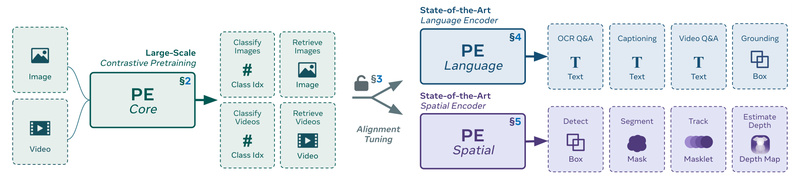
Perception Encoder (PE) redefines what’s possible with a single vision encoder. Unlike legacy approaches that demand different pretraining strategies for classification, captioning, or detection, PE demonstrates that one unified contrastive vision-language pretraining recipe—scaled thoughtfully and refined with high-quality video data—can power state-of-the-art performance across an astonishingly wide range of computer vision and multimodal tasks.
The secret? The best visual representations aren’t found at the network’s final output. They’re hidden in intermediate layers. PE unlocks them through two simple but powerful alignment techniques: language alignment for multimodal understanding and spatial alignment for pixel-level perception. The result is a family of models that dominate benchmarks in zero-shot classification, video QA, object detection, depth estimation, and more—without architectural switching or task-specific fine-tuning.
For project leads, researchers, and engineers building real-world vision systems, PE offers unprecedented flexibility, performance, and simplicity from a single codebase and training paradigm.
The Core Insight: Embeddings Live in the Middle
Traditional vision encoders assume the final-layer features are most useful. PE challenges this dogma. Through extensive scaling experiments, the team behind PE discovered that intermediate-layer embeddings, when properly aligned, consistently outperform output-layer features on diverse downstream tasks.
This insight eliminates the need for multiple specialized models. Instead of training separate backbones for retrieval, QA, or segmentation, you start with one PE model and extract the right layer for your use case via alignment:
- Language alignment projects intermediate features into a space compatible with large language models (LLMs), enabling strong multimodal QA and reasoning.
- Spatial alignment preserves fine-grained geometric structure, making features suitable for dense prediction like object detection or depth maps.
This layer-aware design is what allows PE to deliver top results across seemingly incompatible domains—zero-shot video classification and COCO detection—using the same base architecture and pretraining objective.
Three Flavors, One Foundation
PE isn’t a single model—it’s a coherent family built from the same contrastively pretrained backbone but optimized for distinct application needs through alignment and distillation:
PE-Core: Zero-Shot Powerhouse for Retrieval & Classification
PE-Core excels at open-ended image and video understanding without fine-tuning. It sets new records in zero-shot settings:
- 86.6 average robustness on ImageNet variants (IN-1k, IN-v2, IN-A, ObjectNet)
- 76.9 accuracy on Kinetics-400 video classification
- Strong performance on cross-modal retrieval (COCO-T2I, VTT-T2V)
Use PE-Core when you need plug-and-play features for search, filtering, or initial semantic triaging of visual content.
PE-Lang: The Multimodal LLM’s Best Friend
Paired with an LLM like PerceptionLM (PLM), PE-Lang enables world-class visual question answering:
- 94.6 on DocVQA (test)
- 80.9 on InfographicVQA (test)
- 82.7 on PerceptionTest (test) with an 8B LLM
These models are tiling-aware—meaning they handle high-resolution inputs (e.g., full-page documents or infographics) by intelligently splitting and reassembling visual context. If your application involves understanding charts, forms, or multi-panel visuals, PE-Lang is purpose-built for this.
PE-Spatial: Pixel-Precise Perception
For tasks demanding spatial fidelity—object detection, instance segmentation, tracking, depth estimation—PE-Spatial leads the pack:
- 66.0 box mAP on COCO, a new state of the art
- 61.5 J&F score on DAVIS tracking
- Strong linear-probe performance on ADE20K segmentation
This variant retains high-resolution spatial tokens through modified attention pathways, making it ideal for robotics, AR/VR, autonomous systems, or any application where where matters as much as what.
Ideal Use Cases for Practitioners
PE shines in scenarios where diverse visual understanding capabilities must be deployed efficiently:
- Enterprise search systems: Use PE-Core to build zero-shot image/video retrieval across internal media libraries without labeled data.
- Document intelligence platforms: Combine PE-Lang with an LLM to answer complex questions over scanned forms, manuals, or financial reports.
- Perception stacks for embodied AI: Deploy PE-Spatial in drones, robots, or AR glasses for real-time detection, depth sensing, and tracking.
- Multimodal content moderation: Leverage robust zero-shot classification to flag unsafe or out-of-policy visual content across images and videos.
- Foundational research: Start from PE’s open checkpoints and datasets (including 1M high-quality videos in PVD) to prototype new vision-language ideas without pretraining from scratch.
Because all PE variants share the same core architecture and pretraining, switching between them requires minimal code changes—just load a different checkpoint and alignment head.
Getting Started in Minutes
PE is designed for immediate adoption. Official integrations with Hugging Face Transformers and timm mean you can load models with familiar APIs.
Here’s a minimal example using PE-Core for zero-shot classification:
import torch
from PIL import Image
import core.vision_encoder.pe as pe
import core.vision_encoder.transforms as transforms
model = pe.CLIP.from_config("PE-Core-L14-336", pretrained=True).cuda()
preprocess = transforms.get_image_transform(model.image_size)
tokenizer = transforms.get_text_tokenizer(model.context_length)
image = preprocess(Image.open("cat.jpg")).unsqueeze(0).cuda()
text = tokenizer(["a diagram", "a dog", "a cat"]).cuda()
with torch.no_grad(), torch.autocast("cuda"):image_features, text_features, logit_scale = model(image, text)probs = (logit_scale * image_features @ text_features.T).softmax(dim=-1)
print("Label probabilities:", probs) # e.g., [[0.0, 0.0, 1.0]]
Colab demos, fine-tuning scripts, and evaluation tooling (via lmms-eval) are included in the repository, lowering the barrier to experimentation and production deployment.
Limitations and Practical Notes
While PE is remarkably versatile, consider these real-world constraints:
- Resolution matters: PE-Lang checkpoints labeled “Tiling” (e.g.,
PE-Lang-G14-448-Tiling) must be used when processing inputs larger than 448px with tiling—otherwise, performance degrades. - Hardware demands: Larger models (G/14, 8B LLM pairings) require significant GPU memory; distilled variants (T/16, S/16) offer lighter alternatives.
- Layer selection is key: Simply using the final output layer misses PE’s advantage. Always use the provided alignment modules or select intermediate layers as specified in the model card.
- Video processing: Requires
torchcodecfor efficient decoding, adding a dependency not needed for pure image tasks.
These are manageable trade-offs given the breadth of capabilities PE consolidates into one framework.
Summary
Perception Encoder proves that simplicity, when scaled correctly, can outperform specialization. By revealing that optimal visual embeddings reside in intermediate layers—and providing practical methods to extract them—PE delivers state-of-the-art results across zero-shot classification, multimodal QA, and dense vision tasks from a single contrastive pretraining pipeline.
For teams tired of maintaining disparate vision backbones or struggling to adapt models across tasks, PE offers a unified, open, and production-ready solution. With models, code, and datasets fully released, it’s never been easier to integrate cutting-edge perception into your next project.