If you’re building or scaling a system that relies on large language models (LLMs)—whether for chatbots, embeddings, multimodal reasoning, or enterprise AI services—you’ve likely run into bottlenecks around speed, cost, and memory usage. Many open-source inference engines promise performance but fall short under real-world loads, especially when handling long sequences, complex decoding strategies, or high concurrency.
Enter vLLM, an open-source library designed to make LLM serving easy, fast, and cheap—without sacrificing flexibility or compatibility. Originally developed at UC Berkeley’s Sky Computing Lab and now a PyTorch Foundation project, vLLM powers production systems like LMSYS Chatbot Arena and has gained rapid adoption across startups, research labs, and Fortune 500 companies.
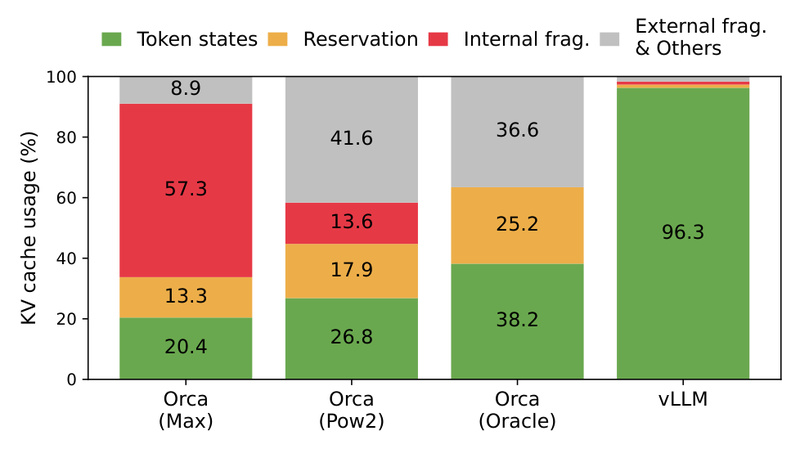
At its core, vLLM solves a fundamental inefficiency in LLM inference: the wasteful management of key-value (KV) cache memory. By introducing PagedAttention—an attention mechanism inspired by operating system virtual memory—it virtually eliminates memory fragmentation and enables unprecedented batching efficiency. The result? 2–4× higher throughput than state-of-the-art systems like FasterTransformer or Orca, with the same latency.
Why vLLM Stands Out: Key Technical Innovations
PagedAttention: Redefining KV Cache Efficiency
Traditional LLM serving systems allocate contiguous blocks of memory for each request’s KV cache. As sequences grow or vary in length, this leads to severe memory fragmentation and underutilization—forcing operators to limit batch sizes or over-provision hardware.
vLLM’s PagedAttention treats KV cache blocks like virtual memory pages: they can be non-contiguous in physical memory but logically contiguous during attention computation. This design enables:
- Near-zero memory waste (as low as 1–2% overhead)
- Flexible sharing of KV caches across requests (e.g., for shared prefixes)
- Dynamic memory allocation that scales with actual token usage
This innovation is especially impactful for long-context models (e.g., Llama-3 70B with 128K tokens) or workloads with variable sequence lengths.
Continuous Batching and Chunked Prefill
Unlike static batching, vLLM uses continuous batching: it dynamically groups incoming requests into batches on-the-fly, maximizing GPU utilization without waiting for fixed batch boundaries. Coupled with chunked prefill, which processes long prompts in segments, vLLM maintains high throughput even with irregular or lengthy inputs—a common pain point in real-world applications.
Hardware-Agnostic Performance with Optimized Kernels
vLLM delivers top-tier performance across diverse hardware:
- NVIDIA GPUs: Full support with FlashAttention and FlashInfer integration
- AMD GPUs & CPUs: Via HIP backend
- Intel CPUs/GPUs, TPUs, PowerPC, Arm, and accelerators like Gaudi, Ascend, and Spyre
Its low-level CUDA/HIP kernels are fine-tuned for minimal overhead, and features like CUDA Graphs eliminate CPU-side scheduling latency during decoding.
