Building effective Retrieval-Augmented Generation (RAG) systems is notoriously difficult. Practitioners must juggle data preparation, retrieval integration, prompt engineering, model fine-tuning,…
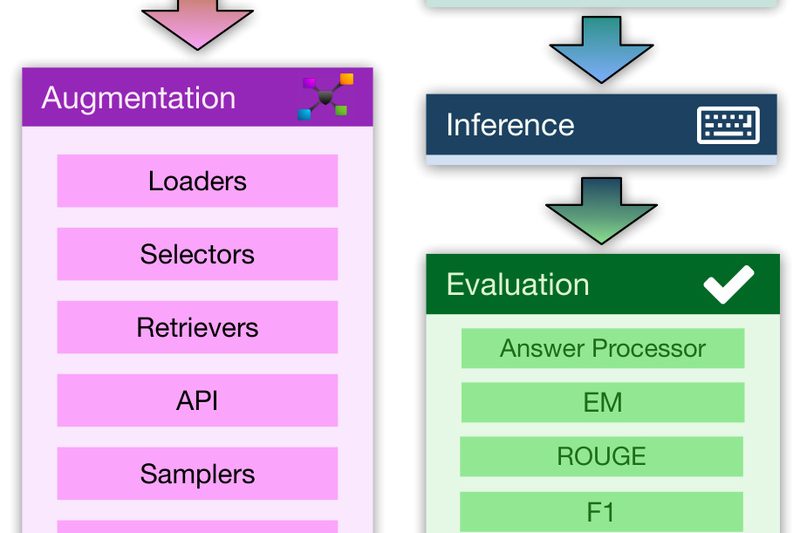
Building effective Retrieval-Augmented Generation (RAG) systems is notoriously difficult. Practitioners must juggle data preparation, retrieval integration, prompt engineering, model fine-tuning,…
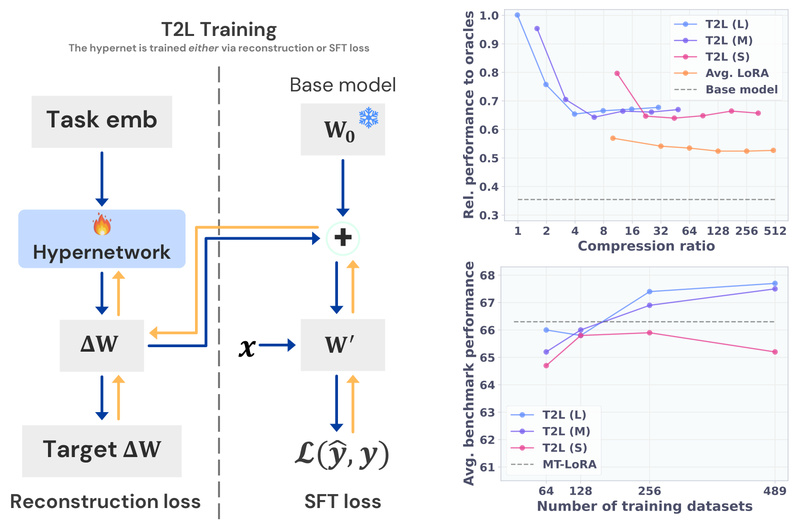
Large language models (LLMs) are powerful, but adapting them to specific tasks often demands significant effort: collecting labeled data, tuning…
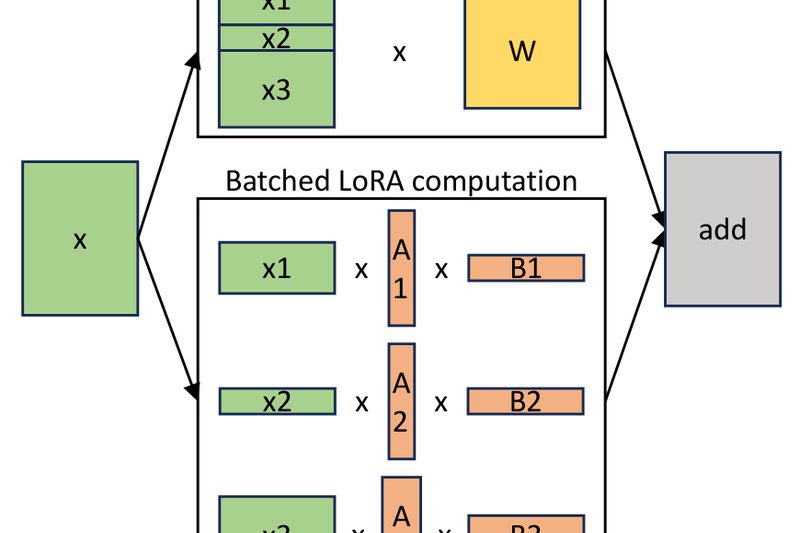
Deploying dozens—or even thousands—of fine-tuned large language models (LLMs) has traditionally been a costly and complex endeavor. Each adapter typically…
