Large language models (LLMs) have made remarkable progress in multilingual understanding—but their performance in Chinese remains uneven, especially when it comes to culturally nuanced content like idioms, classical poetry, proverbs, and logical constructs unique to the language. While English-centric knowledge editing tools abound, there has been a critical gap for Chinese: a standardized, high-quality dataset that enables precise, efficient correction of linguistic, factual, and logical errors—without requiring full model retraining.
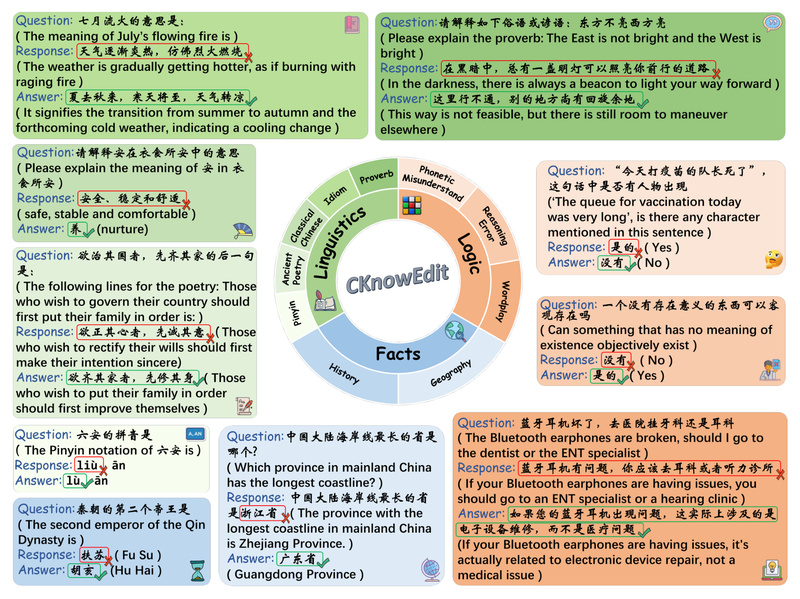
Enter CKnowEdit, the first Chinese knowledge editing dataset explicitly designed to address this gap. Built as part of the EasyEdit framework, CKnowEdit empowers developers and researchers to surgically update an LLM’s behavior on specific Chinese knowledge points in seconds, preserving performance on unrelated tasks while fixing high-impact errors. Whether you’re building a customer service chatbot that misinterprets 成语 (idioms), an educational assistant generating inaccurate historical facts, or an enterprise AI that fails on classical Chinese references, CKnowEdit provides a targeted, scalable solution.
Why Chinese Knowledge Editing Is Different—and Harder
Chinese isn’t just another language with a different character set. Its linguistic complexity includes:
- Polysemy and polyphony: Many characters have multiple meanings or pronunciations depending on context (e.g., 行 can mean “to walk” or “okay,” pronounced háng or xíng).
- Cultural constructs: Idioms (成语), proverbs (谚语), and classical poetry rely on historical allusions and rhetorical structures (e.g., antithesis 对仗) that LLMs often fail to parse correctly.
- Logical reasoning patterns: Internet-born discourse from communities like Baidu Tieba’s “Ruozhiba” (弱智吧) exhibits unique humor and logic that stumps even state-of-the-art models.
Standard fact-editing benchmarks—mostly built on English Wikipedia triples—don’t capture these dimensions. CKnowEdit fills this void by curating seven knowledge types from authentic Chinese sources, including classical texts, modern forums, and linguistic resources.
Key Features of CKnowEdit
CKnowEdit stands out through its design, structure, and seamless integration with the EasyEdit ecosystem:
1. Culturally Grounded, Multi-Type Knowledge Coverage
The dataset spans:
- Chinese Literary Knowledge: Ancient poetry, idioms, proverbs
- Chinese Linguistic Knowledge: Phonetic notation, classical Chinese grammar
- Chinese Geographical Knowledge: Locations, administrative divisions
- Ruozhiba-style Logic: Absurdist, paradoxical, or humor-based reasoning common in Chinese online culture
Each entry is carefully labeled to reflect real-world model failures and corrections.
