YOLOv6 is a high-performance, single-stage object detection framework developed by Meituan with a strong emphasis on real-world industrial applications. Unlike purely research-oriented detectors, YOLOv6 is engineered to deliver an exceptional balance between inference speed and detection accuracy—making it ideal for deployment in resource-constrained environments such as edge devices, mobile platforms, and real-time video analytics systems. With the release of YOLOv6 v3.0, the framework introduces significant architectural and training enhancements that push the boundaries of what’s achievable in practical object detection.
This article explores why YOLOv6 stands out among mainstream detectors like YOLOv5, YOLOv8, YOLOX, and PP-YOLOE—particularly in scenarios where latency, throughput, and hardware compatibility are critical decision factors for engineers and technical leads.
Performance That Matches Real-World Demands
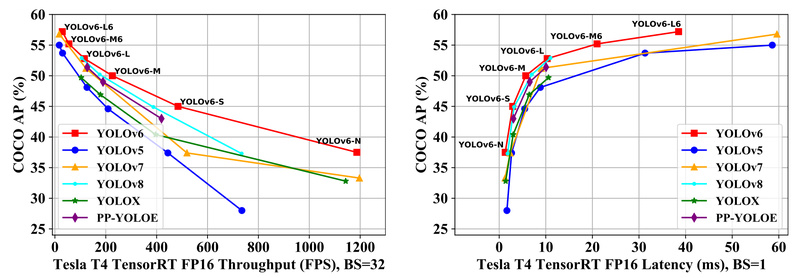
YOLOv6 v3.0 sets a new benchmark for real-time object detection. On the COCO val2017 dataset using an NVIDIA Tesla T4 GPU, YOLOv6 achieves impressive results across multiple model scales:
- YOLOv6-N: 37.5% mAP at 1187 FPS (batch size 32, TensorRT FP16)
- YOLOv6-S: 45.0% mAP at 484 FPS
- YOLOv6-M: 50.0% mAP at 226 FPS
- YOLOv6-L: 52.8% mAP at 116 FPS
These figures consistently outperform competing models of similar size. For instance, YOLOv6-S surpasses YOLOv5-S, YOLOv8-S, YOLOX-S, and PP-YOLOE-S in both accuracy and speed.
For higher-resolution needs, YOLOv6 also offers P6 models (trained at 1280×1280 input), with YOLOv6-L6 reaching 57.2% mAP—making it one of the most accurate real-time detectors available. This dual support for P5 (640×640) and P6 (1280×1280) resolutions gives teams flexibility depending on their accuracy and latency requirements.
Deployment Flexibility Across Hardware Platforms
One of YOLOv6’s most compelling strengths is its adaptability across diverse deployment targets:
Server and Cloud Inference
YOLOv6’s base models (N, S, M, L) are optimized for NVIDIA GPUs with TensorRT, delivering extremely high throughput even in batched inference—critical for video surveillance, logistics automation, and cloud-based vision APIs.
Edge and Mobile Optimization
The framework includes:
- Quantized INT8 models (e.g., YOLOv6-N RepOpt: 34.8% mAP at 1828 FPS on T4), enabling ultra-fast inference on edge accelerators with minimal accuracy drop.
- YOLOv6Lite series specifically designed for CPU and mobile SoCs. Benchmarks show YOLOv6Lite-L runs in 7.02 ms on a Qualcomm Snapdragon 888 (high-end mobile), 9.66 ms on a MediaTek Dimensity 720 (mid-range), and 36.13 ms on a legacy Snapdragon 660—proving its viability across hardware tiers.
Input resolutions for YOLOv6Lite can be scaled down (e.g., 224×128) to meet strict latency budgets on low-power devices.
Specialized Variants
YOLOv6 has expanded beyond generic object detection:
- YOLOv6-Segmentation: adds instance segmentation capability.
- YOLOv6-Face: optimized for facial detection tasks.
- Support for Android, OpenVINO, ONNX, NCNN, and OpenCV ensures seamless integration into production pipelines.
Solving Real Engineering Pain Points
YOLOv6 directly addresses common challenges faced by teams building vision systems:
- Real-time SLA compliance: High FPS ensures systems meet strict latency requirements (e.g., autonomous drones, robotic arms).
- Cost-efficient scaling: High throughput reduces the number of GPUs needed in data centers.
- On-device feasibility: YOLOv6Lite and quantized models enable powerful vision capabilities directly on phones, IoT cameras, or embedded systems—avoiding cloud dependency and latency.
- Industrial robustness: The framework includes production-ready tooling for training, evaluation, quantization, and deployment, reducing integration overhead.
Getting Started Is Simple and Well-Supported
YOLOv6’s repository is tailored for rapid adoption:
- Install: Clone the repo and install dependencies with a single command.
- Fine-tune: Use preconfigured YAML files (e.g.,
yolov6s_finetune.py) to adapt models to custom datasets in standard COCO or YOLO format. - Evaluate: Reproduce official benchmarks with built-in evaluation scripts.
- Infer: Run detection on images, videos, or live webcam feeds using
tools/infer.py. - Deploy: Export to ONNX, TensorRT, NCNN, or OpenVINO with provided tutorials.
The project also provides extensive documentation, including quantization guides, speed testing protocols, and community-driven examples (e.g., Amazon SageMaker integration, Android demos, and Gradio web apps).
Limitations and Practical Considerations
While YOLOv6 excels in many areas, users should be aware of a few constraints:
- P6 models do not support anchor-based auxiliary training (the “fuse_ab” feature), limiting certain training optimizations for high-resolution variants.
- Quantized models (INT8) trade ~1–2% mAP for significant speed gains—acceptable for most industrial use cases but worth validating per application.
- YOLOv6Lite models are significantly less accurate (e.g., 22.4–28.0% mAP) and best suited for lightweight tasks like person detection or coarse object counting on mobile.
- Peak performance assumes proper hardware (e.g., TensorRT on NVIDIA GPUs) and correctly formatted datasets.
Summary
YOLOv6 is not just another YOLO variant—it’s a purpose-built solution for teams who need reliable, fast, and accurate object detection in real-world systems. Whether you’re deploying on a data center GPU, an edge AI accelerator, or a smartphone CPU, YOLOv6 offers a tailored model and a clear path from training to production. Its consistent outperformance of competing frameworks, combined with strong industrial backing from Meituan and comprehensive tooling, makes it a top choice for engineers prioritizing both performance and practicality.
If your project demands real-time inference, hardware flexibility, and minimal deployment friction, YOLOv6 deserves serious consideration.