Building AI agents that can handle diverse, real-world tasks—and improve over time without hand-holding—is one of the biggest challenges in applied AI today. Most current approaches to LLM-based agents fall into two problematic categories: they either rely on expert-provided demonstration trajectories (which don’t scale and limit exploration), or they train agents in isolated, single-purpose environments (leading to brittle, task-specific behavior with poor generalization).
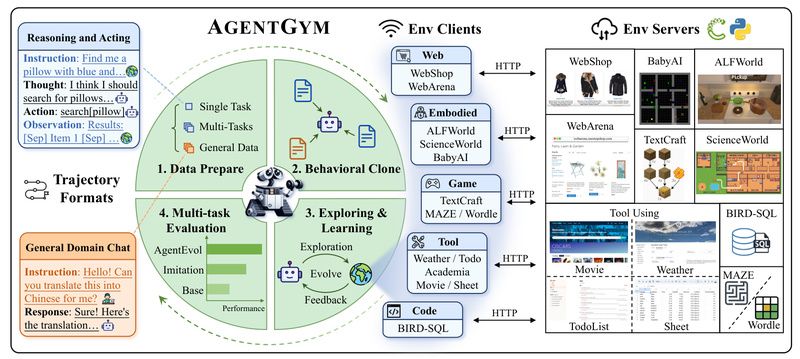
AgentGym directly addresses this gap. It’s a unified framework that enables large language model (LLM)-based agents to explore, learn, and evolve across a wide range of interactive environments—from web navigation and text-based games to tool use and SQL queries—using a consistent interface and minimal human intervention. By combining a standardized platform, high-quality training data, and a novel self-evolution method called AgentEvol, AgentGym empowers practitioners to develop truly generalist agents capable of long-horizon decision-making and cross-environment adaptation.
Why AgentGym Solves a Real Pain Point for Technical Teams
Traditional agent development pipelines often get stuck in the "expert bottleneck": scaling requires more human-labeled trajectories, which are expensive and slow to produce. On the other hand, reinforcement learning (RL) in isolated simulators yields agents that fail the moment they face a new interface or task structure.
AgentGym breaks this trade-off. It provides:
- Broad environmental diversity: 14 distinct, real-time environments covering web shops (WebShop), enterprise UIs (WebArena), embodied reasoning (ALFWorld, SciWorld), logic puzzles (Wordle, MAZE), and structured tool use (Weather, Movie, Sheet).
- Real interaction, not just imitation: Agents learn from actual environment feedback—not just static demonstrations—enabling discovery of novel strategies.
- Self-evolution beyond human data: Through AgentEvol, agents iteratively improve by generating and refining their own trajectories, then training on the best-performing ones—no new human labels needed.
This makes AgentGym especially valuable for teams building automation systems, evaluating agent robustness, or researching general-purpose AI that must operate across unpredictable digital contexts.
Core Components That Enable Scalable Agent Development
AgentGym is built on three foundational pillars:
1. A Unified, Concurrent Platform for Multi-Environment Interaction
All environments in AgentGym expose a consistent ReAct-style interface over HTTP, with standardized endpoints like /createEnv, /observation, /available_actions, /step, and /reset. This decoupled architecture allows:
- Real-time, concurrent evaluation across dozens of environments.
- Easy integration of new custom environments by implementing the same API.
- Seamless scaling for large experiments (e.g., parallel runs in WebArena).
Whether you’re testing an agent on navigating an e-commerce site or solving a chemistry lab puzzle in SciWorld, the interaction protocol remains the same—dramatically simplifying pipeline development.
2. AgentTraj-L: A High-Quality Trajectory Dataset for Warm Starts
AgentGym ships with AgentTraj-L, a curated dataset of over 14,000 high-quality trajectories spanning all 14 environments. Each trajectory follows the ReAct format with explicit “Thought” and “Action” steps, providing strong priors for behavioral cloning or as seed data for evolution. This eliminates the cold-start problem and accelerates training.
3. AgentEvol: A Scalable Self-Evolution Method
AgentEvol enables agents to improve autonomously:
- Generate new trajectories by interacting with environments.
- Score each trajectory based on task success.
- Retrain the agent on the top-performing trajectories.
Experiments show AgentEvol-trained agents (e.g., AgentEvol-7B) achieve performance comparable to state-of-the-art models—without new human demonstrations.
Practical Use Cases Where AgentGym Delivers Immediate Value
Enterprise Automation & Digital Workers
Need agents that can operate across internal tools (e.g., CRM, spreadsheets, email)? AgentGym’s tool-use environments (Sheet, TODOList, Movie) and web-based simulators (WebArena) provide realistic sandboxes for training general-purpose digital assistants.
Cross-Environment Generalization Research
For AI researchers studying how agents transfer skills between domains, AgentGym’s diverse suite—ranging from symbolic (BabyAI) to realistic (BIRD for SQL) tasks—offers a standardized testbed with the AgentEval benchmark.
Long-Horizon Decision-Making with AgentGym-RL
The newly released AgentGym-RL extension supports multi-turn reinforcement learning, making it ideal for training agents on complex, multi-step tasks where reward signals are sparse and delayed.
Rapid Prototyping & Agent Debugging
The built-in interactive frontend lets you replay full trajectories, step through agent reasoning, and inspect failures—critical for iterative improvement in real projects.
Getting Started: A Developer-Friendly Workflow
AgentGym is designed for quick adoption:
-
Install the core package:
pip install agentenv
Or clone the repo for full access to examples and environment servers.
-
Set up your target environments:
Each environment (e.g.,agentenv-webshop,agentenv-alfworld) runs as a separate service. Follow the README in each subdirectory to launch its backend. -
Run evaluations or training:
Use provided tutorials for:- Agent evaluation (
01-evaluation) - Behavioral cloning (
02-behavioral-cloning) - AgentEvol self-improvement (
03-AgentEvol) - Custom environment development (
05-2nd-Development)
- Agent evaluation (
-
Visualize and debug:
Leverage the interactive frontend to inspect agent decisions step-by-step—no more black-box debugging.
Limitations and Infrastructure Considerations
While powerful, AgentGym requires thoughtful deployment:
- Distributed setup: Each environment runs as an independent HTTP service, so you’ll need to manage multiple processes or containers.
- Environment-specific dependencies: Some simulators (e.g., WebArena, ALFWorld) have their own Python or system requirements.
- Compute intensity: Training with AgentEvol or AgentGym-RL demands GPU resources, especially for 7B+ parameter models.
- LLM-centric design: AgentGym assumes text-based LLM agents; multimodal inputs (e.g., raw images) are not natively supported unless the underlying environment handles them.
Ensure your team has the infrastructure to run concurrent environment servers before large-scale adoption.
Extending AgentGym for Custom Domains
One of AgentGym’s greatest strengths is extensibility. To add a proprietary environment (e.g., an internal SaaS tool):
- Implement the standard HTTP API (
/createEnv,/step, etc.). - Wrap your system’s actions and observations into the ReAct format.
- Register it with AgentGym’s
EnvClient.
Your new environment will instantly work with all evaluation, training, and visualization tools—enabling agent testing in your exact operational context.
Summary
AgentGym solves a critical problem in applied AI: how to build LLM agents that generalize across diverse, real-world environments without depending on endless human demonstrations. By unifying 14 interactive environments under a single interface, providing high-quality seed data, and enabling autonomous self-evolution via AgentEvol, it offers a practical, scalable path toward generalist agents. For technical decision-makers in automation, research, or enterprise AI, AgentGym lowers the barrier to developing, evaluating, and evolving capable agents that truly adapt over time.