Building AI agents that can handle diverse, real-world tasks—and improve over time without hand-holding—is one of the biggest challenges in…
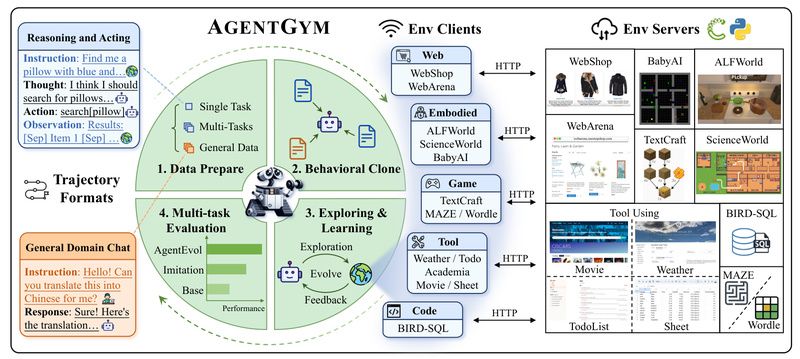
Building AI agents that can handle diverse, real-world tasks—and improve over time without hand-holding—is one of the biggest challenges in…
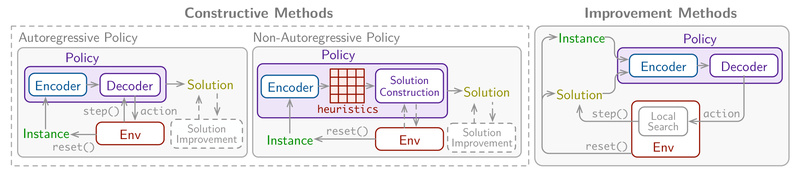
Combinatorial optimization (CO) lies at the heart of countless real-world challenges—from vehicle routing and job scheduling to chip design and…
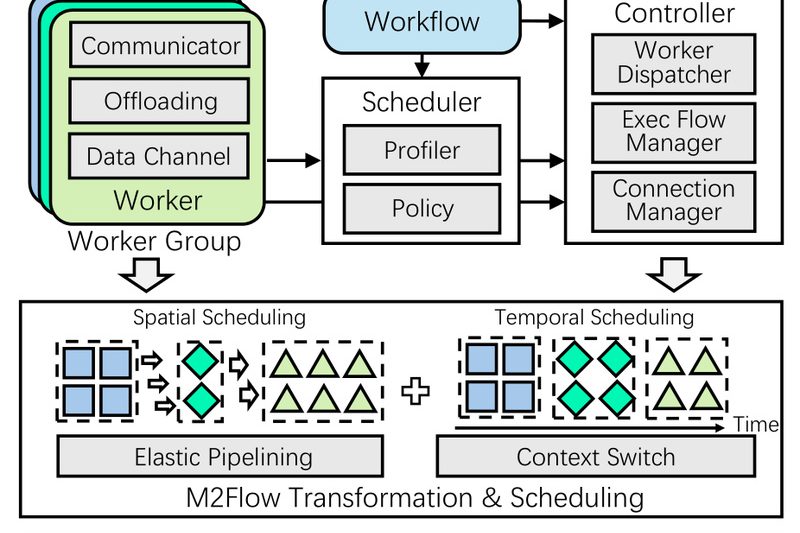
Reinforcement learning (RL) is rapidly becoming the engine behind next-generation agentic AI—powering everything from math-reasoning language models to vision-guided robotic…
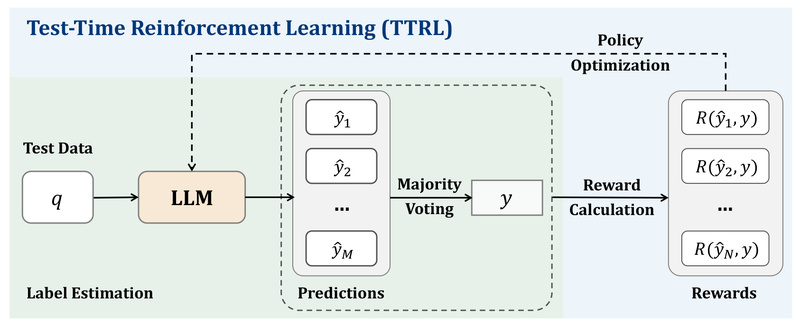
Imagine being able to improve a large language model’s (LLM) reasoning capabilities after deployment, using only unlabeled test data—no ground-truth…
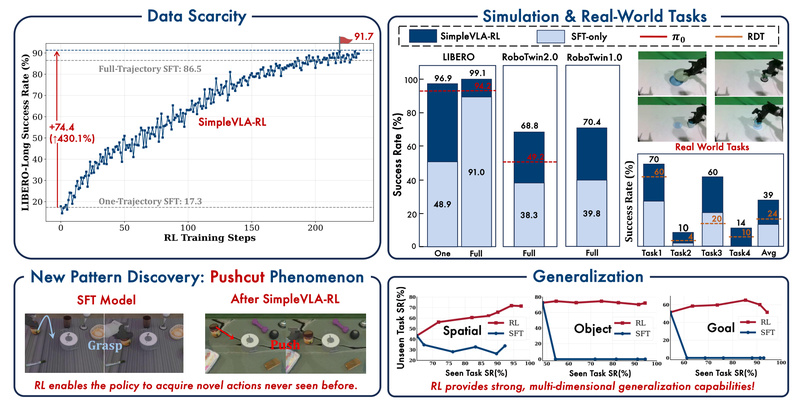
