Imagine you’re building a retrieval-augmented generation (RAG) system, a scientific literature assistant, or a natural-language interface to a clinical trial…
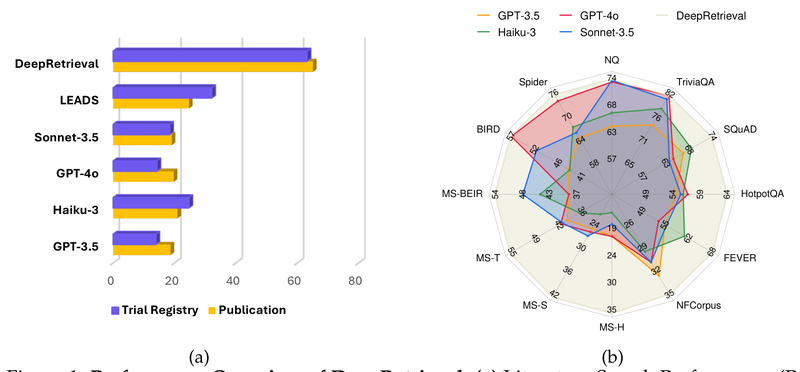
Imagine you’re building a retrieval-augmented generation (RAG) system, a scientific literature assistant, or a natural-language interface to a clinical trial…
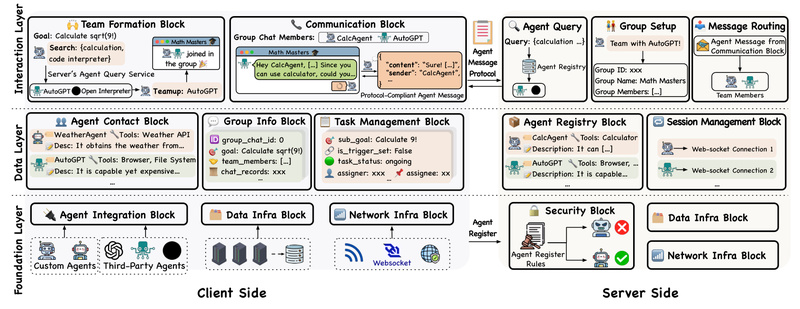
Imagine a world where AI agents—each with unique skills like web browsing, code execution, or data analysis—can autonomously find one…

If you’re building AI-powered tools for the Chinese financial sector—whether for banking, fintech, investment research, or regulatory compliance—you’ve likely run…
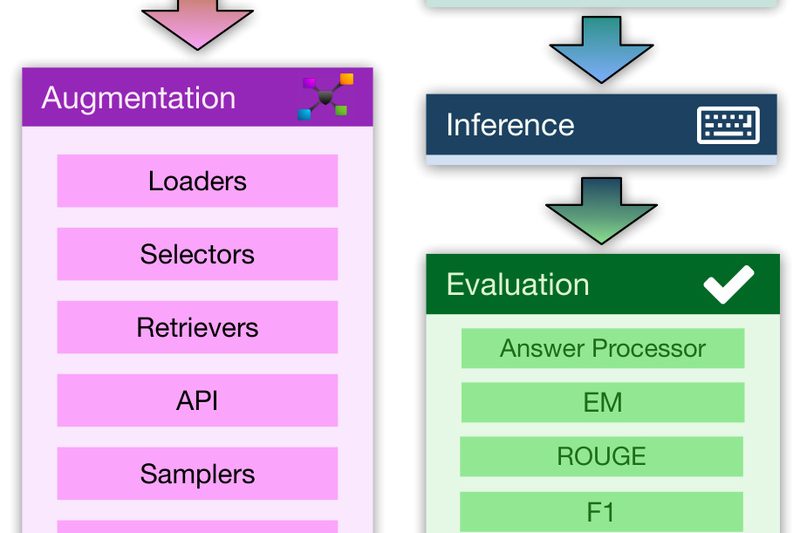
Building effective Retrieval-Augmented Generation (RAG) systems is notoriously difficult. Practitioners must juggle data preparation, retrieval integration, prompt engineering, model fine-tuning,…
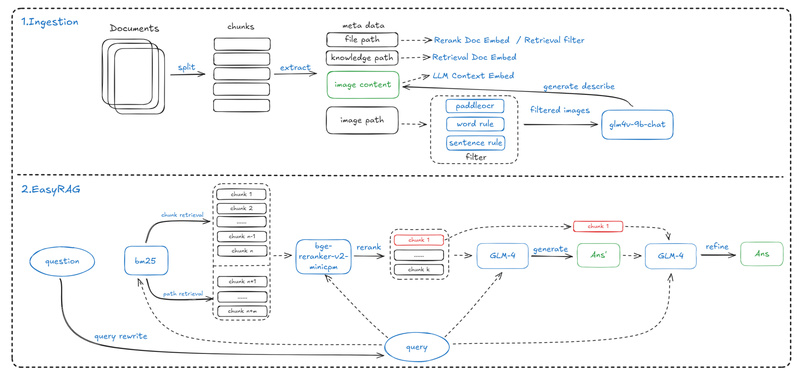
