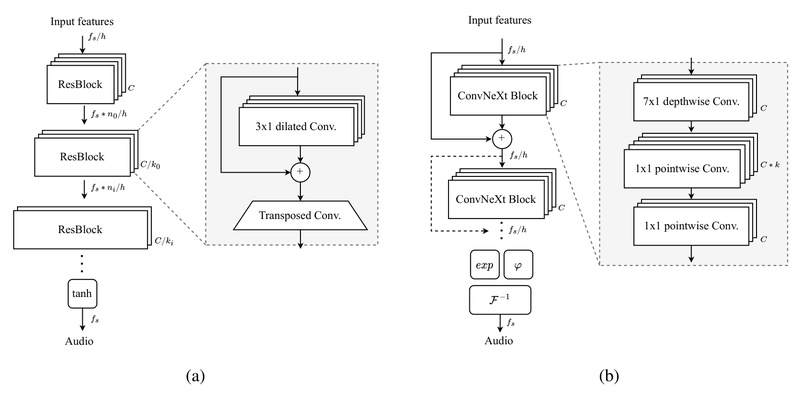
If you’re building or evaluating text-to-speech (TTS), voice cloning, or generative audio systems, the choice of neural vocoder can make or break your pipeline—especially when it comes to speed, quality, and computational efficiency. Vocos stands out as a modern, open-source neural vocoder that bridges a critical gap between traditional time-domain approaches and frequency-domain methods by directly generating Fourier spectral coefficients. Unlike most GAN-based vocoders that model raw audio samples step-by-step, Vocos synthesizes high-fidelity waveforms in a single forward pass using the inverse Fourier transform—resulting in both exceptional audio quality and dramatically faster inference.
Developed by researchers at Gemelo AI and introduced in the paper “Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis,” this model leverages the perceptual relevance of time-frequency representations while sidestepping historic challenges like phase reconstruction. The result? A vocoder that matches or exceeds state-of-the-art quality while running up to 10× faster than comparable time-domain GAN vocoders.
Why Vocos Rethinks Audio Synthesis
Most neural vocoders—particularly those based on GANs like HiFi-GAN or Parallel WaveGAN—operate directly in the time domain. This means they generate raw audio samples, often requiring complex upsampling stacks to go from low-dimensional acoustic features (e.g., mel-spectrograms) to full-resolution waveforms. These architectures are computationally heavy, slow at inference, and often lose the natural inductive bias that frequency-domain representations provide about how humans actually perceive sound.
Vocos takes a different path. Instead of predicting time-domain samples, it predicts complex-valued Fourier spectral coefficients. Because the human auditory system is inherently sensitive to frequency content, this design aligns more closely with perceptual reality. Moreover, once the spectral coefficients are generated, reconstructing the audio waveform is as simple—and as fast—as applying an inverse fast Fourier transform (iFFT). No iterative refinement. No autoregressive sampling. Just one efficient pass.
This architectural shift isn’t just theoretical: it translates into real-world gains in both speed and deployment simplicity.
Key Strengths That Solve Real Engineering Challenges
Single-Pass, High-Quality Waveform Generation
Vocos generates full audio waveforms in a single forward pass—no autoregression, no diffusion steps, and no complex post-processing. This makes it ideal for low-latency applications like real-time voice assistants or interactive voice interfaces.
Up to 10× Faster Than Time-Domain GAN Vocoder
Thanks to its Fourier-based reconstruction, Vocos achieves an order-of-magnitude speedup over traditional GAN vocoders. In practice, this means lower GPU utilization, faster batch processing, and the ability to scale voice services without exponential cost increases.
Competitive Audio Quality
Despite its efficiency, Vocos doesn’t sacrifice quality. In subjective and objective evaluations, it matches or exceeds the performance of leading time-domain vocoders in terms of naturalness and fidelity—especially when trained on high-quality datasets like LibriTTS or DNS Challenge.
Flexible Input Support
Vocos supports two primary input types out of the box:
- Mel-spectrograms: Compatible with standard TTS frontends.
- EnCodec discrete tokens: Enables seamless integration with modern neural audio codecs for copy-synthesis or bandwidth-adaptive reconstruction.
Both modes are pre-trained and ready for immediate use via Hugging Face–style model loading.
Ideal Use Cases for Technical Decision-Makers
Real-Time TTS and Voice Assistants
Because Vocos synthesizes audio in one pass with minimal compute overhead, it’s a strong candidate for latency-sensitive deployments. Teams building cloud-based or edge-deployed voice systems can reduce server load and response time simply by switching vocoders.
Copy-Synthesis Workflows
Need to re-synthesize existing audio with improved quality or consistent voice characteristics? Vocos supports direct copy-synthesis: feed it an audio file, and it will extract features and reconstruct the waveform end-to-end. This is particularly useful for voice data cleaning, anonymization, or style transfer pipelines.
Integration with EnCodec or Bark
Vocos plays well with other modern audio models:
- With EnCodec, it can reconstruct from quantized tokens at configurable bandwidths (1.5, 3.0, 6.0, or 12.0 kbps), enabling efficient audio compression and decompression.
- With Bark, it can serve as a drop-in, higher-quality, faster waveform generator—improving both speed and output fidelity.
These integrations require minimal code changes, making Vocos a low-friction upgrade for teams already using these frameworks.
Getting Started Takes Minutes
Vocos is designed for simplicity. For inference-only use (the most common case), install it with:
pip install vocos
Then, load a pre-trained model and synthesize audio in just a few lines:
import torch
from vocos import Vocos
vocos = Vocos.from_pretrained("charactr/vocos-mel-24khz")
mel = torch.randn(1, 100, 256) # B, C, T
audio = vocos.decode(mel)
Or perform copy-synthesis from an audio file:
import torchaudio
y, sr = torchaudio.load("input.wav")
if y.size(0) > 1:y = y.mean(dim=0, keepdim=True)
y = torchaudio.functional.resample(y, orig_freq=sr, new_freq=24000)
y_hat = vocos(y)
Pre-trained models are available for both mel-spectrogram and EnCodec token inputs, trained on large, diverse datasets and optimized for 24kHz mono audio—the standard for many speech and generative audio applications.
Limitations and Practical Considerations
While Vocos offers compelling advantages, it’s important to assess its fit for your specific use case:
- Sample Rate and Channel: Currently supports only 24kHz mono audio. If your pipeline relies on 16kHz, 48kHz, or stereo, additional preprocessing or adaptation may be needed.
- Input Feature Dependencies: Vocos does not accept arbitrary inputs. It requires either mel-spectrograms with specific dimensions or EnCodec tokens. This means your frontend must align with these expectations.
- EnCodec Bandwidth Selection: When using EnCodec mode, you must provide a
bandwidth_id(e.g., 0 for 1.5 kbps, 2 for 6.0 kbps). Choosing the wrong bandwidth can affect audio quality or introduce artifacts.
These constraints are manageable for most modern TTS and generative audio systems—but they do require alignment with Vocos’s design assumptions.
Summary
Vocos represents a practical and powerful shift in neural vocoding: by moving synthesis into the Fourier domain, it achieves both speed and quality without compromise. For engineers and project leaders evaluating vocoders for production TTS, voice cloning, or generative audio systems, Vocos offers a rare combination of ease of use, computational efficiency, and high-fidelity output. With open-source code, pre-trained models, and straightforward integration paths, it lowers the barrier to deploying state-of-the-art audio synthesis—without the typical trade-offs.
If your project demands real-time performance, scalability, and perceptually aligned audio generation, Vocos is worth a serious look.