Voice interaction is becoming a cornerstone of modern human-computer interfaces—whether through smart assistants, customer service bots, or real-time translation tools. Yet, a persistent bottleneck has hindered widespread deployment: high latency in generating the first audible response during streaming inference. Traditional end-to-end speech-language models often require multiple forward passes before producing any audio output, leading to perceptible delays that break conversational flow.
Enter VITA-Audio, a breakthrough open-source large speech-language model that fundamentally rethinks cross-modal token generation. It is the first model of its kind capable of outputting intelligible audio during the very first forward pass, slashing the time to first audio token from 236 ms down to just 53 ms. Built for efficiency without compromising quality, VITA-Audio delivers 3–5× faster inference at the 7B parameter scale and achieves strong performance across automatic speech recognition (ASR), text-to-speech (TTS), and spoken question answering (SQA)—all while being trained exclusively on 200,000 hours of open-source audio data.
For engineers and researchers building real-time voice AI systems, VITA-Audio offers a rare combination: production-ready speed, full reproducibility, and competitive multimodal capabilities—without reliance on proprietary datasets or black-box APIs.
Solving the First-Token Latency Bottleneck
In interactive voice applications, user experience hinges on responsiveness. A delay of even a few hundred milliseconds before the system begins speaking can feel unnatural or frustrating. Prior end-to-end models generate audio tokens sequentially, often requiring several inference steps before the first chunk of sound is ready—especially in streaming scenarios where input arrives incrementally.
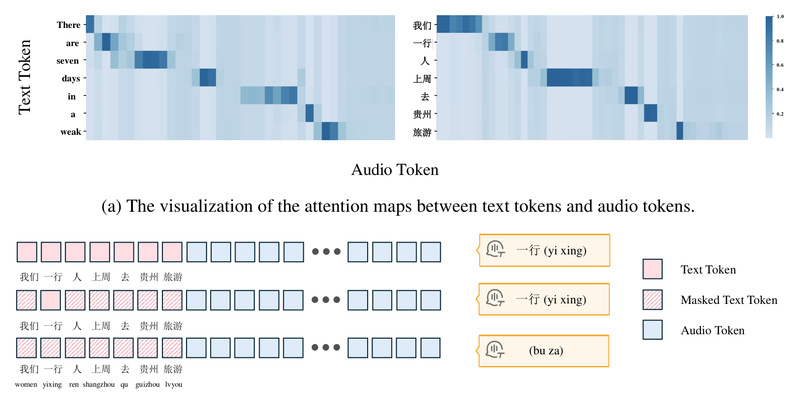
VITA-Audio tackles this problem head-on with its core innovation: the Multiple Cross-modal Token Prediction (MCTP) module. This lightweight component enables the model to predict multiple interleaved audio and text tokens in a single forward pass. Rather than waiting for the full textual response to be generated before synthesizing speech, VITA-Audio begins emitting audio tokens as soon as sufficient context is available—dramatically reducing start-up latency.
This architectural shift makes real-time conversational AI not just possible, but practical. For developers, it means voice agents can “speak while thinking,” closely mimicking human turn-taking in dialogue.
Key Capabilities and Performance Highlights
VITA-Audio stands out through four major strengths that directly address real-world deployment needs:
Ultra-Low Latency Streaming
- Generates the first 32 audio tokens within 53 ms (vs. 236 ms in baseline models).
- Enables truly interactive voice experiences, such as live customer support or real-time language interpretation.
Accelerated Inference
- Achieves 3–5× speedup over comparable 7B-scale models during generation.
- Maintains this efficiency without offloading computation to external modules—everything runs within a single unified architecture.
Strong Multimodal Performance
- Benchmarks competitively against state-of-the-art open models on:
- ASR: Accurate speech-to-text transcription.
- TTS: Natural, intelligible speech synthesis from text.
- Spoken Question Answering (SQA): Understanding and responding to spoken queries with spoken answers.
Fully Open and Reproducible
- Trained solely on publicly available data (200k hours of open-source audio).
- All code, model weights, and training recipes are released, including variants like
VITA-Audio-BoostandVITA-Audio-Plus.
These features make VITA-Audio uniquely suited for teams that need transparency, control, and performance—all in one package.
Practical Use Cases for Developers and Researchers
VITA-Audio is designed for scenarios where low latency and multimodal fluency are non-negotiable:
- Real-Time Voice Assistants: Build responsive AI agents that answer questions and speak immediately, without awkward pauses.
- Speech-to-Speech Translation Systems: Translate spoken language in near real-time for cross-lingual communication.
- Interactive Educational or Accessibility Tools: Provide instant spoken feedback for language learners or visually impaired users.
- Edge-Deployable Dialogue Agents: With future quantization or distillation, the efficient architecture could support on-device voice interaction.
Because VITA-Audio handles ASR, language understanding, and TTS in a single model, it simplifies system architecture compared to cascaded pipelines—reducing integration complexity and synchronization overhead.
Getting Started: Setup, Inference, and Customization
The project provides a complete, open toolchain for immediate experimentation and deployment:
- Environment Setup: Use the provided Docker image (
shenyunhang/pytorch:24.11-py3) or install dependencies fromrequirements_ds_gpu.txt. - Model Weights: Download pretrained checkpoints from Hugging Face (e.g.,
VITA-MLLM/VITA-Audio-Boost). - Audio Components: Integrate the GLM-4-Voice tokenizer (encoder) and decoder from THUDM’s Hugging Face repository.
- Data Preparation: Structure your datasets in the specified JSON format for ASR, TTS, or SQA tasks—examples are provided for all three.
- Run Inference: Execute
tools/inference_sts.pyto test speech-to-speech, ASR, or TTS with both streaming and non-streaming modes. - Fine-Tune: Leverage the four-stage training pipeline (alignment → single MCTP → multi-MCTP → SFT) to adapt the model to your domain.
Full training scripts using DeepSpeed are included, making large-scale fine-tuning feasible for well-resourced teams.
Limitations and Deployment Considerations
While VITA-Audio represents a significant leap forward, practitioners should be aware of several practical constraints:
- Dependencies: The model relies on external audio encoder/decoder components from GLM-4-Voice. These must be correctly configured for inference to work.
- Compute Requirements: At 7B parameters, the model demands substantial GPU memory—likely limiting real-time use on consumer hardware without optimization (e.g., quantization).
- Training Data Availability: Although the data format is documented, the cleaned 200k-hour dataset has not yet been released, which may hinder full replication of training from scratch.
- Stochastic Outputs: Like most generative models, VITA-Audio produces non-deterministic outputs. This requires careful handling in safety-critical or regulated applications.
Nonetheless, for non-safety-critical conversational systems where speed and responsiveness are paramount, VITA-Audio offers one of the most compelling open-source solutions available today.
Summary
VITA-Audio redefines what’s possible in end-to-end speech-language modeling by eliminating the first-token latency barrier that has long plagued real-time voice AI. With its innovative MCTP module, open data foundation, and strong multimodal performance, it empowers developers to build truly conversational agents that speak as fast as they think. Whether you’re prototyping a voice interface or scaling a speech platform, VITA-Audio delivers the speed, quality, and openness needed to move beyond legacy pipelines—making it a standout choice for next-generation voice applications.