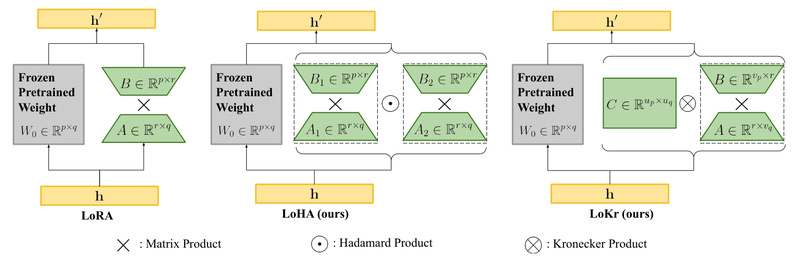
If you’re working with text-to-image models like Stable Diffusion, you’ve likely faced the trade-off between customization and efficiency. Full fine-tuning…

If you’re working on a project that requires a capable language model—but lack the GPU budget, time, or infrastructure for…
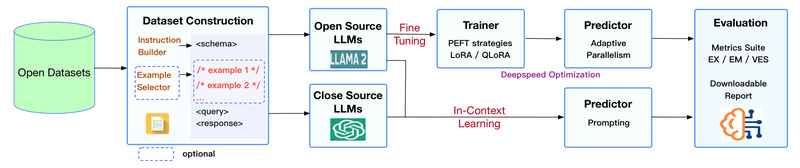
If you’ve ever tried building a natural language interface to a relational database, you know the real bottleneck isn’t the…
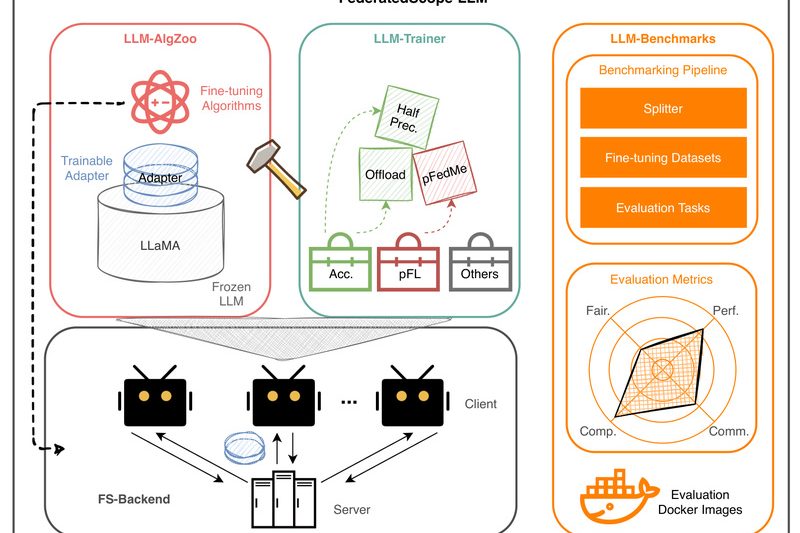
In today’s data-sensitive world, organizations increasingly want to harness the power of large language models (LLMs) while complying with strict…