For teams building real-world AI applications that combine vision and language—whether it’s parsing scanned documents, analyzing instructional videos, or creating…
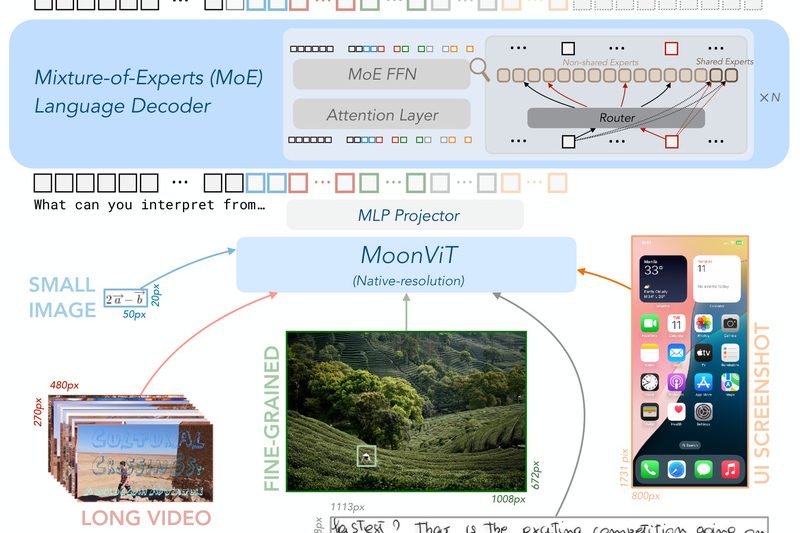
For teams building real-world AI applications that combine vision and language—whether it’s parsing scanned documents, analyzing instructional videos, or creating…
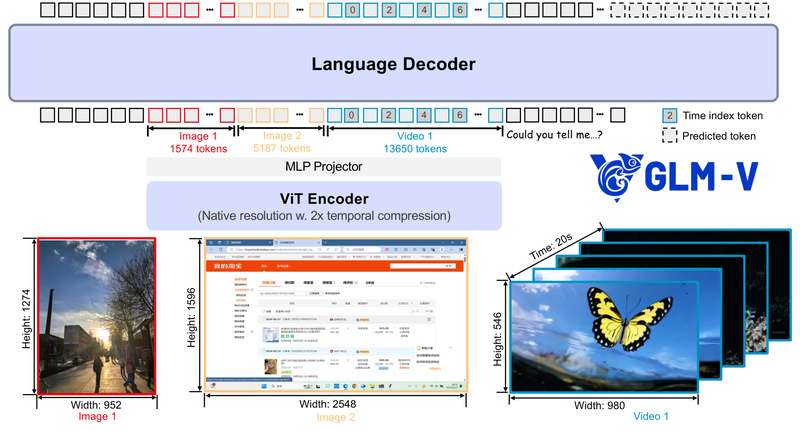
If your team is building AI applications that need to see, reason, and act—like desktop assistants that interpret screenshots, UI…
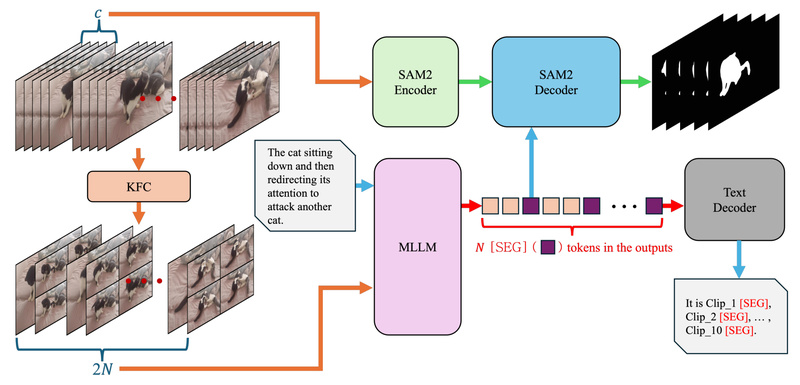
Sa2VA represents a significant leap forward in multimodal AI by seamlessly integrating the strengths of SAM2—Meta’s state-of-the-art video object segmentation…
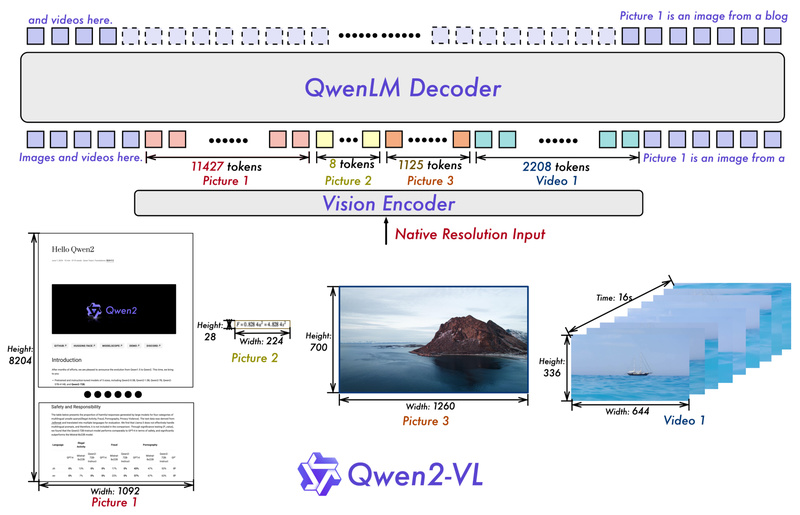
Vision-language models (VLMs) are increasingly essential for tasks that require joint understanding of images, videos, and text—ranging from document parsing…
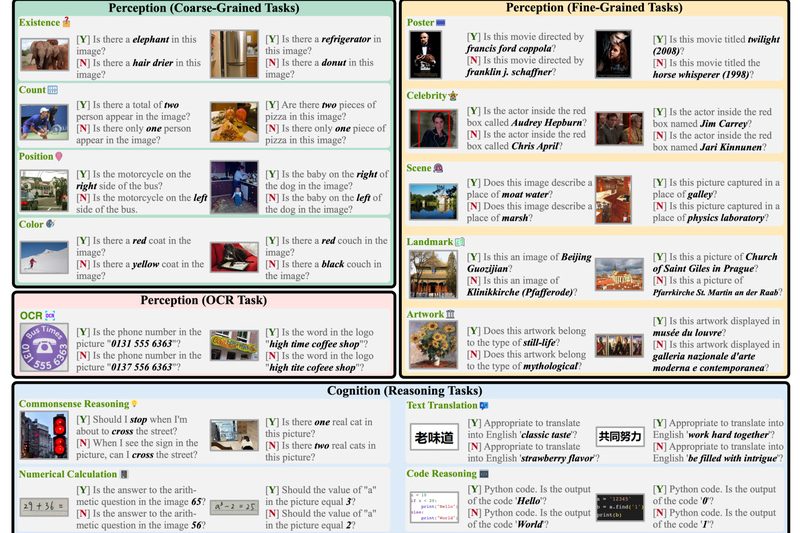
