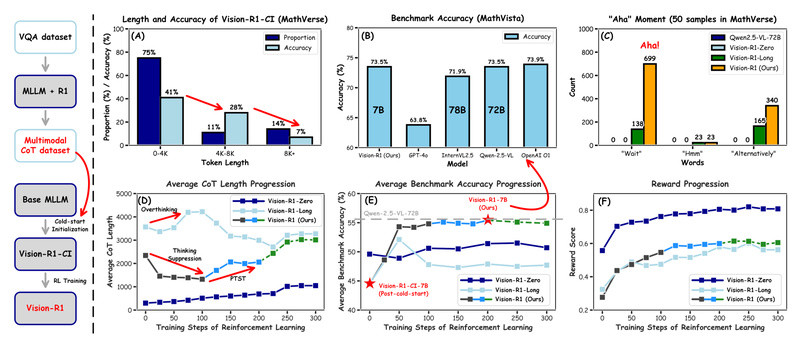
With a 7B-parameter variant scoring 73.5% on MathVista—just 0.4% behind OpenAI’s o1—and even stronger performance from its 32B and 72B versions, Vision-R1 offers state-of-the-art reasoning at multiple scales, making it a compelling choice for both research prototyping and real-world deployment.
What Makes Vision-R1 Different?
Reinforcement Learning Tailored for Multimodal Reasoning
Unlike standard supervised fine-tuning, Vision-R1 leverages RL to incentivize correct reasoning pathways. However, applying RL directly to MLLMs often fails because high-quality multimodal chain-of-thought (CoT) data is scarce. Vision-R1 solves this with a two-stage pipeline:
- Cold-Start Initialization: A 200K-sample multimodal CoT dataset (Vision-R1-cold) is automatically generated by combining outputs from an existing MLLM and DeepSeek-R1 through a technique called modality bridging. This synthetic dataset provides rich reasoning traces without any human labeling.
- Progressive RL Refinement: Using a 10K multimodal math dataset, Vision-R1 applies Progressive Thinking Suppression Training (PTST) and Group Relative Policy Optimization (GRPO) with a hard formatting reward. PTST prevents “overthinking”—a common failure mode where models generate long but incorrect reasoning—by initially constraining output length and gradually relaxing it across training stages.
This approach yields models that not only reason correctly but do so with appropriate depth.
Human-Like Reasoning Dynamics
Vision-R1 exhibits behaviors rarely seen in standard MLLMs: it asks clarifying questions, checks assumptions, and revises its approach mid-process—hallmarks of reflective thinking. On benchmarks like MathVerse, these self-reflective steps lead to more robust and accurate solutions, particularly in problems requiring geometric or symbolic interpretation from images.
Interleaving Reasoning: The Next-Gen Paradigm
Vision-R1 pioneers interleaving reasoning in multimodal AI—a dynamic where the model alternates between analysis, hypothesis, verification, and refinement in multi-turn internal dialogues. This contrasts with linear CoT and aligns with emerging frameworks like those in OpenAI o3 and BAGEL. Early results suggest this paradigm is critical for tackling highly complex, open-ended problems, positioning Vision-R1 at the forefront of next-generation reasoning systems for AGI.
Where Vision-R1 Excels: Practical Use Cases
Educational Technology
For edtech platforms, Vision-R1 can tutor students through visual math problems—interpreting diagrams, explaining steps, and catching common misconceptions. Its ability to generate structured, self-correcting reasoning makes it far more instructive than models that output only final answers.
AI-Powered Analytics
In business intelligence, the model can analyze charts, graphs, and dashboards, then reason about trends, anomalies, or causal relationships. For example, given a bar chart showing quarterly sales, Vision-R1 can infer potential drivers, question data completeness, and suggest follow-up analyses.
Technical Documentation & R&D
Engineers and researchers can use Vision-R1 to parse schematics, circuit diagrams, or scientific figures, translating visual information into logical workflows or mathematical formulations. This is especially valuable in domains like robotics, physics, or biomedical imaging, where multimodal reasoning bridges perception and decision-making.
Getting Started: From Inference to Deployment
Vision-R1 is designed for practical adoption. The official repository provides clear pathways for both inference and training.
Inference Made Simple
You can run Vision-R1-7B locally using either Hugging Face Transformers or vLLM. The latter is recommended for production due to its speed and OpenAI-compatible API support. A typical inference call requires only an image path and a text prompt—no complex preprocessing.
For example, to solve a geometry problem from an image:
python3 inference.py --model_path Vision-R1-7B --image_path ./problem.png --prompt "What is the lateral surface area of this cone?"
Deployment at Scale
Using vLLM, you can deploy Vision-R1 as a RESTful service in minutes:
vllm serve Vision-R1-7B --port 8000 --limit-mm-per-prompt image=5
This enables integration into existing AI pipelines, mobile apps, or web platforms with minimal overhead.
Training (For Advanced Users)
While full training originally required significant GPU resources (e.g., 32×80GB GPUs), the team is actively optimizing the pipeline for 8-GPU setups, making cold-start and RL training more accessible. Training scripts and dataset integration guides are provided for LLaMA-Factory, allowing customization on your own data.
Important Limitations and Considerations
Despite its strengths, Vision-R1 has practical constraints:
- Rolling Releases: Model weights, datasets, and code are being released incrementally. Check the GitHub repo for the latest availability (e.g., Vision-R1-7B is already out; 72B is forthcoming).
- Domain Focus: Performance gains are most pronounced in multimodal math reasoning (MathVista, MathVerse, MM-Math). While general visual understanding is competent, non-mathematical reasoning (e.g., visual storytelling or open-ended scene description) may not see the same uplift.
- Resource Demands for RL Training: Full RL training currently requires high-end infrastructure, though lightweight variants are in development. For most users, inference with pre-trained weights is feasible on a single A100 or even consumer-grade GPUs with quantization.
Summary
Vision-R1 represents a significant leap in multimodal reasoning—not by scaling data or parameters alone, but by intelligently applying reinforcement learning to cultivate how a model thinks. Its synthetic data pipeline eliminates annotation bottlenecks, while PTST and interleaving reasoning unlock human-like problem-solving dynamics. For practitioners in education, analytics, or technical R&D who need reliable, reflective, and mathematically sound visual reasoning, Vision-R1 offers a powerful, accessible, and future-ready solution.
With strong performance even at 7B parameters, open-source tooling, and active community support, it’s a compelling addition to any multimodal AI toolkit.