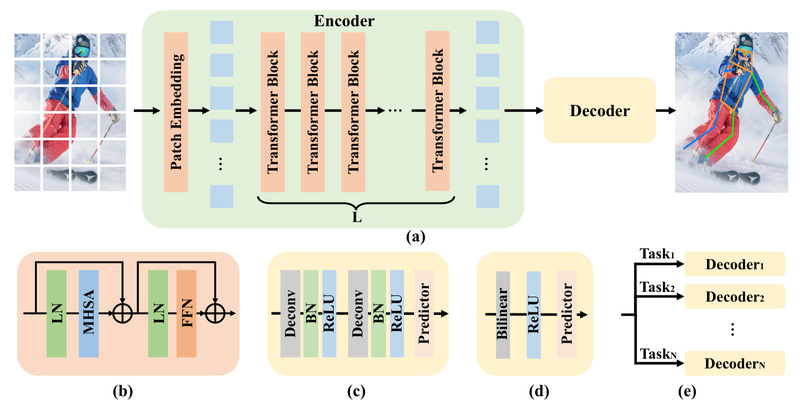
Human and animal pose estimation has long relied on hand-crafted convolutional architectures, intricate post-processing, or task-specific modules. ViTPose changes that narrative. Built on the simple yet powerful Vision Transformer (ViT) architecture, ViTPose delivers state-of-the-art performance across diverse pose estimation tasks—without embedding domain-specific heuristics into its design.
At its core, ViTPose pairs a plain, non-hierarchical Vision Transformer backbone with a lightweight decoder, proving that architectural simplicity can rival—and often surpass—complex CNN-based alternatives. Its extension, ViTPose+, further unifies human, animal, and whole-body pose estimation under a single foundation model, trained across multiple datasets including MS COCO, MPII, AP-10K, and WholeBody.
Why does this matter to you? If you’re building applications that require reliable, accurate, and scalable pose understanding—whether for fitness tracking, sports analytics, wildlife monitoring, or robotics—ViTPose offers a modern, future-proof solution that’s both practical to deploy and easy to adapt.
Simplicity Meets State-of-the-Art Performance
Unlike traditional pose estimators that require multi-stage pipelines or specialized modules for occlusion handling or scale variation, ViTPose adopts a refreshingly minimal design:
- Plain ViT backbone: No hierarchical feature pyramids, no custom attention blocks—just a standard Vision Transformer.
- Lightweight decoder: A simple head converts ViT features into keypoint predictions, avoiding complex refinement stages.
Despite this minimalism, ViTPose achieves 81.1 AP on the MS COCO test-dev set, outperforming many CNN-based and hybrid methods. On challenging benchmarks like OCHuman—which focuses on heavily occluded scenes—it reaches 93.3 AP with the ViTPose-G model, demonstrating robustness where many methods falter.
This performance isn’t accidental. It stems from the inherent strengths of transformers: long-range attention, high parallelism, and strong representation capacity—all without ad-hoc architectural tweaks.
Unmatched Scalability and Flexibility
One of ViTPose’s most compelling advantages is its scalability. Models range from 100 million (ViTPose-S) to over 1 billion parameters (ViTPose-G/H), allowing you to choose the right trade-off between accuracy and inference speed for your use case.
Moreover, ViTPose is highly flexible in several dimensions:
- Input resolution: Works at standard resolutions (e.g., 256×192) and scales to high-res (576×432) for fine-grained tasks.
- Training paradigms: Supports both single-task and multi-task training across human, animal, and whole-body datasets.
- Attention variants: Compatible with different attention mechanisms and pre-training strategies (e.g., MAE pre-training).
- Knowledge transfer: Large ViTPose models can distill knowledge into smaller ones via a “knowledge token”, enabling efficient model compression without retraining from scratch.
This flexibility makes ViTPose ideal for teams that need a unified pose backbone across multiple products or research directions.