Multimodal Large Language Models (MLLMs) have captured the imagination of researchers and developers alike—promising capabilities like generating poetry from images,…

Overview For technical decision makers evaluating multimodal AI, choosing between closed-source APIs and open alternatives often means trading off control,…
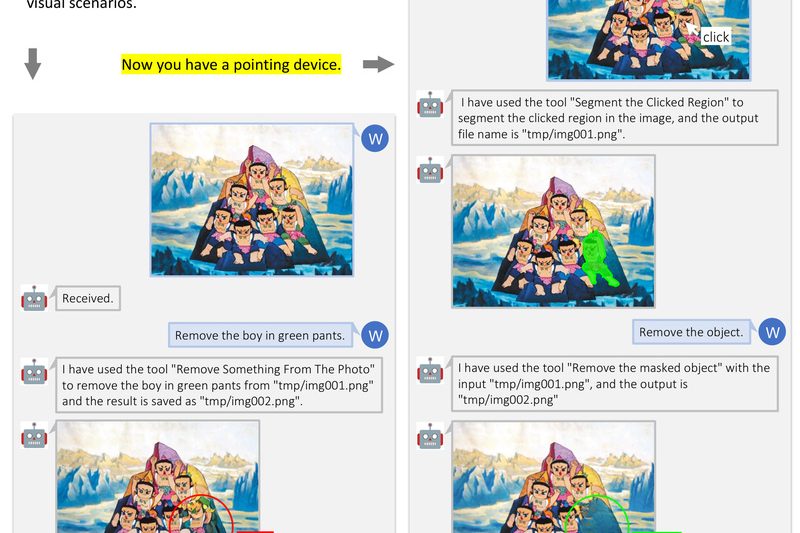
In today’s AI landscape, large language models (LLMs) like ChatGPT have transformed how we interact with software—through natural language. But…
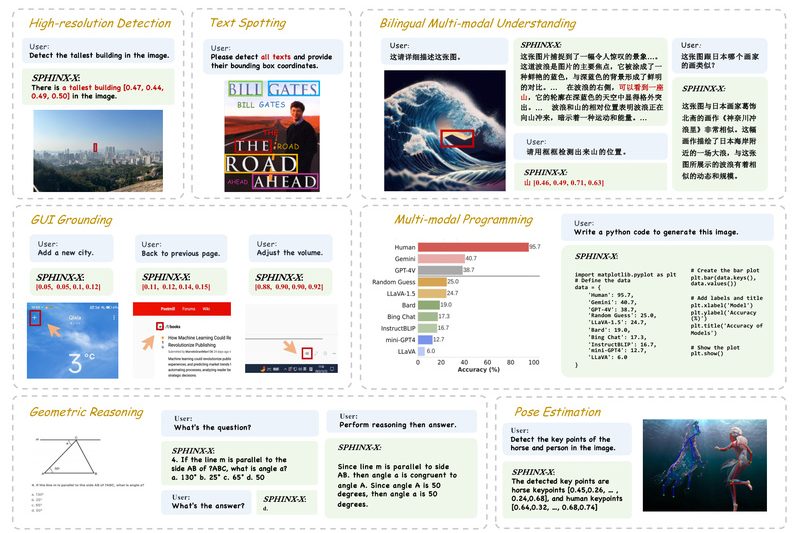
SPHINX-X is a next-generation family of Multimodal Large Language Models (MLLMs) designed to streamline the development, training, and deployment of…

Traditional image captioning systems produce static, one-size-fits-all descriptions—often generic, inflexible, and disconnected from actual user intent. What if you could…
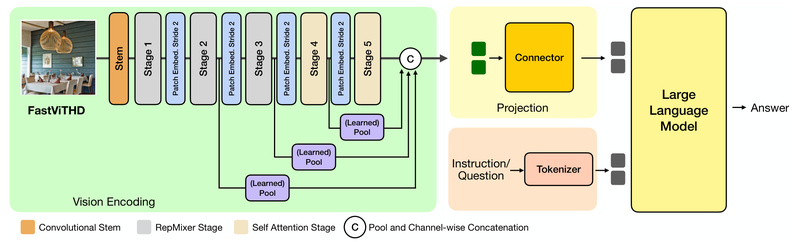
Vision Language Models (VLMs) are increasingly central to real-world applications—from mobile assistants that read documents to AI systems that interpret…