MobileVLM is a purpose-built vision-language model (VLM) engineered from the ground up for on-device deployment on smartphones and edge hardware. Unlike bulky cloud-dependent multimodal models, MobileVLM delivers competitive accuracy while achieving state-of-the-art inference speeds—21.5 tokens per second on a Qualcomm Snapdragon 888 CPU and 65.3 tokens per second on an NVIDIA Jetson Orin GPU. With model variants ranging from 1.7B to 3B parameters (and a stronger 7B version in the V2 series), it demonstrates performance on par with or better than models several times its size, all while prioritizing efficiency, low latency, and privacy.
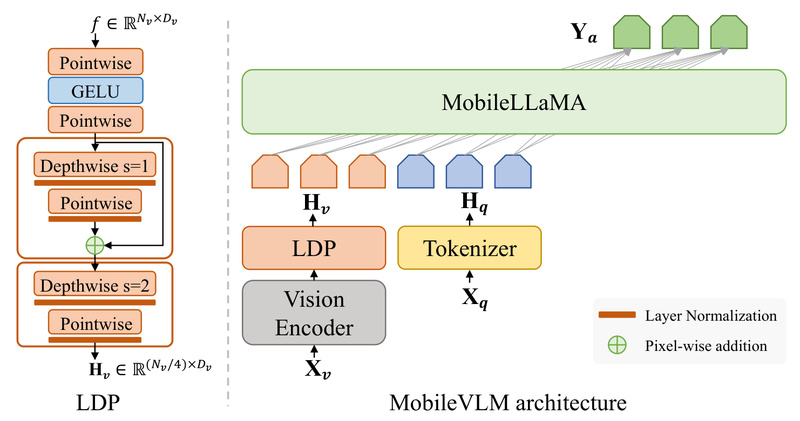
Developed by Meituan’s AutoML team, MobileVLM uses a lightweight architecture combining a custom MobileLLaMA language backbone, a CLIP-style vision encoder, and an efficient “Lightweight Downsample Projector” (LDP/LDPv2) to fuse visual and textual information with minimal overhead. Both the original MobileVLM and its improved successor, MobileVLM V2, are open-sourced under the Apache 2.0 license, with ready-to-use weights on Hugging Face and full compatibility with llama.cpp for C++ mobile deployment.
Why MobileVLM Stands Out for Mobile-Centric Applications
Speed Without Sacrificing Capability
MobileVLM redefines what’s possible on mobile hardware. In benchmark evaluations—including GQA, MMBench, MME, POPE, ScienceQA, and TextVQA—MobileVLM V2 1.7B matches or surpasses 3B-scale VLMs, while the MobileVLM V2 3B model outperforms many 7B+ competitors. This efficiency stems from a co-design philosophy: every architectural decision (from quantization-aware training to grouped-query attention) optimizes for real-world mobile inference rather than just academic metrics.
Built for Real Devices, Not Just Benchmarks
The project includes verified deployment paths on actual mobile SoCs. Thanks to its integration with llama.cpp, MobileVLM can run natively on Android and iOS without cloud roundtrips. This makes it ideal for applications requiring instant responsiveness, consistent offline operation, or compliance with data privacy regulations.
Key Use Cases Where MobileVLM Excels
On-Device Visual Question Answering (VQA)
Imagine a user pointing their phone camera at a book cover and asking, “Who wrote this?” MobileVLM can analyze the image and generate a concise answer like “J.K. Rowling” entirely on-device. This capability powers smart assistants that work without internet—critical in areas with poor connectivity or for enterprise tools handling sensitive visual data.
Real-Time Image Captioning and Scene Understanding
Mobile apps for accessibility, travel, or e-commerce can leverage MobileVLM to describe scenes, products, or street signs in real time. For example, a retail app could identify a product on a shelf and retrieve pricing or reviews—all processed locally to protect user behavior data.
Field Service and Industrial Mobile Tools
Technicians in remote locations can use MobileVLM to interpret equipment labels, schematics, or error messages from photos, reducing reliance on centralized servers and enabling faster troubleshooting.
Solving Real Pain Points for Product and Engineering Teams
Eliminating Cloud Dependency and Latency
Traditional VLMs require sending images to the cloud, introducing delays, data costs, and reliability risks. MobileVLM keeps inference entirely on-device, enabling sub-second responses even in offline scenarios.
Preserving User Privacy
By never transmitting images off the device, MobileVLM helps teams comply with GDPR, HIPAA, or internal data governance policies—especially valuable in healthcare, finance, and education apps.
Reducing Infrastructure Costs
Running inference on-device removes the need for scalable GPU backend services, significantly lowering operational expenses for consumer-facing applications at scale.
Getting Started: Simple Integration in Minutes
MobileVLM is designed for rapid adoption. Developers can begin with just a few steps:
-
Clone the repository:
git clone https://github.com/Meituan-AutoML/MobileVLM.git cd MobileVLM
-
Set up the environment:
conda create -n mobilevlm python=3.10 -y conda activate mobilevlm pip install -r requirements.txt
-
Run inference with pre-trained weights:
from scripts.inference import inference_once args = type('Args', (), {"model_path": "mtgv/MobileVLM_V2-1.7B","image_file": "assets/samples/demo.jpg","prompt": "What is the title of this book?","conv_mode": "v1","temperature": 0,"max_new_tokens": 64,"load_8bit": False, })() inference_once(args)
For mobile deployment, the team provides customized llama.cpp support, enabling integration into native iOS or Android apps via C/C++ bindings—no Python runtime required.
Limitations and Practical Considerations
While MobileVLM is highly optimized, adopters should note:
- Hardware Requirements: Although efficient, the 1.7B and 3B variants still require devices with at least 6–8 GB RAM for smooth operation. Ultra-low-end phones may struggle without quantization (4-bit/8-bit modes are supported but may slightly reduce accuracy).
- Task Scope: MobileVLM is specialized for vision-language tasks—not a general-purpose language model. It excels at image-conditioned reasoning but isn’t suited for pure text generation without visual context.
- Licensing Compliance: The model leverages datasets like COCO, LAION, and TextVQA. Users must adhere to the original licenses of these data sources.
- Accuracy Trade-offs: While MobileVLM V2 rivals 7B+ models on many benchmarks, the absolute peak performance on niche tasks may still favor larger cloud-based VLMs. The trade-off is intentional: speed and privacy over marginal accuracy gains.
Summary
MobileVLM delivers a rare combination: strong multimodal understanding, fast on-device inference, and open, production-ready tooling. For technical decision-makers building mobile AI applications—from consumer apps to enterprise tools—it offers a viable path to deploy intelligent vision-language features without sacrificing speed, privacy, or cost efficiency. With full training recipes, Hugging Face integration, and llama.cpp support, MobileVLM lowers the barrier to bringing cutting-edge multimodal AI directly into users’ hands.