What if a single large language model (LLM) could both understand and generate high-quality images—without relying on external vision encoders…
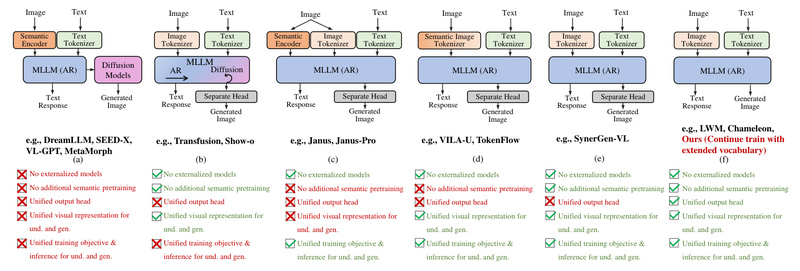
What if a single large language model (LLM) could both understand and generate high-quality images—without relying on external vision encoders…
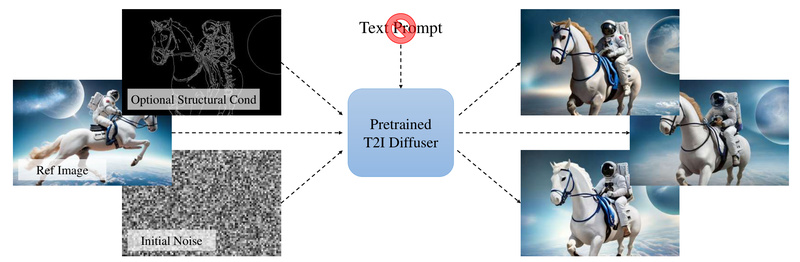
Text-to-image (T2I) diffusion models have revolutionized creative workflows—but they come with a hidden bottleneck: prompt engineering. Describing an image in…

Generating high-quality images from text prompts has become remarkably powerful thanks to diffusion models like Stable Diffusion. Yet, for many…

Generating realistic images with multiple distinct subjects—each retaining their unique identity and visual attributes like pose, lighting, or clothing style—has…

Autoregressive (AR) models have long dominated natural language generation, but applying the same step-by-step prediction approach to images has been…
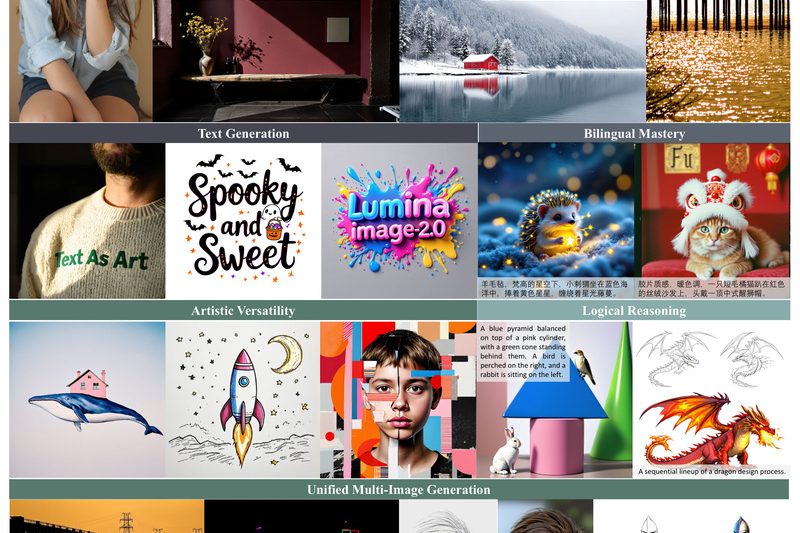
Lumina-Image 2.0 is a state-of-the-art open-source text-to-image (T2I) generation framework that delivers exceptional visual fidelity and prompt adherence while maintaining…
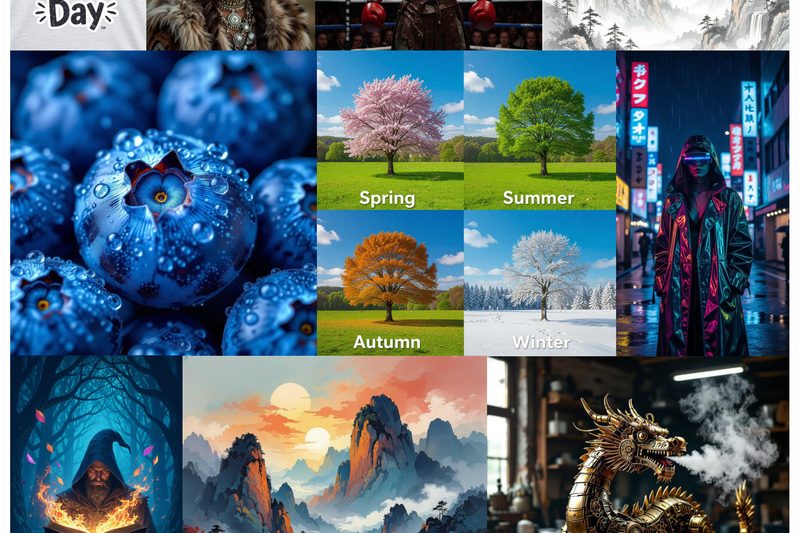
The rapid evolution of AI-driven image generation has unlocked incredible creative potential—but often at a steep cost: slow inference, massive…
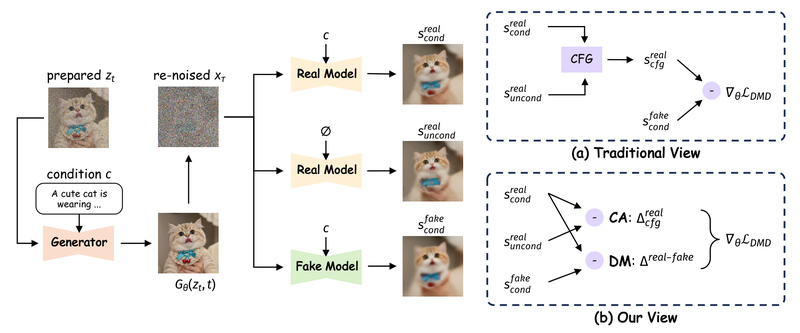
If you’re building or evaluating text-to-image systems that demand both speed and visual fidelity, Decoupled DMD offers a breakthrough in…

Text-to-image generation has made remarkable strides, yet even state-of-the-art models like DALL·E 3 or Stable Diffusion XL (SDXL) often stumble…
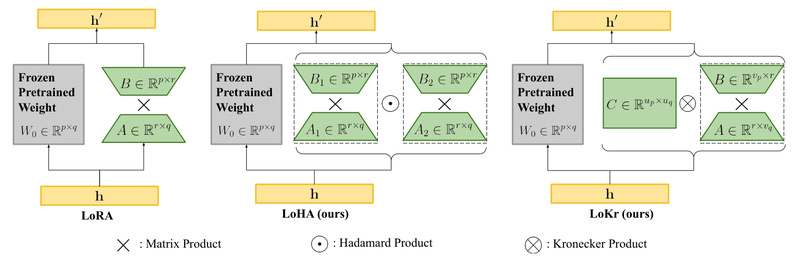
If you’re working with text-to-image models like Stable Diffusion, you’ve likely faced the trade-off between customization and efficiency. Full fine-tuning…