In today’s fast-evolving information landscape, even the most advanced large reasoning models (LRMs)—such as OpenAI-o1 or DeepSeek-R1—are constrained by their static internal knowledge. When faced with complex, knowledge-intensive tasks that demand up-to-the-minute data or synthesis across diverse web sources, these models often fall short.
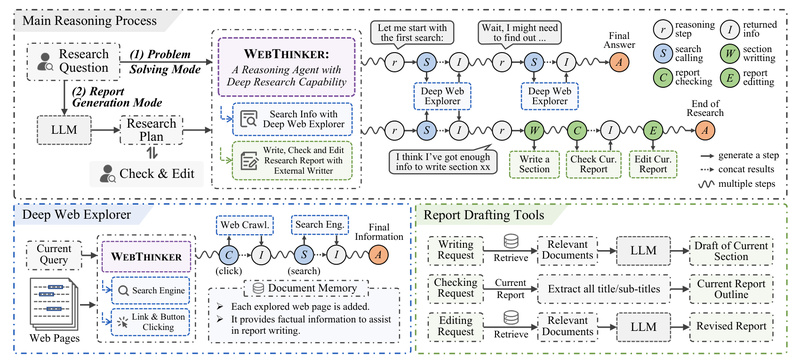
Enter WebThinker: a deep research agent designed to empower LRMs with the ability to autonomously search the web, navigate interactive pages, and draft structured research reports—all within a single, end-to-end reasoning process. Unlike conventional retrieval-augmented generation (RAG) systems that follow rigid, predefined workflows, WebThinker enables the reasoning model itself to dynamically decide when, where, and how to gather external knowledge—blending thinking, searching, and writing in real time.
This capability makes WebThinker uniquely suited for professionals, researchers, and developers who need AI systems that go beyond memorized facts and instead actively explore, verify, and synthesize live web content to produce reliable, comprehensive outputs.
Core Innovations That Enable True Autonomous Research
Deep Web Explorer: Beyond Simple Search Queries
WebThinker introduces a Deep Web Explorer module that transforms how LRMs interact with the web. Rather than stopping at a list of search results, the model can:
- Click on hyperlinks or buttons to navigate deeper into websites
- Extract structured information from dynamically rendered pages (e.g., JavaScript-heavy content)
- Perform iterative, context-aware follow-up searches based on initial findings
This mimics how human researchers explore topics: starting broad, then diving into relevant subpages, cross-referencing sources, and refining queries based on new insights.
Think-Search-and-Draft: Real-Time Report Generation
For tasks requiring detailed output—such as comparative analyses or scientific summaries—WebThinker employs an Autonomous Think-Search-and-Draft strategy. During reasoning, the model can:
- Draft sections of a report as it gathers relevant information
- Review the current state of the report to identify gaps
- Edit or refine content in response to newly discovered evidence
This interleaving of cognition and composition ensures the final output is not only accurate but also logically structured and contextually coherent.
RL-Based Optimization via Online Direct Preference Optimization (DPO)
To refine tool usage and research quality over time, WebThinker uses a reinforcement learning (RL)-based training strategy built on iterative online Direct Preference Optimization (DPO). By analyzing thousands of reasoning trajectories—from successful searches to poorly structured drafts—the system learns to prioritize actions that lead to higher-quality outcomes. This continuous learning loop enhances both the reliability and adaptability of the agent across diverse tasks.
Solving Real Pain Points in AI-Powered Research
Overcoming Static Knowledge Limitations
Traditional LRMs cannot access information beyond their training cutoff date. WebThinker bridges this gap by enabling live web access, ensuring answers reflect the latest developments—critical for domains like AI model comparisons, policy analysis, or emerging scientific breakthroughs.
Replacing Manual, Inefficient Research Workflows
Manually gathering, verifying, and synthesizing information from dozens of web pages is time-consuming and error-prone. WebThinker automates this entire pipeline, reducing hours of work to minutes while maintaining high fidelity to source material.
Moving Beyond Rigid RAG Architectures
Standard RAG systems retrieve documents upfront and pass them to a language model in a single shot. This limits adaptability: if the initial retrieval misses key sources, the model has no way to recover. WebThinker’s interactive, decision-driven approach allows it to course-correct mid-reasoning—making it far more robust for complex, open-ended queries.
Ideal Use Cases Where WebThinker Excels
- Answering PhD-level scientific questions (e.g., on GPQA or Humanity’s Last Exam benchmarks) that require synthesizing knowledge from multiple disciplines
- Generating comparative technical reports, such as “What are the differences between OpenAI’s o1, DeepSeek-R1, and Claude 4?”
- Supporting investigative tasks on platforms like GAIA or WebWalkerQA, where success depends on navigating real websites to extract specific facts
- Producing structured summaries of emerging technologies, market trends, or regulatory changes using live web data
In all these scenarios, WebThinker doesn’t just retrieve—it reasons, explores, and writes.
Getting Started: Practical Setup Guide
WebThinker is designed for developers and researchers who already have access to powerful reasoning models. Here’s how to begin:
1. Model Serving
- Serve a reasoning model (e.g., QwQ-32B) and an auxiliary model (e.g., Qwen2.5-32B-Instruct) using vLLM
- The reasoning model drives decision-making; the auxiliary model assists with webpage parsing, report editing, and evaluation
2. Configure Web Search
- Use Google Serper API (recommended; Bing support ends August 2025)
- Set your API key in the configuration
3. Run Inference
- For problem-solving: use
scripts/run_web_thinker.pywith a single question or a benchmark dataset (e.g., GAIA, GPQA) - For report generation: use
scripts/run_web_thinker_report.pywith open-ended prompts or the Glaive benchmark - For quick exploration: launch the Streamlit demo (
demo/run_demo.py) after configuringsettings.py
All outputs are saved automatically for evaluation using built-in scripts that support LLM-based grading or human-aligned listwise comparisons.
Current Limitations and Operational Considerations
While powerful, WebThinker requires:
- Two hosted models (reasoning + auxiliary), which demands significant GPU resources
- External API access for search (Serper is now the primary option)
- Web parsing infrastructure (e.g., Crawl4AI integration recommended for JavaScript-heavy sites)
It is not a plug-and-play SaaS tool but rather a framework for teams with the technical capacity to deploy and manage model serving stacks.
Evidence of Performance and Reliability
WebThinker has been rigorously evaluated across multiple challenging benchmarks:
- GPQA: Tests deep scientific reasoning
- GAIA & WebWalkerQA: Require real web navigation and fact extraction
- Humanity’s Last Exam (HLE): Features extremely difficult, multi-step problems
- Glaive: Assesses open-ended report quality
Results show WebThinker consistently outperforms both open-source agents and strong proprietary systems—including commercial deep research offerings—demonstrating its state-of-the-art capability in autonomous web-based reasoning.
Summary
WebThinker redefines what’s possible for large reasoning models by embedding real-time web research directly into the reasoning loop. Its ability to autonomously explore, verify, and synthesize information from the live web—while simultaneously drafting structured, high-quality reports—makes it an invaluable tool for anyone tackling knowledge-intensive, open-ended problems.
If your work demands more than static knowledge—if it requires adaptive exploration, multi-source validation, and intelligent synthesis—then WebThinker provides the architecture, performance, and flexibility to turn complex research challenges into automated, reliable workflows.
The code is open-source (MIT licensed) and available on GitHub, with models published on Hugging Face—enabling immediate experimentation and integration into your own AI pipelines.