Imagine building an AI system that understands not just images and text—but also video, audio, infrared (thermal), and depth data—all…
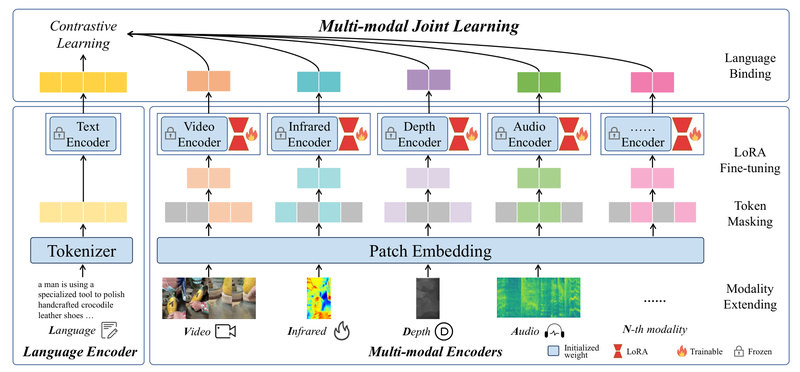
Imagine building an AI system that understands not just images and text—but also video, audio, infrared (thermal), and depth data—all…

Multimodal AI models like OpenAI’s CLIP have transformed how developers build systems that understand both images and text. But there’s…
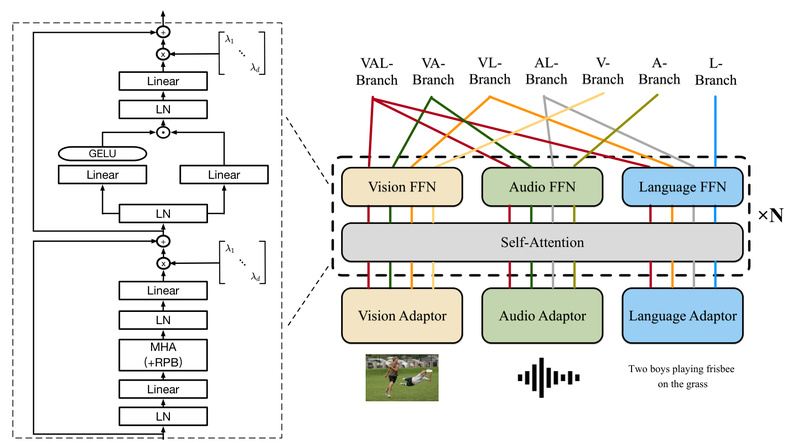
In today’s AI landscape, most multimodal systems are built by stitching together specialized models—separate vision encoders, audio processors, and language…
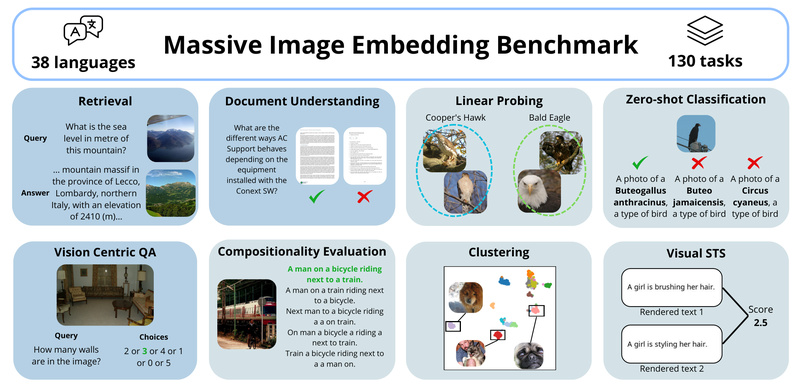
Evaluating image embedding models has long been a fragmented and inconsistent process. Researchers and engineers often test models on narrow,…