Conventional object detectors like YOLOv8 are fast, reliable, and widely deployed—but they come with a critical limitation: they can only recognize objects from a fixed set of pre-defined categories. This makes them unsuitable for real-world scenarios where new or unexpected objects appear regularly, such as in robotics, smart retail, or user-facing mobile vision apps.
YOLOE (pronounced “YOLO-ee”) directly addresses this limitation by enabling real-time, open-vocabulary object detection and segmentation—meaning it can “see anything” on the fly using flexible prompts, whether textual (“red bicycle, fire hydrant”), visual (a reference bounding box or mask from another image), or even with no prompt at all. Crucially, it achieves this without sacrificing inference speed, deployment simplicity, or training efficiency, making it the first truly practical open-set YOLO-style model for production use.
Why Traditional YOLO Models Fall Short in Open Scenarios
Standard YOLO variants excel in closed-set detection: they’re trained on datasets like COCO with 80 fixed classes and perform exceptionally well within that scope. But when faced with an object outside those categories—say, a “scooter” in a warehouse or a “vintage typewriter” in a museum—they either miss it entirely or mislabel it as something familiar.
Recent open-vocabulary approaches (e.g., YOLO-World) attempt to solve this by integrating vision-language models like CLIP. However, they often introduce significant computational overhead, complex deployment pipelines, or require expensive retraining. This trade-off between flexibility and efficiency has hindered real-world adoption—until YOLOE.
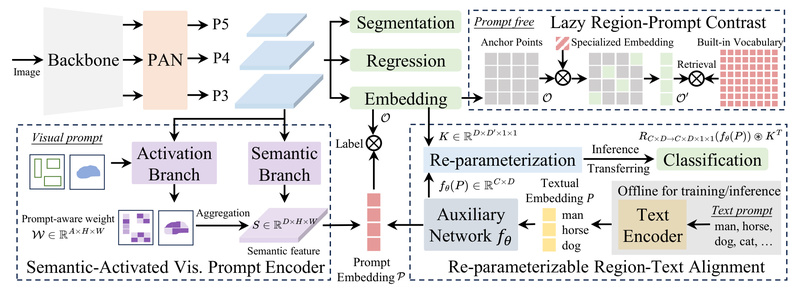
YOLOE’s Three-Prompt Paradigm: Flexibility Without Overhead
YOLOE unifies three distinct prompting mechanisms in a single, lightweight architecture, each optimized for different use cases:
Text Prompts: Re-parameterizable Region-Text Alignment (RepRTA)
YOLOE refines pre-trained text embeddings (e.g., from MobileCLIP) using a re-parameterizable auxiliary network. During training, this lightweight module enhances alignment between visual regions and textual descriptions. At inference time, the auxiliary network is folded into the main model via structural re-parameterization—resulting in zero additional latency or memory cost compared to a standard YOLOv8 model.
Visual Prompts: Semantic-Activated Visual Prompt Encoder (SAVPE)
For scenarios where users point to or crop a region of interest (e.g., “find more objects like this”), YOLOE uses SAVPE—a compact encoder with decoupled semantic and activation branches. This design captures fine-grained visual semantics while maintaining minimal computational complexity, enabling accurate cross-image matching with negligible overhead.
Prompt-Free Mode: Lazy Region-Prompt Contrast (LRPC)
When no external prompt is available, YOLOE leverages a built-in large vocabulary and a specialized embedding space to detect and segment objects autonomously. Unlike methods that rely on external language models during inference, YOLOE’s LRPC strategy embeds category knowledge directly into the model, avoiding runtime dependencies and ensuring consistent performance.
Real-World Performance: Speed, Efficiency, and Accuracy
YOLOE doesn’t just promise flexibility—it delivers measurable gains across key metrics:
- On LVIS, YOLOE-v8-S achieves 27.9 AP with text prompts—3.5 points higher than YOLO-Worldv2-S—while using 3× less training time and running 1.4× faster at inference.
- On mobile hardware (iPhone 12 via CoreML), YOLOE-v8-S delivers 64.3 FPS, enabling real-time open-vocabulary perception in edge applications.
- When fine-tuned on COCO, YOLOE-v8-L outperforms the closed-set YOLOv8-L by 0.6 AP (detection) and 0.4 AP (segmentation)—despite 4× less training time.
Even in prompt-free mode, YOLOE-v8-L achieves 27.2 AP on LVIS, demonstrating strong zero-shot generalization without any user input.
Seamless Integration into Existing YOLO Workflows
One of YOLOE’s most practical advantages is its full compatibility with YOLOv8 and YOLO11 ecosystems. After re-parameterization, YOLOE becomes architecturally identical to its closed-set counterpart—meaning you can:
- Export models to ONNX, TensorRT, or CoreML with the same tools used for YOLOv8.
- Fine-tune via linear probing (updating only the final classification layer) or full tuning, depending on data availability.
- Plug YOLOE directly into existing pipelines that already use Ultralytics YOLO—no code overhaul required.
Getting Started in Minutes
YOLOE is designed for rapid experimentation and deployment:
- Install via Conda or pip, including optional dependencies for MobileCLIP.
- Load a pre-trained model in one line:
from ultralytics import YOLOE model = YOLOE.from_pretrained("jameslahm/yoloe-v8l-seg") - Run inference with your choice of prompt:
- Text:
--names "person, dog, suitcase" - Visual: Provide a reference image and coordinates
- Prompt-free: No input needed—YOLOE detects everything it knows
- Text:
Colab notebooks and a Gradio demo (app.py) are provided for immediate hands-on testing.
Practical Considerations and Limitations
While YOLOE significantly advances open-vocabulary perception, users should keep in mind:
- The prompt-free mode relies on a fixed internal vocabulary (derived from LVIS and training data). It cannot recognize arbitrary new concepts without fine-tuning.
- Performance on rare or abstract categories may lag behind common objects—though zero-shot results on LVIS (which emphasizes rare classes) remain strong.
- The model requires the MobileCLIP-B(LT) text encoder weights for text-prompted inference, which must be downloaded separately.
- For domain-specific tasks (e.g., medical imaging or industrial inspection), lightweight fine-tuning (even just linear probing) is recommended to maximize accuracy.
Summary
YOLOE redefines what’s possible in real-time computer vision by delivering open-vocabulary detection and segmentation with YOLO-level speed and minimal computational cost. Its unified support for text, visual, and prompt-free inputs—combined with zero-overhead deployment and seamless YOLOv8/YOLO11 compatibility—makes it the most practical choice for developers, researchers, and engineers building adaptive vision systems for dynamic, real-world environments. If your project demands the ability to “see anything” without sacrificing efficiency, YOLOE is the smart, scalable solution.