Imagine managing a project that needs to understand speech, analyze images, interpret video frames, and respond to written prompts—all within the same system. Traditionally, you’d stitch together multiple specialized models, each trained on a single modality. That approach quickly becomes complex, expensive, and inconsistent in performance. Enter Uni-MoE: a unified multimodal large language model (MLLM) built on the Mixture of Experts (MoE) architecture that natively supports text, images, audio, and video in a single, scalable framework.
Developed by researchers at HITsz-TMG and published in IEEE TPAMI 2025, Uni-MoE isn’t just another multimodal model—it’s a strategic shift toward efficiency, fairness, and generalization across modalities. If you’re evaluating AI systems for applications that span multiple data types, Uni-MoE offers a compelling path to reduce engineering overhead while improving cross-modal consistency.
Why Uni-MoE Stands Out
Unified Architecture for Multimodal Understanding
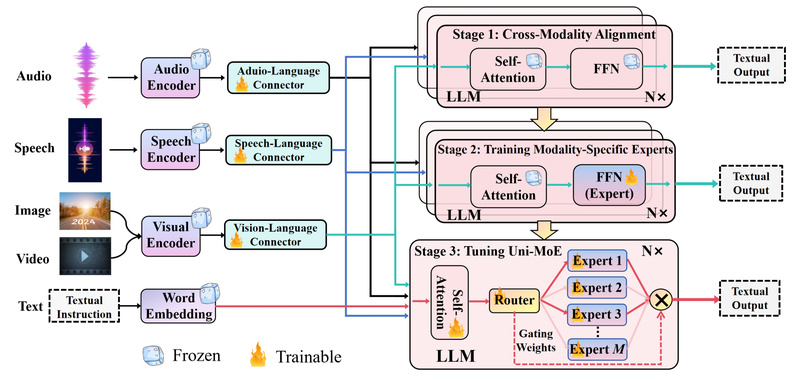
Uni-MoE uses modality-specific encoders (e.g., for audio, vision, or text) connected via trainable “connectors” that map all inputs into a shared representation space. This design ensures that different data types don’t compete for attention in incompatible ways—they’re harmonized before entering the language model core. The result? A system that treats a spoken question, a screenshot, and a video clip as equally valid inputs to the same reasoning engine.
Mixture of Experts for Efficiency and Specialization
Unlike dense MLLMs that activate all parameters for every input, Uni-MoE implements a sparse MoE architecture. Only a subset of experts is activated per input, and—critically—experts are organized by modality preference. This means when processing an audio clip, primarily audio-specialized experts are engaged, reducing wasted computation.
Training leverages modality-level data parallelism and expert-level model parallelism, enabling efficient scaling across multi-node GPU clusters. The codebase explicitly supports distributed MoE modules, making it feasible to train and fine-tune large versions (e.g., Uni-MoE-v2 with 8 experts) without prohibitive hardware costs.
Reduced Performance Bias Across Modalities
A common pain point in multimodal systems is modality bias: models perform well on text but struggle with audio, or excel on images but falter on video. Uni-MoE directly addresses this through a progressive training strategy:
- Cross-modality alignment: Connectors are trained on paired data (e.g., image–caption, speech–transcript) to align representations.
- Expert activation tuning: Modality-specific experts are trained on cross-modal instruction data to develop clear “preferences” without siloing knowledge.
- Unified fine-tuning with LoRA: The full system is refined on mixed multimodal instruction data using Low-Rank Adaptation, enabling efficient adaptation without full retraining.
Experiments show this approach significantly reduces performance gaps between modalities and enhances collaboration among experts—meaning the model doesn’t just handle mixed inputs, it understands how they relate.
Practical Use Cases
Uni-MoE shines in scenarios where multimodal cohesion matters more than isolated modality performance:
- Intelligent assistants that respond to voice commands while analyzing uploaded images or video clips (e.g., “What’s happening in this video from 0:30?”).
- Content moderation or analysis platforms that process social media posts containing text, images, and embedded audio/video in a unified pipeline.
- Accessible interfaces for users with diverse input preferences—typing, speaking, or uploading visuals—without switching models.
- Research prototyping where rapid iteration across modalities is needed without maintaining separate model stacks.
In all these cases, Uni-MoE eliminates the need to deploy, maintain, and synchronize multiple single-modality models—reducing both operational complexity and inference latency.
Getting Started
The Uni-MoE team provides:
- Pre-trained checkpoints, including Uni-MoE-v2 (8-expert version), available for immediate inference.
- Fine-tuning scripts that support multi-node, multi-GPU training with distributed MoE modules.
- LoRA-based tuning support, allowing you to adapt the model to your own multimodal instruction datasets with minimal resource overhead.
While the system requires integration of modality-specific encoders (e.g., Whisper for audio, ViT for images), the provided connectors and training scripts streamline the process. Engineers can leverage the existing infrastructure to plug in their preferred encoders or use the ones validated in the paper.
Limitations and Considerations
Uni-MoE is powerful but not plug-and-play for every scenario:
- Encoder dependency: You still need high-quality, pre-trained encoders for each modality. The model doesn’t replace them—it unifies their outputs.
- Compute demands: Despite MoE sparsity, large expert counts and multimodal inputs require substantial GPU memory. The 8-expert v2 model is efficient relative to dense models of similar capacity, but not lightweight.
- Data quality sensitivity: The progressive training strategy assumes access to diverse, high-quality multimodal instruction data. Performance on low-resource or noisy modalities may lag without proper tuning.
These aren’t dealbreakers—they’re design trade-offs. If your project already handles multiple modalities and struggles with fragmentation or bias, Uni-MoE’s architecture directly targets those issues.
Summary
Uni-MoE rethinks multimodal AI not as a collection of parallel pipelines, but as a unified reasoning system with specialized, sparsely activated expertise. By combining MoE efficiency with a progressive, alignment-aware training strategy, it delivers consistent performance across text, image, audio, and video—without forcing you to maintain five separate models.
For project leads, engineers, and researchers seeking a scalable, bias-resistant foundation for multimodal applications, Uni-MoE offers both technical sophistication and practical deployability. With open-source code, pre-trained weights, and support for distributed training, it’s ready for real-world adoption.