Traditional multimodal large language models (MLLMs) often produce answers without revealing how they got there—especially when dealing with complex questions…
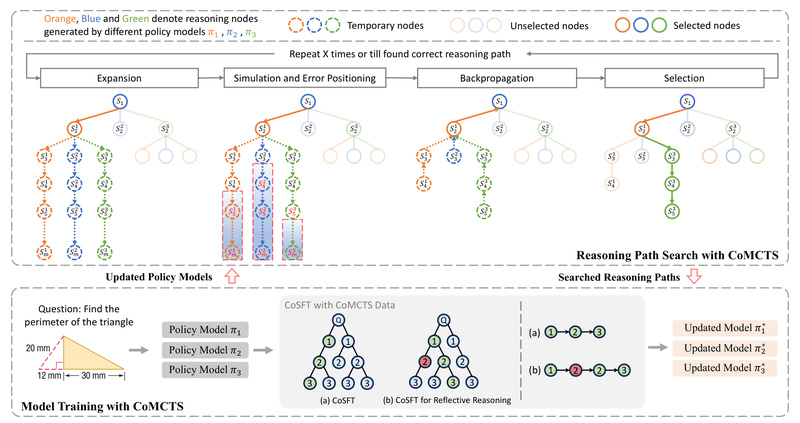
Traditional multimodal large language models (MLLMs) often produce answers without revealing how they got there—especially when dealing with complex questions…

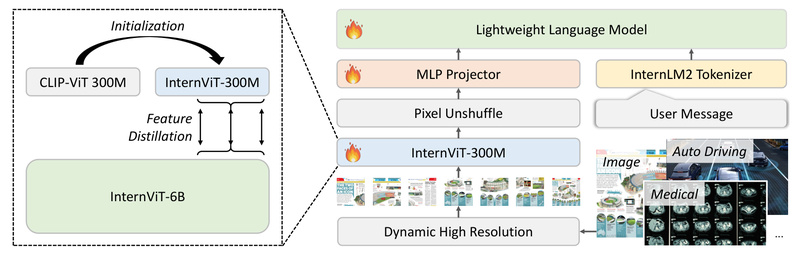
When it comes to deploying multimodal large language models (MLLMs) in real-world applications—especially on cost-sensitive or edge devices—lightweight models are…
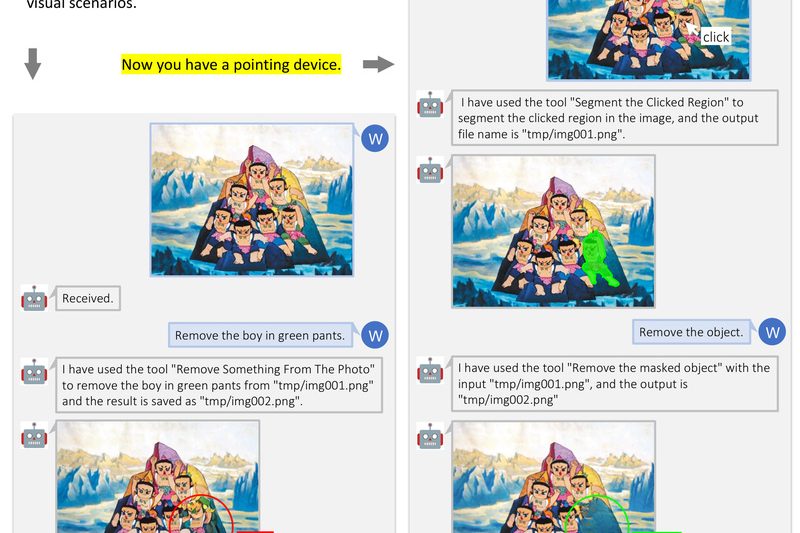
In today’s AI landscape, large language models (LLMs) like ChatGPT have transformed how we interact with software—through natural language. But…
Multimodal Large Language Models (MLLMs) promise to transform how machines understand images, videos, and text—but most top-performing models come with…
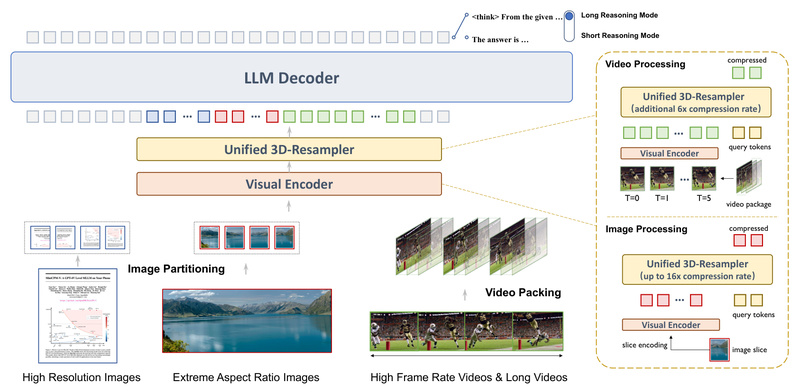