Real-World Use Cases Where ViTPose Excels
Human Pose Estimation in Crowded or Occluded Scenarios
ViTPose consistently outperforms on OCHuman, a benchmark designed for occlusion-heavy environments. If your application involves surveillance, retail analytics, or group fitness tracking—where people often overlap—ViTPose’s robustness is a major asset.
Cross-Species Pose Tracking
With ViTPose+, the same model can estimate poses for humans, dogs, horses, and more (trained on AP-10K and APT-36K). This is invaluable for veterinary diagnostics, animal behavior studies, or agricultural automation.
Full-Body and Fine-Grained Keypoint Estimation
ViTPose+ also supports whole-body pose estimation, including face, hands, and feet keypoints. Achieving 61.2 AP on the WholeBody dataset, it’s suitable for sign language recognition, ergonomic assessment, or immersive VR/AR experiences.
Transfer to Specialized Domains
Even without direct training on hand pose datasets, ViTPose+ achieves 87.6 AUC on InterHand2.6M—showcasing strong zero-shot transfer ability from general body to specialized articulations.
Solving Common Pose Estimation Challenges
Traditional pose systems often struggle with:
- Occlusion and crowding: Solved by ViTPose’s global attention, which maintains context even when limbs are hidden.
- Model fragmentation: Instead of maintaining separate models for humans vs. animals, ViTPose+ offers a single, multi-task foundation.
- Accuracy vs. simplicity trade-offs: ViTPose proves you don’t need complex post-processing or multi-stage refinement to achieve top results.
The numbers speak for themselves:
- 79.8 AP on COCO (with CrowdPose multi-task training)
- 82.4 AP on AP-10K animal pose test set
- 94.2 PCKh on MPII for human pose
These aren’t lab-only results—they reflect real-world readiness.
Getting Started: Practical and Accessible
ViTPose is built on PyTorch and integrates with the mmcv/mmpose ecosystem, making it familiar to practitioners in the computer vision community.
Key steps to get started:
- Install dependencies (
mmcv==1.3.9,timm==0.4.9,einops). - Download pre-trained models (MAE-initialized weights available for ViT-S/B/L/H).
- Use provided configs to train or evaluate with simple CLI commands:
bash tools/dist_train.sh configs/vitpose/vitpose_base.py 8 --cfg-options model.pretrained=mae_pretrained.pth bash tools/dist_test.sh configs/vitpose/vitpose_large.py checkpoints/vitpose_l.pth 8
- Try the Hugging Face Gradio demo for quick visual validation on images or video.
For ViTPose+, a lightweight script (tools/model_split.py) reorganizes the MoE-style checkpoint for inference—no extra engineering required.
Limitations and Practical Considerations
While powerful, ViTPose isn’t a magic bullet. Keep these points in mind:
- Requires external detection: ViTPose operates on cropped person/animal bounding boxes. You’ll need a separate detector (e.g., YOLO, Faster R-CNN) for end-to-end deployment.
- Compute demands: Larger models (ViTPose-L/H/G) need high-end GPUs and significant memory, especially at higher resolutions like 576×432.
- Data overlap caution: Multi-dataset training (e.g., with CrowdPose) may introduce train/val leakage, as noted in the official repo—verify evaluation protocols carefully.
- Not real-time by default: While scalable, the largest models prioritize accuracy over speed. For latency-sensitive apps, consider ViTPose-S or knowledge-distilled variants.
Summary
ViTPose redefines what’s possible in pose estimation by showing that simplicity, scalability, and strong pre-training can outperform years of hand-engineered complexity. Whether you’re building a human motion analysis system, tracking animal behavior in the wild, or developing a unified full-body understanding model, ViTPose offers a robust, well-supported, and future-ready foundation.
With open-source code, pre-trained models, and integration into major vision toolchains, adopting ViTPose is not just a research experiment—it’s a practical engineering decision for teams serious about high-accuracy pose estimation.