Overview
Deploying powerful computer vision models on resource-constrained devices—such as smartphones, IoT sensors, or drones—has long been a major engineering bottleneck. Traditional convolutional neural networks (CNNs) often demand significant memory bandwidth, computational cycles, and power, making them impractical for real-world edge applications. GhostNet directly addresses this pain point by delivering near state-of-the-art accuracy at a fraction of the computational cost, enabling teams to ship high-performance vision features without compromising on latency, battery life, or hardware requirements.
What Problem Does GhostNet Solve?
Many successful CNNs implicitly rely on redundant feature maps—similar patterns repeated across channels—to achieve strong performance. However, standard architectures generate all these features through expensive convolutional operations, even when much of the information could be derived more cheaply. GhostNet challenges this inefficiency by introducing the Ghost module, a lightweight building block that creates “ghost” feature maps using simple, linear transformations (like depthwise convolutions or channel shuffling) instead of full convolutions.
This insight leads to a dramatic reduction in parameters and FLOPs while preserving representational richness. For example, on the ImageNet ILSVRC-2012 benchmark, GhostNet achieves 75.7% top-1 accuracy—surpassing MobileNetV3—despite having a comparable computational footprint. This makes it an ideal candidate for teams needing mobile- or embedded-friendly models that don’t sacrifice predictive quality.
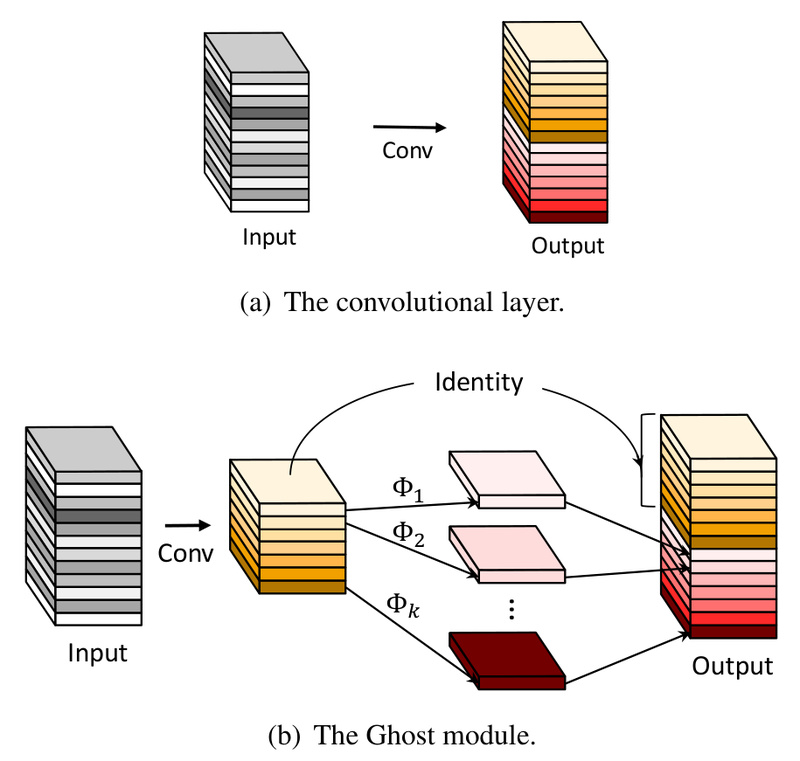
Core Innovation: The Ghost Module
At the heart of GhostNet lies the Ghost module. Rather than computing every output channel via a standard convolution, the module first produces a small set of “intrinsic” feature maps using a regular (but reduced) convolution. It then applies a series of cheap, fixed linear operations—such as depthwise convolutions with different kernels—to generate additional “ghost” channels that capture complementary information.
Because these transformations are computationally inexpensive and require no additional learnable parameters (beyond the initial intrinsic set), the module drastically cuts down on both model size and inference latency. Importantly, the Ghost module is designed as a drop-in replacement for standard convolution layers, meaning it can be integrated into existing architectures with minimal engineering effort.
Real-World Use Cases
GhostNet excels in scenarios where efficiency and accuracy must coexist under tight hardware constraints:
- Mobile vision apps: Real-time image classification, object detection backbones, or visual search in consumer apps.
- Smart cameras and edge sensors: Low-power surveillance or industrial inspection systems that process frames locally without cloud dependency.
- Augmented reality (AR) and wearables: On-device inference for AR glasses or headsets where thermal and battery budgets are extremely limited.
- Rapid prototyping: Teams exploring lightweight baselines for new vision products can quickly validate ideas using GhostNet’s pre-trained checkpoints.
Getting Started with GhostNet
Adopting GhostNet in your project is straightforward. The official implementation from Huawei Noah’s Ark Lab is available in both PyTorch and MindSpore, with clean, well-documented code and pre-trained weights for ImageNet. You can:
- Use the provided
ghostnet_pytorchmodule as a direct backbone replacement in your training or inference pipeline. - Fine-tune the model on custom datasets thanks to its strong transfer learning capabilities.
- Extend the architecture by stacking Ghost bottlenecks—structured blocks that combine Ghost modules with standard residual design patterns.
The GitHub repository also includes variants like GhostNetV2 (which adds long-range attention via cheap operations) and G-GhostNet (optimized for heterogeneous hardware), giving you options as your deployment needs evolve.
Limitations and Practical Considerations
While GhostNet is highly efficient for image classification, it was not originally designed for dense prediction tasks like semantic segmentation or depth estimation. Adapting it for such use cases may require architectural modifications (e.g., integrating Ghost modules into U-Net-style decoders).
Additionally, although GhostNet reduces FLOPs and parameters significantly, peak accuracy still lags behind large models like ResNet-152 or ViT-Large—though those models are often infeasible on edge devices anyway. For ultra-low-power targets (e.g., microcontrollers), further quantization or pruning may be necessary beyond what GhostNet provides out of the box.
That said, for the vast majority of edge vision applications where latency, model size, and power are critical, GhostNet strikes one of the best-known trade-offs between efficiency and performance.
Summary
GhostNet isn’t just another lightweight CNN—it’s a production-proven, CVPR 2020 Most Influential Paper that rethinks how features should be generated in resource-aware settings. By replacing expensive convolutions with intelligently crafted cheap operations, it delivers MobileNetV3-beating accuracy with even better hardware-friendly properties. With official support, active maintenance, and evolved variants like GhostNetV2, it remains a top-tier choice for engineers building the next generation of on-device vision systems.