Fast FullSubNet addresses a critical challenge in modern audio applications: delivering high-quality, real-time speech enhancement on devices with strict constraints on latency, power, and computational resources. As voice-enabled interfaces become ubiquitous—from mobile conferencing apps to hearing aids and smart IoT devices—engineers and developers need speech enhancement models that don’t just perform well in labs, but also run efficiently in the real world.
Originally introduced as FullSubNet, the model already demonstrated state-of-the-art performance in single-channel speech enhancement, particularly on benchmarks like the Deep Noise Suppression (DNS) Challenge. However, its computational demands remained a barrier for deployment on battery-powered or latency-sensitive platforms. Fast FullSubNet directly tackles this limitation by re-engineering the architecture for speed without sacrificing audio fidelity.
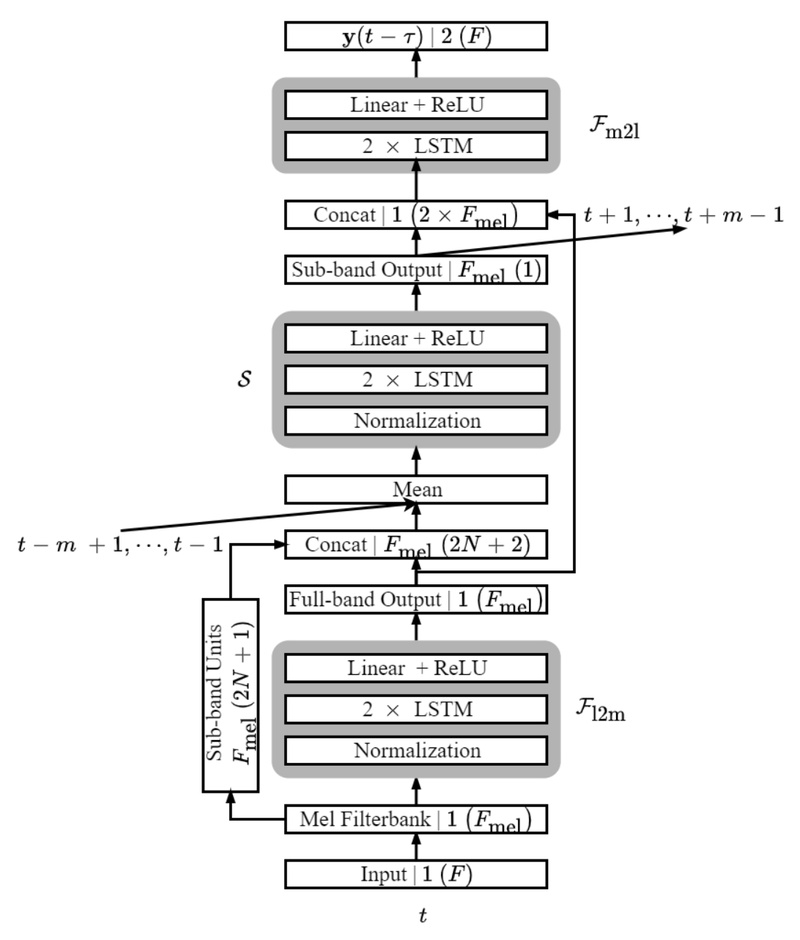
Built on the same foundational principles of full-band and sub-band fusion, Fast FullSubNet introduces two key innovations:
- Mel-frequency domain processing for sub-band spectra, drastically reducing the number of frequency bins involved in computation.
- Temporal down-sampling of the sub-band input sequence, cutting down operations along the time axis.
The result? A model that retains the robust noise suppression capabilities of its predecessor while operating at just 13% of the computational complexity and 16% of the processing time—a dramatic efficiency gain that makes real-time deployment on edge hardware not only feasible but practical.
Why Fast FullSubNet Matters for Real-World Applications
Traditional speech enhancement models often prioritize audio quality over efficiency, assuming access to powerful servers or GPUs. But in mobile, embedded, or wearable contexts, every millisecond of latency and every milliwatt of power counts. Fast FullSubNet was explicitly designed for these scenarios.