Advanced Quantization and Speculative Decoding
To further reduce costs and latency, vLLM supports:
- FP8, INT4, INT8, GPTQ, AWQ, AutoRound quantization
- Speculative decoding, which uses a smaller draft model to predict tokens and verifies them in parallel with the main model—yielding 2–3× speedups with minimal accuracy loss
These capabilities let teams deploy larger models on fewer GPUs or achieve sub-100ms latency for interactive applications.
Real-World Use Cases Where vLLM Excels
High-Concurrency Chat and Agent Services
For platforms handling thousands of concurrent users (e.g., customer support bots, coding assistants), vLLM’s continuous batching and memory efficiency translate directly into lower cloud bills and higher request throughput. Its OpenAI-compatible API makes integration seamless with existing tooling.
Large and Mixture-of-Experts (MoE) Models
vLLM natively supports MoE architectures like Mixtral, Deepseek-V2/V3, and Qwen-MoE. With expert parallelism and optimized routing, it avoids the memory explosion that cripples other inference engines when serving sparse models.
Multimodal and Embedding Workloads
Beyond text, vLLM serves:
- Multimodal LLMs like LLaVA and LLaVA-NeXT
- Embedding models such as E5-Mistral
This makes it ideal for RAG pipelines, cross-modal retrieval, or semantic search at scale.
Production-Ready Deployments
From startups to hyperscalers, vLLM is engineered for production:
- Distributed inference via tensor, pipeline, data, and expert parallelism
- Streaming outputs for real-time user experiences
- Prefix caching to reuse prompt computations across similar queries
- Multi-LoRA support for serving dozens of fine-tuned variants on a single base model
Solving Practitioners’ Top Pain Points
| Pain Point | How vLLM Fixes It |
|---|---|
| KV cache memory waste | PagedAttention reduces fragmentation to near zero |
| Low throughput under load | Continuous batching + chunked prefill maximize GPU utilization |
| Inability to scale long sequences | Efficient memory paging handles 100K+ tokens |
| High cost of serving large models | Quantization + speculative decoding cut GPU requirements |
| Complex deployment across hardware | Unified backend supports NVIDIA, AMD, Intel, TPU, and more |
Getting Started: Simple, Yet Powerful
Adopting vLLM is straightforward:
pip install vllm
It works out-of-the-box with Hugging Face models—just point it to a model ID or local path. Launch an OpenAI-compatible server in one command:
vllm --model meta-llama/Llama-3-8b
For custom integrations, its Python API supports streaming, parallel sampling, beam search, and more. Advanced users can leverage tensor parallelism across multiple GPUs or deploy with LoRA adapters for personalized model variants.
Community resources—including an active Slack, user forum, and frequent meetups worldwide—ensure you’re never stuck.
Limitations and Considerations
While vLLM is production-ready, keep in mind:
- It requires accelerator hardware (GPU, TPU, etc.); CPU-only inference is not a focus.
- Some advanced features (e.g., in vLLM V1 alpha) are still evolving—check release notes for stability.
- Distributed setups (e.g., pipeline parallelism) may require tuning for optimal performance.
However, with strong documentation, active maintenance, and backing from industry leaders (NVIDIA, AWS, Google Cloud, etc.), these hurdles are manageable for most engineering teams.
Summary
vLLM isn’t just another inference engine—it’s a step change in LLM serving efficiency. By rethinking memory management with PagedAttention and combining it with continuous batching, quantization, and hardware-agnostic optimization, it delivers unmatched throughput and cost savings.
Whether you’re deploying a customer-facing chatbot, running multimodal analysis, or serving embedding models at scale, vLLM gives you the performance of a custom-built system with the simplicity of an open-source library. For any technical decision-maker evaluating LLM serving solutions, vLLM deserves a top spot on the shortlist.