In today’s fast-paced IT and enterprise environments, teams increasingly rely on retrieval-augmented generation (RAG) systems to provide accurate, context-aware answers from internal documentation—especially in complex domains like network operations. However, many existing RAG solutions demand heavy computational resources, fine-tuned models, or intricate pipelines that are difficult to deploy and maintain. Enter EasyRAG: a simple, lightweight, and efficient RAG framework designed specifically for practical, real-world deployment.
Developed for the CCF AIOps 2024 Challenge, EasyRAG delivers competitive accuracy—securing first place in the preliminary round and second in the semifinals of the GLM4 track—while running on modest hardware (just one GPU with 16GB VRAM). It requires no model fine-tuning, uses off-the-shelf components like BM25 and BGE-reranker, and supports plug-and-play inference acceleration. For engineering teams managing network infrastructure or building domain-specific question-answering systems with limited AI budgets, EasyRAG offers a rare combination of performance, simplicity, and efficiency.
Why EasyRAG Stands Out
High Accuracy Through a Streamlined RAG Pipeline
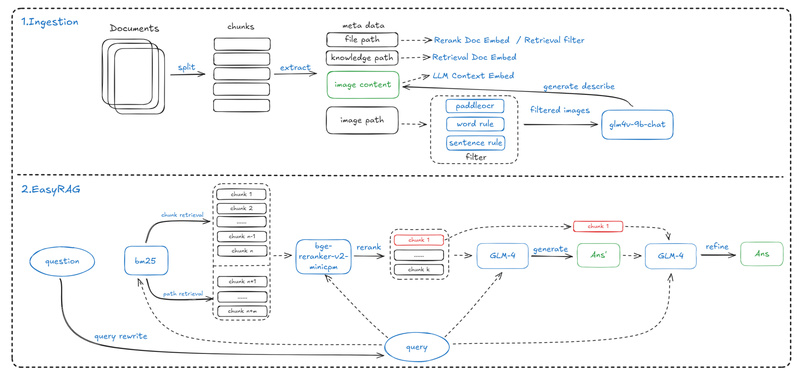
EasyRAG achieves state-of-the-art question-answering accuracy through a carefully structured four-stage pipeline:
- Domain-specific data processing: Custom chunking and metadata extraction tailored for network operation documents.
- Dual-route sparse retrieval: Combines multiple retrieval paths (e.g., BM25) for robust coarse ranking.
- LLM-powered reranking: Uses the BGE-reranker to refine retrieved results before generation.
- Answer generation and optimization: Leverages large language models (initially GLM4) to produce clear, grounded responses.
This modular design ensures high relevance without overcomplicating the architecture—making it both accurate and interpretable.
Simple Deployment, No Fine-Tuning Required
Unlike many RAG systems that require training custom embedders or fine-tuning LLMs, EasyRAG is built entirely from pre-trained, off-the-shelf components. The core retrieval relies on BM25 (a proven sparse retrieval method), while reranking uses the BGE-reranker, both of which run efficiently on CPUs or modest GPUs. There’s no need to manage model training pipelines or large-scale vector databases—just configure your API keys and run.
Moreover, EasyRAG provides a flexible codebase with interchangeable search, reranking, and generation strategies. This modularity allows teams to adapt the pipeline to their specific data or domain without rewriting the entire system.
Efficient Inference with Plug-and-Play Acceleration
Latency is a critical bottleneck in production RAG systems. EasyRAG addresses this with dedicated inference acceleration techniques for each stage—coarse retrieval, reranking, and answer generation. These optimizations significantly reduce end-to-end latency while preserving answer quality. Crucially, each acceleration module is plug-and-play, meaning you can integrate them selectively into existing RAG workflows, even outside EasyRAG.
This focus on efficiency makes EasyRAG ideal for edge deployments or environments where GPU resources are constrained but responsiveness is non-negotiable.
Ideal Use Cases
EasyRAG excels in scenarios where:
- Domain knowledge is structured but not massive: Think internal network operation manuals, incident reports, or enterprise knowledge bases.
- Hardware resources are limited: With a 16GB GPU minimum and no need for model training, it fits into cost-sensitive or on-premises setups.
- Rapid deployment is required: Teams can go from code checkout to a working QA system in minutes using the provided scripts.
- Accuracy and speed must coexist: The framework balances both, as validated in a competitive benchmark (CCF AIOps 2024).
While the current implementation focuses on Chinese-language network operation data, the architecture is language- and domain-agnostic. With minimal adaptation—such as swapping stopword lists or chunking rules—it can serve English-language or other technical domains.
Getting Started Is Straightforward
EasyRAG is designed for usability. Here’s how to run it:
-
Install dependencies:
pip install -r requirements.txt git lfs install
-
Download models and process data:
bash scripts/download.sh # fetches required models bash scripts/process.sh # preprocesses ZEDx dataset
-
Configure your LLM API key (e.g., for GLM) in
src/easyrag.yaml. -
Run directly:
cd src && python3 main.py
Or launch via Docker for reproducibility:
./scripts/run.sh
For interactive testing, EasyRAG includes both a FastAPI endpoint (api.py) and a Streamlit-based WebUI (webui.py), enabling quick validation without writing integration code.
The project structure is clean and well-documented, with clear separation between ingestion, retrieval, reranking, and generation—making customization straightforward for engineers.
Limitations and Considerations
While EasyRAG is highly capable, users should be aware of a few constraints:
- LLM dependency: The system currently expects access to GLM (e.g., GLM4) via API keys. While the architecture supports swapping LLMs, the default setup assumes GLM availability.
- Hardware requirement: A GPU with at least 16GB VRAM is needed, primarily for the reranker and LLM. CPU-only inference is possible but not optimized out of the box.
- Domain focus: The provided data pipeline is tuned for network operations and Chinese text. Extending to other domains or languages may require adjustments to preprocessing (e.g., chunking logic, stopword lists).
That said, the framework’s modular design makes these adaptations feasible—even for non-research engineers.
Summary
EasyRAG proves that high-performance RAG doesn’t require massive models, fine-tuning, or expensive infrastructure. By combining sparse retrieval, efficient reranking, and smart inference acceleration, it delivers accuracy and speed in a package that’s easy to deploy and scale. For teams in network operations, IT support, or enterprise knowledge management—especially those working with limited resources—EasyRAG offers a practical, battle-tested solution that’s ready to use today.
With its open-source release, Docker support, and flexible pipeline, EasyRAG lowers the barrier to building production-grade RAG systems without sacrificing performance.