Traditional spoken dialogue systems—like those used in virtual assistants or customer service bots—rely on a cascade of disconnected components: voice activity detection, automatic speech recognition (ASR), a text-based language model, and text-to-speech (TTS). This pipeline approach introduces multiple pain points: high latency (often several seconds), loss of non-linguistic meaning (such as emotion, sighs, or interjections), and rigid turn-taking that breaks down during natural overlaps or interruptions.
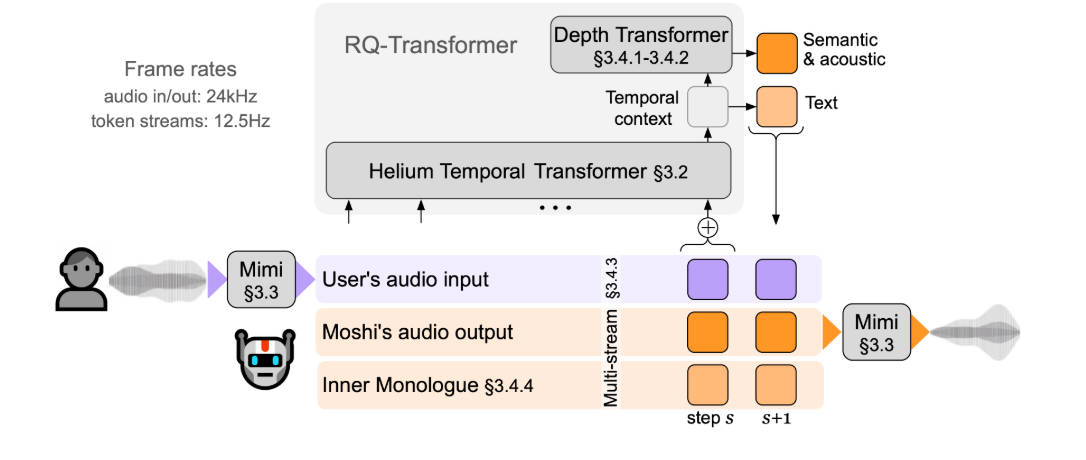
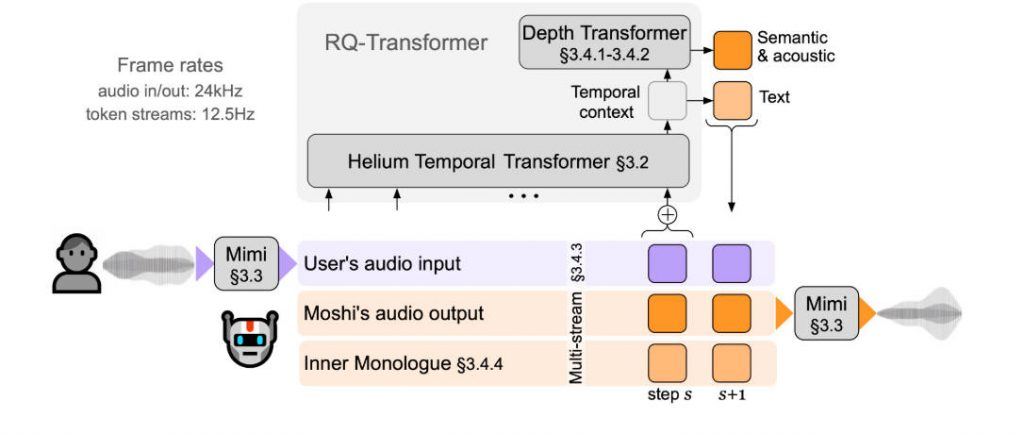
Moshi, developed by Kyutai Labs, reimagines spoken dialogue by treating it as a unified, speech-to-speech generation problem. Instead of shuttling between text and audio, Moshi operates directly on speech tokens while maintaining parallel streams for both the user’s voice and its own responses. The result is a real-time, full-duplex spoken dialogue system that mimics how humans actually converse—with fluid timing, expressive nuance, and minimal delay.
Built on a 7B-parameter Temporal Transformer and powered by Mimi—a state-of-the-art streaming neural audio codec—Moshi achieves a theoretical latency of just 160 milliseconds, and about 200ms in practice on modern hardware. This level of responsiveness makes it the first large spoken language model capable of truly interactive, natural-feeling conversation.
Why Moshi Solves the Core Problems of Spoken Dialogue
High Latency from Pipeline Architectures
Conventional systems require audio → text → dialogue → text → audio conversions. Each step adds measurable delay. Moshi eliminates intermediate text representations, generating speech tokens directly from its language model backbone. This end-to-end design slashes latency to under a quarter of a second—fast enough for real-time interaction.
Loss of Non-Linguistic Meaning
When dialogue is forced through a text-only bottleneck, subtle cues like tone, hesitation, or emotional inflection are discarded. Moshi preserves this information by modeling speech in its native form. Its neural audio codec, Mimi, encodes both semantic and acoustic details at just 1.1 kbps, enabling expressive, context-aware responses that go beyond mere words.