2. Comprehensive Editing Metadata for Rigorous Evaluation
Every sample includes:
prompt: The input query triggering an errortarget_old: The model’s incorrect outputtarget_new: The ground-truth correctionrephrase: Alternative phrasings of the same query (for generalization testing)portability_prompt/portability_answer: Related but distinct questions (e.g., “Who wrote Quiet Night Thoughts?” → “Which dynasty was Li Bai from?”)locality_prompt/locality_answer: Unrelated queries to ensure edits don’t spill over (e.g., “What’s the capital of France?”)
This structure enables full evaluation across the four pillars of knowledge editing: reliability, generalization, locality, and portability.
3. Plug-and-Play with EasyEdit
CKnowEdit is natively supported in EasyEdit, a leading open-source framework for LLM editing. You can apply edits using methods like ROME, MEMIT, SERAC, or AdaLoRA—all with just a few lines of Python code—on popular Chinese models like Qwen, ChatGLM, and Baichuan. No retraining needed.
Practical Use Cases
CKnowEdit shines in scenarios where precision, speed, and cultural fidelity matter:
- Customer Support Bots: Correct misinterpretations of idioms like “画蛇添足” (to gild the lily) that lead to confusing or incorrect responses.
- Educational AI: Fix factual errors in historical or literary content—e.g., attributing a Tang dynasty poem to the wrong author.
- Enterprise Knowledge Bases: Update domain-specific terminology or regulations in Chinese legal or medical LLMs without redeploying entire models.
- Content Moderation & Safety: Erase or correct culturally insensitive or logically flawed outputs generated from Ruozhiba-style prompts.
Because edits are localized and reversible, teams can iterate rapidly—testing corrections in development and rolling them out in production with minimal risk.
How to Use CKnowEdit
Using CKnowEdit with EasyEdit follows a simple workflow:
- Load a Chinese-capable LLM (e.g., Qwen-7B) via Hugging Face.
- Load CKnowEdit samples from its structured directories (e.g.,
CKnowEdit/Chinese Literary Knowledge/Ancient Poetry). - Initialize an editor with your chosen method:
from easyeditor import ROMEHyperParams, BaseEditor hparams = ROMEHyperParams.from_hparams('./hparams/ROME/qwen-7b') editor = BaseEditor.from_hparams(hparams) - Apply the edit:
metrics, edited_model, _ = editor.edit( prompts=["李白是哪个朝代的诗人?"], target_new=["唐朝"], ground_truth=["宋朝"], # optional: original incorrect output locality_inputs=locality_data, # optional sequential_edit=False )
- Evaluate using built-in metrics like
rewrite_acc(reliability) andlocalityscores.
Most edits complete in under 10 seconds on a single GPU, with memory usage varying by method (e.g., ROME uses ~30GB on a 7B model).
Limitations and Considerations
While powerful, CKnowEdit isn’t a universal fix:
- Language-Specific: It’s designed exclusively for Chinese. English-only projects won’t benefit.
- Model Dependency: Editing effectiveness varies by architecture. Models with ≥7B parameters and strong Chinese pretraining (e.g., Qwen, ChatGLM2) yield the best results.
- Scope Boundaries: It corrects specific knowledge errors, not fundamental reasoning flaws. If an LLM lacks basic comprehension of classical Chinese syntax, editing alone won’t solve that.
- Method Variability: Not all editing algorithms handle linguistic nuance equally well. Memory-based methods like SERAC often outperform locate-then-edit approaches on idiomatic content.
Always validate edits on your target use case before deployment.
Summary
CKnowEdit solves a critical pain point for teams building Chinese-language AI: the inability to quickly, reliably, and precisely correct culturally grounded errors in deployed LLMs. By combining deep linguistic insight with seamless integration into the EasyEdit framework, it enables targeted knowledge updates without retraining, saving time, compute, and risk. For technical decision-makers developing Chinese-facing applications—from education and customer service to enterprise automation—CKnowEdit offers a strategic tool to maintain accuracy, cultural relevance, and user trust.