In today’s AI-driven product landscape, the ability to understand both images and text isn’t just a research novelty—it’s a practical necessity. From customer support bots that interpret uploaded screenshots to internal tools that extract insights from charts and documents, multimodal intelligence is becoming essential. Enter mPLUG-Owl, a family of open-source multimodal large language models (MLLMs) that brings robust vision-language understanding to real-world applications—without requiring teams to reinvent the wheel.
What sets mPLUG-Owl apart isn’t just its performance, but its modular architecture, which enables flexibility, easier integration, and better maintainability compared to monolithic alternatives. Whether you’re building a visual QA system, an educational assistant that explains diagrams, or a document analysis pipeline, mPLUG-Owl offers a practical, research-backed foundation that balances capability with deployability.
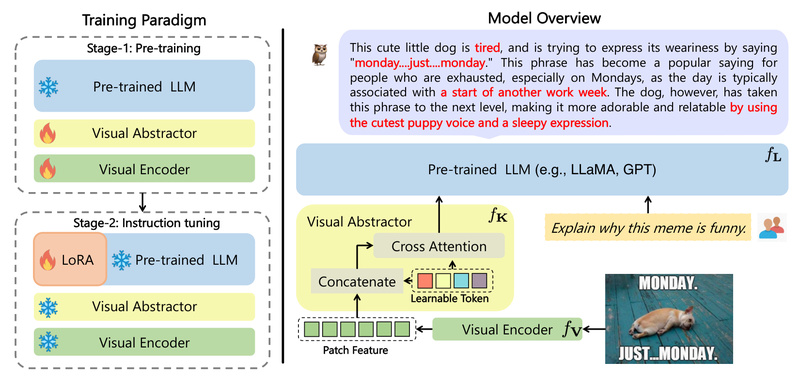
Modular Design for Practical Integration
Unlike many end-to-end multimodal models that tightly couple vision and language components, mPLUG-Owl adopts a three-module training paradigm:
- A foundation large language model (LLM)—kept frozen during early training to preserve linguistic reasoning.
- A visual knowledge module—trained to encode image semantics.
- A visual abstractor module—responsible for bridging visual features into the LLM’s language space.
This modular approach has significant engineering advantages:
- Easier customization: Teams can swap or fine-tune individual modules (e.g., using a different LLM backbone) without retraining the entire system.
- Lower resource overhead: The two-stage training process first aligns vision and language with a frozen LLM, then uses low-rank adaptation (LoRA) for efficient fine-tuning—reducing GPU memory demands.
- Maintained language proficiency: By freezing the core LLM early on, mPLUG-Owl avoids the common pitfall of degrading text-only performance when adding multimodal capabilities.
For technical decision-makers, this means faster prototyping, smoother deployment, and clearer upgrade paths as new LLMs or vision encoders emerge.
Capabilities That Address Real Industry Needs
mPLUG-Owl isn’t just theoretically sound—it demonstrates concrete, actionable strengths validated through both benchmarks and qualitative evaluation:
- Strong instruction following: Accurately responds to complex, open-ended prompts involving images (e.g., “Describe the trend shown in this chart and suggest possible causes”).
- Multi-turn multimodal conversation: Maintains context across dialogue turns, enabling chat assistants that handle image uploads naturally.
- Scene text understanding: Recognizes and reasons about text within images—critical for receipts, signage, or document screenshots.
- Multi-image correlation: Can compare or reason across multiple images, useful for visual change detection or side-by-side product comparisons.
- Vision-only document comprehension: Surprisingly, it can interpret figures, tables, and layouts without accompanying text, opening doors for automating report analysis or technical diagram parsing.
These capabilities directly address common pain points: reducing manual review of visual content, enabling richer user interactions, and automating knowledge extraction from multimodal enterprise data.
Where mPLUG-Owl Fits in Your Tech Stack
mPLUG-Owl is particularly well-suited for teams that need production-ready multimodal intelligence without massive infrastructure investments. Consider these use cases:
- Customer support automation: Users upload error screenshots or product images, and the system diagnoses issues or retrieves relevant FAQs.
- Educational technology: An AI tutor explains scientific diagrams, historical maps, or math problem visuals in conversational form.
- Enterprise knowledge assistants: Internal bots that answer questions about presentations, spreadsheets, or engineering schematics by “reading” embedded visuals.
- Rapid prototyping: Startups or research teams can quickly validate multimodal feature ideas using the open-source models and instruction-tuned variants—no need to wait for proprietary APIs.
With pretrained and instruction-tuned models available, plus an online demo on ModelScope, evaluation is frictionless.
Getting Started Without Deep Research Expertise
You don’t need to be a multimodal AI specialist to try mPLUG-Owl:
- The source code, model weights, and OwlEval benchmark are publicly available on GitHub.
- Pretrained and instruction-finetuned versions support immediate experimentation.
- The two-stage training design means you can adapt the model to your domain using LoRA, which is far more efficient than full fine-tuning.
This lowers the barrier for engineers and product teams to integrate vision-language capabilities into existing workflows—whether for internal tools or customer-facing features.
Current Limitations and Practical Considerations
While powerful, mPLUG-Owl isn’t a magic bullet. Be mindful of these considerations:
- Fine-tuning still requires effort: Although LoRA reduces computational cost, domain adaptation isn’t zero-shot. You’ll need labeled multimodal data for best results.
- Performance may lag behind closed, larger models: As an open-source solution, it trades some raw capability for transparency and flexibility. Always benchmark against your specific tasks using tools like OwlEval.
- Multimodal hallucination risks: Like all MLLMs, it may generate plausible but incorrect interpretations of ambiguous images—critical applications should include verification layers.
These aren’t dealbreakers, but rather guideposts for responsible deployment.
Summary
mPLUG-Owl delivers a rare combination: strong multimodal reasoning, modular design for real-world engineering, and open accessibility. For technical leaders evaluating vision-language solutions, it offers a credible, customizable, and cost-effective path to embedding multimodal intelligence into products—without sacrificing maintainability or language proficiency. If your work involves making sense of images and text together, mPLUG-Owl deserves a serious look.