For engineers and technical decision-makers building perception stacks in autonomous driving, robotics, or 3D scene understanding, accurately detecting objects from raw LiDAR point clouds is a foundational requirement. Yet many existing 3D detectors either compromise on efficiency, rely on complex handcrafted components, or struggle with long-range detection—especially in fully sparse architectures that avoid dense voxel grids for scalability.
FSD V2 ("Fully Sparse 3D Object Detection Version 2") directly addresses these pain points. Building on the success of its predecessor FSDv1, FSD V2 simplifies the architecture while improving generalization and performance—thanks to a novel concept called virtual voxels. This open-source solution delivers state-of-the-art results across three major benchmarks (Waymo, nuScenes, and Argoverse 2), with particular strength in long-range scenarios, all while maintaining a streamlined, easier-to-deploy design.
Why Simplicity Matters in Sparse 3D Detection
Early sparse 3D detectors often relied on dense pre-processing or intricate post-clustering steps to group points into object proposals. FSDv1 broke ground by operating entirely in sparse space, but it still depended on handcrafted instance-level representations—limiting its adaptability and adding engineering complexity.
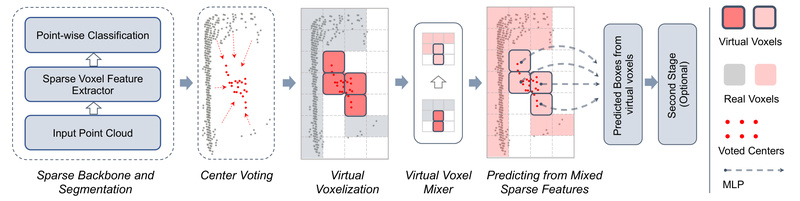
FSD V2 eliminates this dependency. Instead of clustering points into instances using custom heuristics, it introduces virtual voxels: implicit, learnable representations that naturally capture object geometry without explicit clustering logic. This not only removes inductive bias but also resolves a critical flaw in sparse detectors known as the Center Feature Missing problem—where object centers fall in empty space between sparse points, leading to detection failures.
By embedding object context directly through virtual voxels, FSD V2 achieves both architectural elegance and robustness.
Core Innovations: Virtual Voxels and Their Components
The virtual voxel mechanism is supported by three key components:
- Virtual Voxel Encoder: Transforms raw LiDAR points into a structured sparse representation that encodes geometric and semantic cues around potential object centers—even when those centers contain no actual points.
- Virtual Voxel Mixer: Aggregates features across neighboring virtual voxels to enhance contextual understanding, mimicking the effect of clustering but in a fully differentiable, data-driven way.
- Virtual Voxel Assignment Strategy: Dynamically links ground-truth objects to virtual voxels during training, enabling precise localization and classification without rule-based matching.
Together, these components replicate the functional benefits of FSDv1’s clustering—but with greater flexibility, fewer assumptions, and improved generalization across datasets.
Proven Performance Across Real-World Benchmarks
FSD V2 has been rigorously evaluated on three large-scale autonomous driving datasets:
- Waymo Open Dataset
- nuScenes
- Argoverse 2
In all cases, FSD V2 achieves state-of-the-art performance among fully sparse detectors. Notably, it excels in long-range detection—a critical requirement for high-speed autonomous vehicles—where sparse point density makes object recognition especially challenging. The consistent results across diverse sensor configurations and scene types underscore its general applicability, making it a reliable choice for real-world deployment.
Practical Advantages for Engineering Teams
Beyond raw performance, FSD V2 offers tangible engineering benefits:
- Reduced code complexity: No custom clustering modules or heuristic thresholds to maintain.
- Easier integration: Built on MMDetection3D, a widely adopted 3D detection framework, lowering the onboarding barrier for teams already familiar with standard 3D pipelines.
- Open-source and reproducible: The full implementation is publicly available at https://github.com/tusen-ai/SST, with pre-configured support for Waymo, nuScenes, and Argoverse 2.
This combination of simplicity, performance, and tooling support makes FSD V2 particularly attractive for teams balancing R&D velocity with production readiness.
When to Choose FSD V2—And When Not To
FSD V2 is an excellent fit if your project involves:
- LiDAR-only 3D object detection (e.g., in autonomous ground vehicles, warehouse robots, or aerial drones).
- A need for high accuracy at long ranges with limited computational resources.
- A preference for sparse, efficient architectures that avoid dense voxelization.
However, note that FSD V2 is not designed for:
- Camera-based or multimodal (LiDAR + camera) perception—its input is raw LiDAR point clouds only.
- Scenarios without labeled LiDAR training data; like most deep learning detectors, it requires annotated 3D bounding boxes.
- Environments with severely constrained GPU memory; while efficient, it still follows modern 3D detector resource requirements.
Users should have basic familiarity with 3D deep learning workflows (e.g., point cloud preprocessing, training on large-scale datasets) to get the most out of the framework.
Summary
FSD V2 redefines what’s possible in fully sparse 3D object detection by replacing handcrafted design with a learnable, general-purpose mechanism—virtual voxels. It delivers top-tier accuracy across major benchmarks, simplifies system architecture, and addresses long-standing challenges like center feature missing. For technical teams building scalable, real-world 3D perception systems, FSD V2 offers a compelling blend of performance, robustness, and engineering practicality. With its open-source release and compatibility with standard toolchains, it’s ready for adoption in both research and production settings.