Consider a video conferencing app on a smartphone: background noise from a coffee shop, keyboard clatter, or street traffic can severely degrade call quality. Applying a heavy neural model might clean the audio, but if it introduces noticeable delay or drains the battery, users will disable it. Fast FullSubNet strikes the right balance—it processes audio in real time, consumes minimal power, and delivers clean, intelligible speech that meets or exceeds the quality of slower alternatives.
This makes it especially valuable for:
- Voice assistants on mobile or embedded devices
- Real-time transcription systems running on laptops or edge servers
- Hearing aid prototypes requiring low-latency, continuous audio processing
- IoT audio sensors in smart homes or industrial settings
By optimizing for both speed and performance, Fast FullSubNet empowers developers to integrate professional-grade speech enhancement without compromising user experience.
Key Technical Advantages
Fast FullSubNet’s architecture builds on three cascaded components:
- A linear-to-mel full-band model that converts raw frequency spectra into a perceptually relevant mel scale
- A sub-band model operating in the compressed mel domain, where far fewer frequency channels need processing
- A mel-to-linear full-band model that reconstructs the enhanced full-band spectrum
This design reduces the dimensionality of sub-band computations by leveraging the mel scale’s natural alignment with human auditory perception—focusing resources where they matter most.
Furthermore, the introduction of temporal down-sampling in the sub-band path shortens the sequence length processed by recurrent or attention-based modules, significantly lowering FLOPs and memory bandwidth requirements.
Benchmark results confirm that these changes don’t come at the cost of quality. On standard DNS test sets, Fast FullSubNet achieves comparable or even better speech quality metrics (e.g., PESQ, STOI) than the original FullSubNet, despite its drastic reduction in computation.
For engineers evaluating speech enhancement backends, this means you can deploy a model that’s not just “lightweight,” but production-ready for latency-critical pipelines.
Getting Started with Integration
The Fast FullSubNet implementation is publicly available in the FullSubNet GitHub repository under the permissive MIT license—ideal for both research and commercial use.
The repository includes:
- Pre-trained model checkpoints for Fast FullSubNet, ready for inference
- Audio demos showcasing enhancement performance across various noise conditions
- Comprehensive documentation (hosted on Read the Docs) covering installation, inference, and training workflows
Notably, the improved variants—including Fast FullSubNet—support high sampling rates such as 24 kHz and 48 kHz, making them suitable for professional audio applications beyond narrowband telephony.
To integrate Fast FullSubNet into your application:
- Clone the repository and install dependencies (primarily PyTorch and audio processing libraries)
- Load the provided checkpoint for Fast FullSubNet
- Run inference on single-channel noisy audio using the provided scripts
- Optionally, fine-tune the model on domain-specific data using the training pipeline
The codebase is modular and well-documented, enabling rapid prototyping and deployment—whether you’re building a mobile app, an embedded audio processor, or a real-time communication backend.
Limitations and Practical Considerations
While Fast FullSubNet excels in its target domain, it’s important to understand its scope:
- Single-channel only: It is designed for one-microphone inputs. Multi-microphone or beamforming scenarios require different architectures.
- Speech-focused: The model optimizes for human speech enhancement. It may not perform as well on non-speech audio like music or environmental sound separation.
- Hardware baseline: Although highly efficient, it still assumes a modest compute platform (e.g., a modern smartphone SoC or edge AI accelerator). Deployment on ultra-low-power microcontrollers (e.g., Cortex-M series without NPUs) would likely require additional quantization or model pruning beyond what’s provided.
These constraints are not weaknesses but design choices—Fast FullSubNet prioritizes real-time speech clarity under realistic edge conditions, and it succeeds decisively in that mission.
Summary
Fast FullSubNet delivers what many speech enhancement models promise but few achieve: high-quality noise suppression with real-time speed and low power consumption. By rethinking sub-band processing through mel-frequency representation and temporal down-sampling, it slashes computational demands while preserving—or even improving—audio quality.
For developers building voice-centric applications on resource-constrained devices, Fast FullSubNet offers a rare combination of performance, efficiency, and ease of integration. With open-source code, pre-trained models, and support for high sampling rates, it lowers the barrier to deploying professional-grade speech enhancement in production systems.
If your project demands clean, real-time speech from noisy environments—and you can’t afford latency or battery drain—Fast FullSubNet is a compelling, battle-tested solution worth adopting today.