Inflexible Turn-Taking
Real conversations aren’t orderly exchanges; they involve overlaps, interruptions, and backchanneling (“uh-huh,” “yeah”). Traditional systems assume clean speaker segmentation, which fails in dynamic settings. Moshi’s dual-stream architecture—one for the user, one for itself—allows it to process and respond during speech, enabling true full-duplex interaction without artificial pauses.
“Inner Monologue” Enhances Both Generation and Understanding
A key innovation in Moshi is its “Inner Monologue” mechanism. While generating speech tokens, Moshi simultaneously predicts time-aligned text tokens representing what it intends to say. This internal textual stream serves two critical purposes:
- Improves Linguistic Quality: By grounding audio generation in coherent textual structure, Moshi avoids the garbled or off-topic outputs common in pure speech-to-speech models.
- Enables Built-in ASR and TTS: The inner monologue acts as real-time speech recognition for the model’s own output, while the parallel audio stream functions as integrated text-to-speech. No separate modules are needed.
This dual prediction—text + audio—makes Moshi not just a dialogue agent, but a unified speech foundation model capable of multiple tasks out of the box.
Real-Time Full-Duplex Interaction: Closer to Human Conversation
Moshi doesn’t wait for the user to finish speaking. It listens and responds continuously, just like a human interlocutor. This is made possible by:
- Streaming Audio Processing: Mimi processes audio in 80ms frames, enabling immediate encoding and decoding.
- Parallel User/Agent Streams: The model maintains separate but interacting representations of both participants, allowing context-aware responses even during overlapping speech.
- Low Autoregressive Steps: By aligning Mimi’s 12.5 Hz frame rate with typical speech token rates (~3–4 Hz), Moshi minimizes the number of generation steps per second, reducing computational load and latency.
For developers building voice assistants, telepresence robots, or collaborative AI teammates, this capability is transformative—enabling interactions that feel responsive, natural, and socially intelligent.
Flexible Deployment Across Research, Mobile, and Production
Moshi is designed for real-world adaptability, with three official implementations:
- PyTorch (
moshi/): Ideal for researchers and rapid prototyping. Requires a GPU with ≥24GB VRAM (due to lack of quantization support in this version). - MLX (
moshi_mlx/): Optimized for Apple Silicon (iPhone, Mac), supporting int4, int8, and bf16 quantization for efficient on-device inference. - Rust (
rust/): Built for production environments, with CUDA and Metal backends, and quantized (int8) models for scalable server deployment.
Each version includes the full inference stack—Mimi codec, language model, and streaming logic—so developers can move seamlessly from experimentation to deployment.
Practical Use Cases Where Moshi Excels
Moshi is especially well-suited for applications demanding low-latency, expressive, and continuous spoken interaction, such as:
- Real-time voice interfaces for AR/VR, automotive systems, or smart home devices.
- Multilingual or emotion-aware dialogue agents that retain paralinguistic nuance.
- Research in spoken language modeling, full-duplex interaction, or speech foundation models.
- Customer service bots that can handle interruptions and recover naturally from user digressions.
Because Moshi integrates ASR, dialogue, and TTS into a single model, it also simplifies system architecture—reducing engineering overhead and failure points.
Key Limitations and Requirements
While powerful, Moshi has practical constraints users should consider:
- The PyTorch version requires a high-memory GPU (24GB+) and lacks quantization.
- Windows support is not officially provided, though it may work experimentally.
- Web UI access requires HTTPS for microphone permissions; local HTTP connections may be blocked by browsers.
- Command-line clients lack echo cancellation, so audio quality may degrade in speaker-microphone setups without external processing.
- Fine-tuning requires separate repositories (e.g.,
kyutai-labs/moshi-finetune).
These limitations are primarily around deployment environment—not core functionality—and are actively addressed in the MLX and Rust backends.
Getting Started Quickly
Kyutai Labs provides pre-trained models for immediate experimentation:
- Moshiko: Male synthetic voice.
- Moshika: Female synthetic voice.
All models include the Mimi codec and are available in multiple quantization formats on Hugging Face.
To launch a local demo with PyTorch:
python -m moshi.server --hf-repo kyutai/moshika-pytorch-bf16
On a Mac with Apple Silicon:
python -m moshi_mlx.local -q 4 --hf-repo kyutai/moshika-mlx-q4
For production-grade inference with Rust:
cargo run --features cuda --bin moshi-backend -r -- --config moshi-backend/config-q8.json standalone
The web UI (with built-in echo cancellation) is served automatically at localhost:8998 and is the recommended way to experience Moshi’s full capabilities.
Summary
Moshi redefines what’s possible in spoken dialogue by replacing brittle, multi-stage pipelines with a unified, speech-native foundation model. Its full-duplex architecture, inner monologue mechanism, and sub-200ms latency enable conversations that are not just fast—but truly human-like. With cross-platform support from research (PyTorch) to mobile (MLX) to production (Rust), Moshi offers a practical path for developers and researchers to build the next generation of voice interfaces. If your project demands natural, responsive, and expressive spoken interaction, Moshi is worth serious consideration.