In an era where multimodal large language models (MLLMs) are rapidly advancing, a critical barrier remains: most high-performing vision-language models…
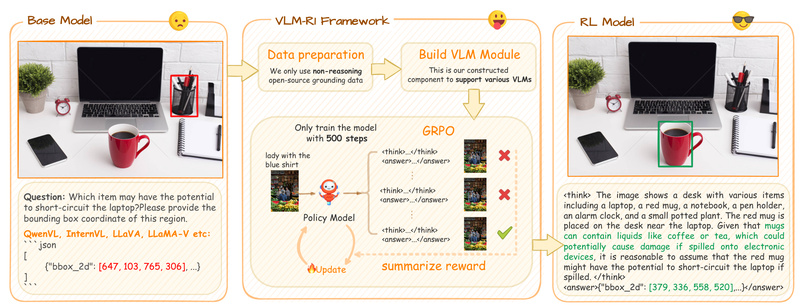
If you’re working on vision-language tasks that require precise reasoning—like identifying objects based on natural language descriptions, detecting UI defects…
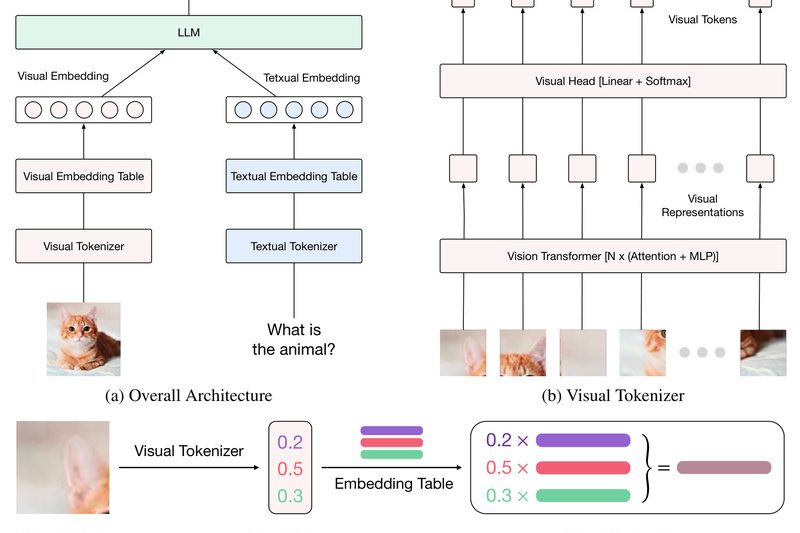
Multimodal Large Language Models (MLLMs) are increasingly vital for tasks that bridge vision and language—yet many struggle to truly fuse…
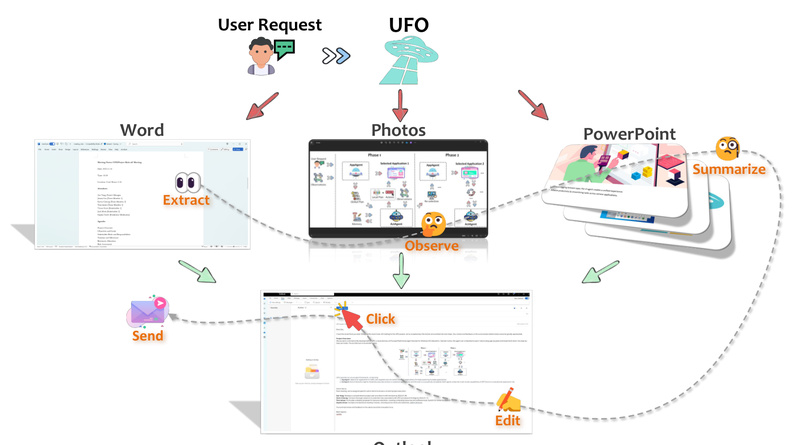
Imagine telling your computer what you want it to do—like “Summarize this PDF, email the summary to my manager, and…
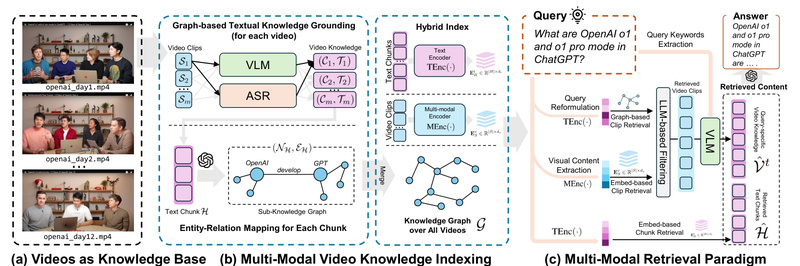
Imagine being able to ask questions like “What did the professor say about quantum entanglement in Lecture 3?” or “Show…
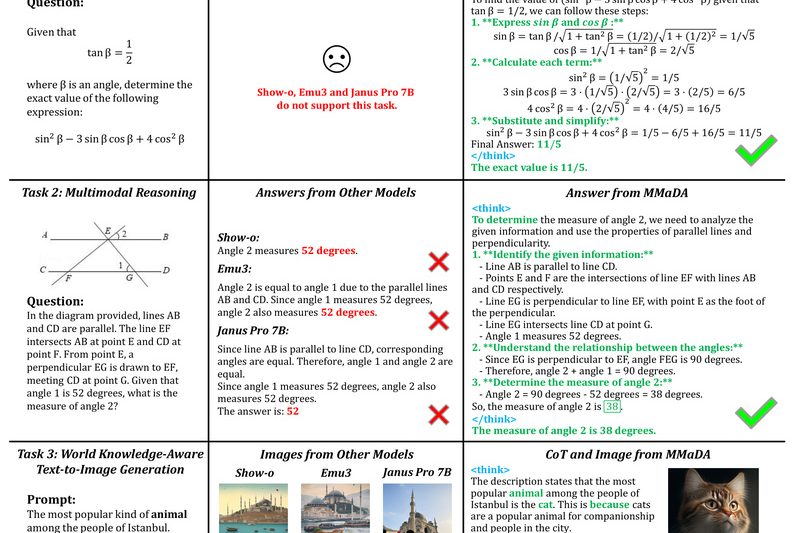
Imagine running a single model that can answer complex reasoning questions, understand images and text together, and generate high-quality images…