Large language models (LLMs) like ChatGPT are transforming how we interact with AI—but they often “make things up.” These fabricated,…
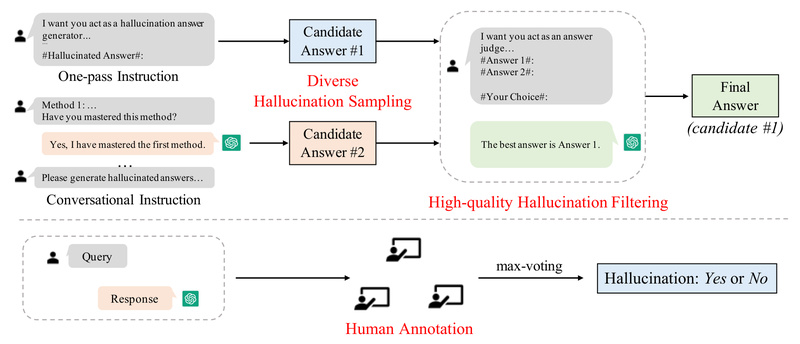
Large language models (LLMs) like ChatGPT are transforming how we interact with AI—but they often “make things up.” These fabricated,…
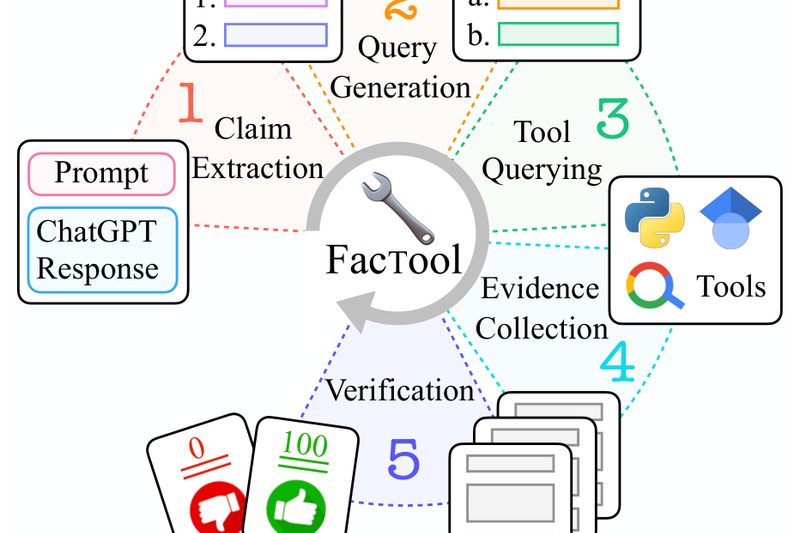
Large language models (LLMs) like ChatGPT and GPT-4 have transformed how we generate text, write code, solve math problems, and…
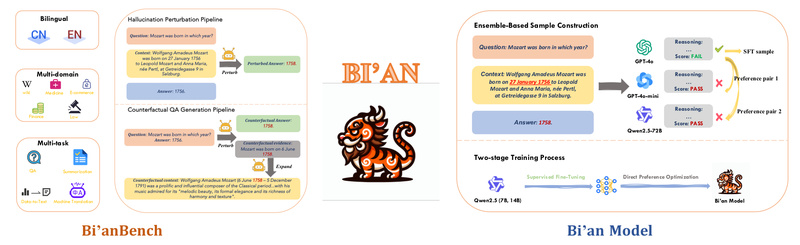
Retrieval-Augmented Generation (RAG) has become a go-to strategy for grounding large language model (LLM) responses in real-world knowledge. By pulling…
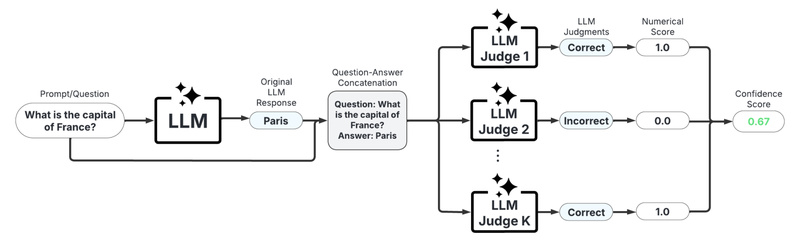
Large Language Models (LLMs) are transforming how we build intelligent applications—from customer service bots to clinical decision support tools. Yet…