Large language models (LLMs) are becoming increasingly central to real-world applications—but their computational demands remain a major barrier for edge deployment. Enter Bitnet.cpp, Microsoft’s official inference framework designed specifically for 1.58-bit (ternary) LLMs like BitNet b1.58. Built on the llama.cpp foundation, Bitnet.cpp delivers fast, lossless inference on commodity CPUs, making it a compelling choice for technical decision-makers who need to run powerful language models locally—without sacrificing speed, accuracy, or hardware compatibility.
Unlike conventional quantization approaches that trade accuracy for performance, Bitnet.cpp leverages the unique structure of ternary-weight models to achieve sub-2-bits-per-weight execution while preserving full model fidelity. This makes it uniquely suited for privacy-sensitive, bandwidth-constrained, or latency-critical scenarios where cloud-based inference isn’t viable.
Why Bitnet.cpp Matters for Technical Decision-Makers
As AI moves from data centers to devices—laptops, robots, embedded systems—the need for efficient on-device LLMs grows. Most low-bit inference frameworks either lose accuracy or require specialized hardware. Bitnet.cpp changes this equation by offering CPU-native support for true 1.58-bit models, with performance that outpaces both full-precision and other low-bit baselines.
Backed by peer-reviewed research and open-sourced by Microsoft, Bitnet.cpp isn’t a proof-of-concept—it’s a production-ready toolkit for deploying the next generation of ultra-efficient LLMs at the edge.
Core Innovations: How Bitnet.cpp Achieves Lossless Speed
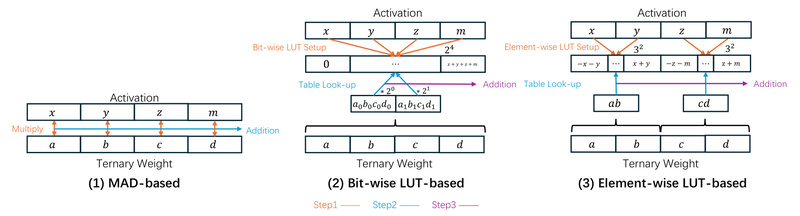
At the heart of Bitnet.cpp lies a custom mixed-precision GEMM (mpGEMM) library optimized for ternary weights. Two key kernel strategies power its efficiency:
Int2 with a Scale (I2_S)
This approach encodes ternary weights (−1, 0, +1) into int2 representation while preserving a per-channel scale factor. The result? Lossless inference—no approximation, no degradation—just faster matrix math using standard CPU instructions.
Ternary Lookup Table (TL)
Traditional bitwise methods suffer from poor memory locality and underutilized compute units. TL addresses this by precomputing common weight-activation interactions in a compact lookup table, dramatically improving spatial efficiency and throughput—especially on ARM and x86 architectures.
In benchmark tests, Bitnet.cpp achieves up to 6.25× speedup over full-precision models and 2.32× over existing low-bit inference systems—real gains validated on actual hardware like Apple M2 CPUs.
Ideal Use Cases
Bitnet.cpp excels in environments where locality, privacy, and efficiency are non-negotiable:
- On-device AI assistants: Run instruct-tuned models like Falcon3-1.58bit directly on user laptops without internet connectivity.
- Edge robotics and IoT: Deploy lightweight language understanding in power-constrained settings.
- Confidential data processing: Keep sensitive inputs (e.g., medical notes, legal documents) offline while still leveraging LLM capabilities.
- Rapid prototyping: Evaluate ternary LLM performance on standard developer hardware before committing to ASIC or NPU integration.
Because it targets CPUs, Bitnet.cpp runs on virtually any modern laptop or server—no CUDA, no cloud fees, no latency spikes.
Getting Started: A Practical Workflow
Bitnet.cpp is designed for hands-on practitioners. Here’s how to go from zero to inference in minutes:
-
Install dependencies: Python ≥3.9, CMake ≥3.22, and Clang ≥18 (or Visual Studio 2022 on Windows).
-
Clone the repository:
git clone --recursive -b paper https://github.com/microsoft/BitNet.git cd BitNet
-
Set up a conda environment and install requirements.
-
Download and convert a 1.58-bit model from Hugging Face:
python setup_env.py --hf-repo 1bitLLM/bitnet_b1_58-3B -q i2_s
Choose your quantization kernel (
i2_s,tl1, ortl2) based on your hardware and accuracy needs. -
Run inference:
python run_inference.py -m models/bitnet_b1_58-3B/ggml-model-i2_s.gguf -p "Explain quantum computing simply." -cnv
For benchmarking, use the provided e2e_benchmark.py script to measure tokens-per-second under various prompt and thread configurations.
Supported Models and Hardware
Bitnet.cpp currently supports community-trained 1.58-bit variants of:
- BitNet b1.58 (0.7B, 3B)
- Llama3-8B-1.58 (trained on 100B tokens)
- Falcon3 family (1B to 10B)
Both x86 and ARM CPUs are supported—including Apple Silicon—thanks to architecture-aware kernel tuning. Note that Microsoft does not release these models; they are provided by the open-source community to demonstrate Bitnet.cpp’s capabilities.
Limitations and Considerations
While powerful, Bitnet.cpp has clear boundaries:
- CPU-only today: GPU and NPU support is planned but not yet available.
- Ternary-specific: It’s optimized exclusively for 1.58-bit models (weights in {−1, 0, +1}). It does not support arbitrary quantization schemes like INT4 or FP8.
- Model compatibility: Only models structured for BitNet-style ternary weights work out of the box. Standard Llama or Mistral models must first be converted to a 1.58-bit variant.
Users should verify that their target model aligns with Bitnet.cpp’s kernel assumptions before integration.
Summary
Bitnet.cpp bridges the gap between theoretical 1-bit LLM research and real-world edge deployment. By delivering lossless, CPU-native inference with dramatic speedups, it enables technical teams to run state-of-the-art language models locally—securely, efficiently, and at scale. For anyone evaluating ultra-low-bit inference solutions, Bitnet.cpp offers a rare combination of academic rigor, open-source accessibility, and practical performance.