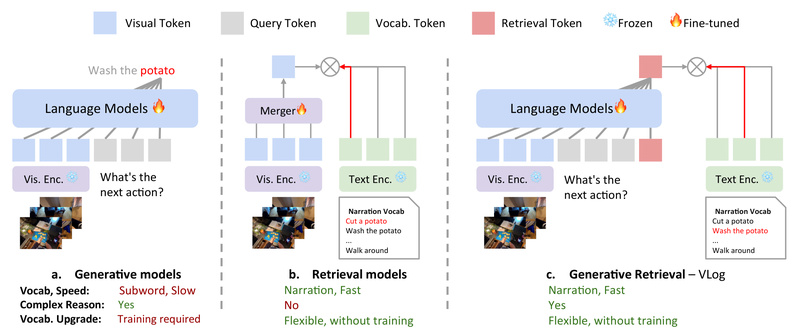
Understanding what happens in videos—especially those capturing everyday human activities—is a core challenge in AI. Most existing video-language models generate descriptions word-by-word, often producing verbose, inconsistent, or contextually weak outputs. VLog offers a fundamentally different approach: it treats video narration as a structured vocabulary of routine events, enabling concise, accurate, and reasoning-aware summaries of human activity.
Developed by researchers at Show Lab and accepted to CVPR 2025, VLog reimagines video understanding not as captioning, but as retrieving and composing pre-defined event phrases—like “turning off an alarm” or “cutting a tomato with the left hand”—that reflect how humans naturally describe daily life. Built on the lightweight GPT-2 architecture, VLog balances efficiency with strong narrative coherence, making it especially valuable for real-world applications where clarity, speed, and structured output matter more than open-ended fluency.
Why VLog Changes the Game in Video Understanding
Traditional video-language models rely on subword or token-level generation, which works well for general text but struggles with the semantic density of human actions. They often miss logical relationships (e.g., “before boiling water, fill the kettle”) or produce descriptions too generic to be useful in practical systems.
VLog flips this paradigm. Instead of generating words from scratch, it uses a narration vocabulary—a curated set of meaningful, real-world event phrases derived from large-scale video datasets. This vocabulary isn’t flat; it’s hierarchical, allowing the model to reason at multiple levels of abstraction. For instance:
- Broad context: kitchen
- Specific action: cutting a tomato
- Fine-grained detail: with the left hand
This structure enables VLog to generate narrations that are both concise and contextually precise, closely mirroring how people actually recount their day.
Core Innovations That Deliver Practical Value
VLog introduces three key technical advances—but more importantly, each one solves a tangible problem faced by developers and researchers:
1. Generative Retrieval: Best of Both Worlds
VLog combines the reasoning power of generative language models with the flexibility of retrieval-based systems. During inference, it doesn’t just “guess” the next word. Instead, it retrieves relevant event phrases from its narration vocabulary and uses GPT-2 to compose them into a coherent sequence.
This hybrid approach means:
- Higher accuracy in event identification
- Lower hallucination risk
- Easy vocabulary updates without full model retraining
2. Hierarchical Narration Vocabulary
Using a novel narration pair encoding algorithm, VLog clusters video narrations from datasets like Ego4D and COIN into a tree-like vocabulary. This allows efficient indexing: if the model detects a “kitchen” scene, it narrows down possible actions to kitchen-related events, then further refines based on visual cues.
The result? Faster inference and more consistent outputs—critical for edge deployment or real-time applications.
3. On-the-Fly Vocabulary Expansion
Encountering a new event not in the original vocabulary? VLog can dynamically extend its narration set using its generative component. For example, if it sees someone “using a new type of espresso machine,” it can propose a new event phrase and integrate it into future predictions—without manual labeling or retraining.
This adaptability is rare in retrieval-augmented systems and makes VLog suitable for long-term, evolving use cases.
Ideal Use Cases: Where VLog Excels
VLog isn’t a general-purpose video captioner. It shines in structured, human-centric activity understanding, particularly when:
- Egocentric video analysis is needed (e.g., smart glasses, lifelogging, assistive tech)
- Instructional content understanding is required (e.g., cooking tutorials, repair guides, fitness demos)
- Concise activity logs must be generated for search, indexing, or summarization
- Reasoning over event sequences matters (e.g., “did the user wash hands before cooking?”)
It’s especially well-suited for teams building applications that require semantic compression—turning minutes of video into a short, readable narrative of key actions.
Getting Started with VLog
The VLog codebase is publicly available on GitHub and built on lightweight GPT-2, making it accessible even without massive GPU resources. The repository includes two main branches:
- VLog: For structured video narration using the generative retrieval framework
- VLog-Agent: For converting video into a textual document (with visual and audio cues) that can be queried by any LLM—enabling chat-style interaction with videos
Setup instructions are clearly documented, and the model’s modular design allows easy integration into existing pipelines. For teams prioritizing efficiency, interpretability, and structured output, VLog offers a compelling alternative to heavy, end-to-end video transformers.
Limitations and When Not to Use VLog
VLog is optimized for routine, narratable human activities. It may underperform in:
- Abstract or artistic videos (e.g., music videos, experimental films)
- Highly dynamic scenes with sparse semantics (e.g., drone racing, crowd surveillance)
- Tasks requiring pixel-level detail or open-ended creative description
Additionally, while it supports vocabulary expansion, its core strength lies in event-level understanding, not fine-grained object tracking or frame-level captioning.
Choose VLog when your goal is structured storytelling, not free-form video description.
Summary
VLog redefines video-language modeling by treating human activity as a vocabulary of meaningful events. Its generative retrieval architecture, hierarchical narration structure, and dynamic vocabulary updates enable concise, accurate, and efficient video understanding—especially for egocentric and instructional content. With a lightweight design and open-source availability, it’s a practical choice for developers and researchers building real-world video intelligence systems that prioritize clarity over verbosity.