In today’s fast-paced IT and enterprise environments, teams increasingly rely on retrieval-augmented generation (RAG) systems to provide accurate, context-aware answers…
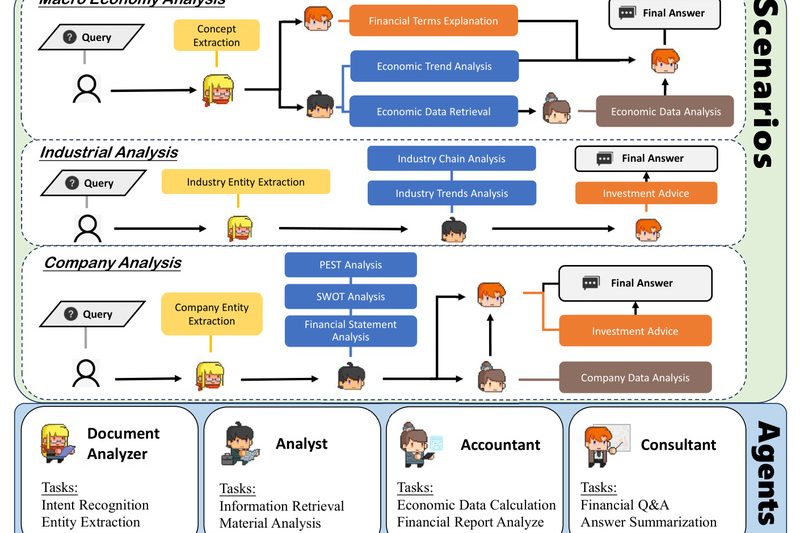
Financial analysis is rarely a solo endeavor. In real-world institutions—from investment banks to asset management firms—complex tasks like producing quarterly…
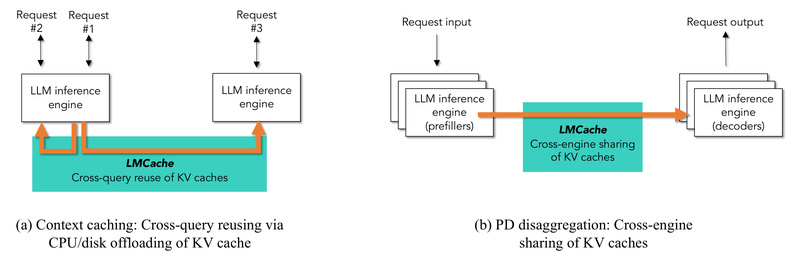
Deploying large language models (LLMs) at scale introduces a familiar bottleneck: the growing size of Key-Value (KV) caches rapidly outpaces…
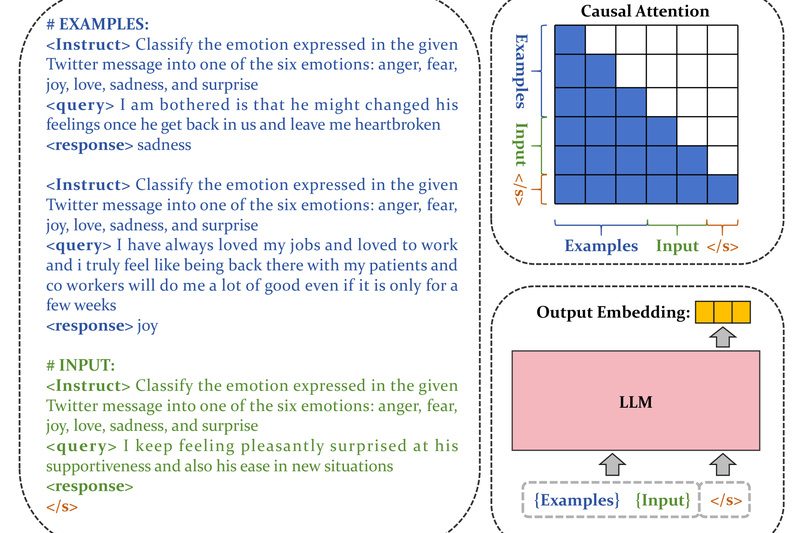
Modern AI applications—from customer support chatbots to enterprise knowledge retrieval—rely heavily on high-quality text embeddings to power semantic search and…

In the rapidly evolving landscape of large language models (LLMs), a critical limitation persists: despite their impressive fluency, LLMs often…
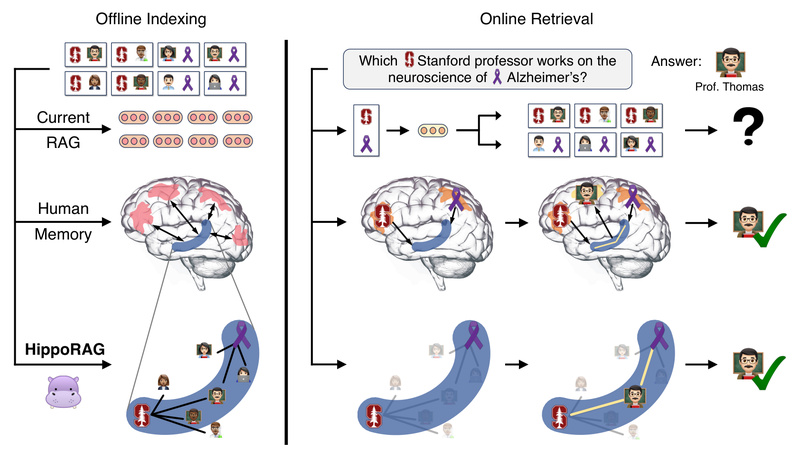
Retrieval-Augmented Generation (RAG) has become a go-to architecture for grounding large language models (LLMs) in external knowledge. Yet, even the…