In the era of foundation models, CLIP (Contrastive Language–Image Pretraining) has revolutionized how we approach vision-language tasks—especially zero-shot image classification.…
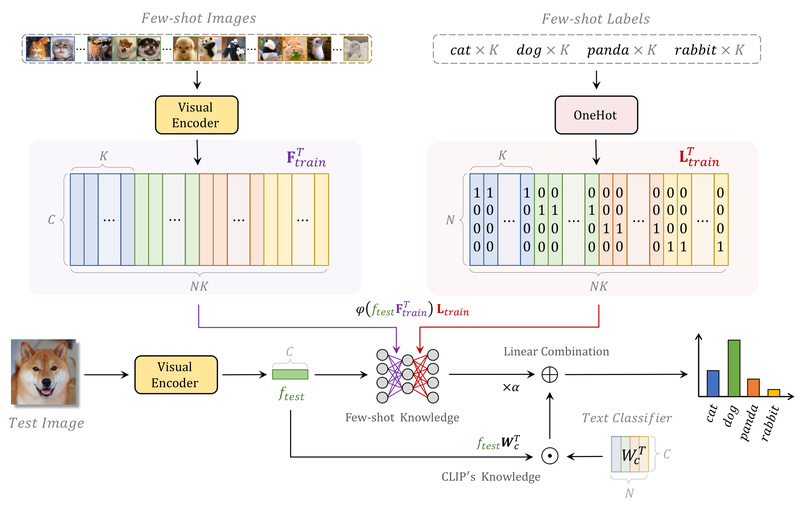
In the era of foundation models, CLIP (Contrastive Language–Image Pretraining) has revolutionized how we approach vision-language tasks—especially zero-shot image classification.…
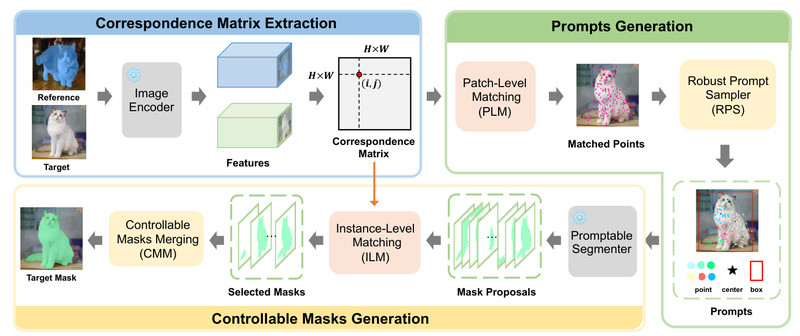
In modern computer vision workflows, deploying accurate segmentation models often demands large annotated datasets, task-specific architectures, and costly retraining—barriers that…

Imagine building a system that can understand 3D objects as intuitively as humans do—recognizing a chair from its point cloud,…