Building capable robotic systems that understand vision, language, and action—commonly referred to as Vision-Language-Action (VLA) models—has become a central goal…

Imagine needing realistic, physics-compliant character movement for a game, simulation, or robotics project—but without the months of trial, error, and…
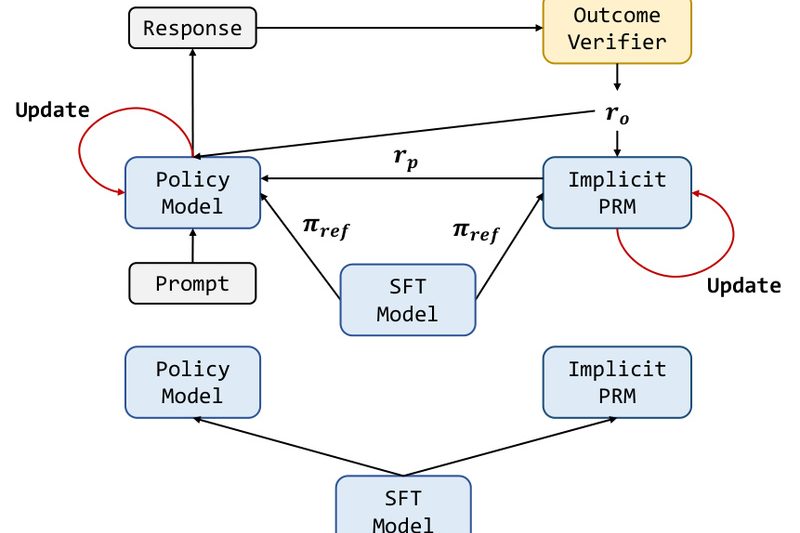
If you’re working to improve large language models (LLMs) on hard reasoning tasks—like math problem solving or competitive programming—you’ve likely…
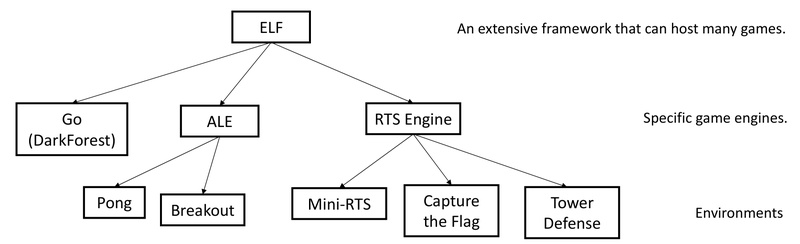
Reinforcement learning (RL) for real-time strategy (RTS) games has long been bottlenecked by slow simulation, rigid environment interfaces, and high…
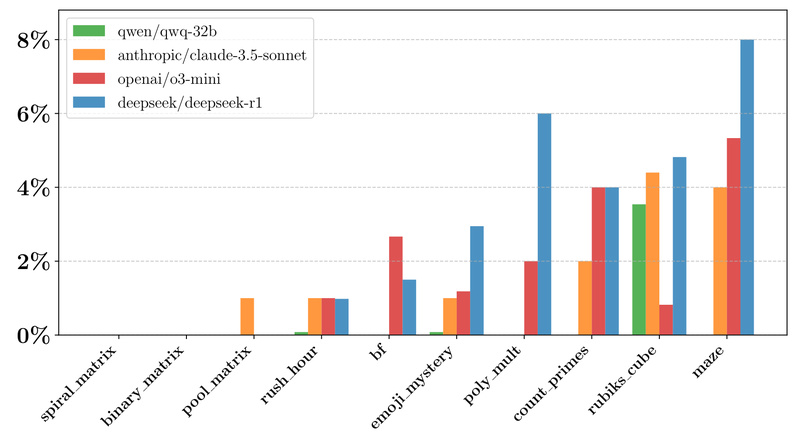
If you’re building or evaluating reasoning-capable AI systems—especially large language models (LLMs)—you’ve likely hit a wall with static benchmarks. Traditional…
Reinforcement learning (RL) holds immense promise for solving complex decision-making problems—from robotics and game playing to resource optimization and autonomous…