Imagine building an AI system that understands not just images and text—but also video, audio, infrared (thermal), and depth data—all…
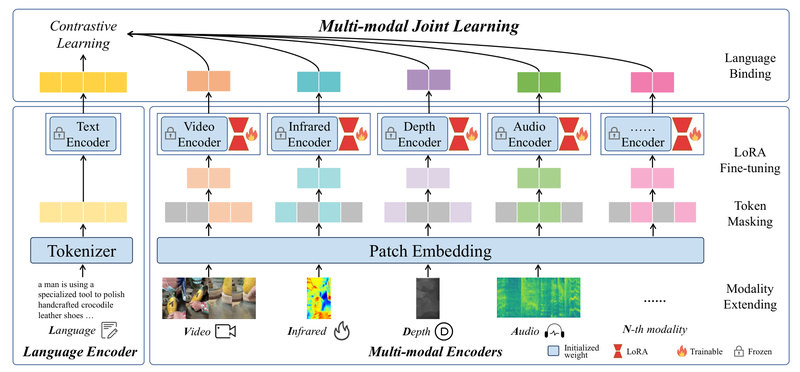
Imagine building an AI system that understands not just images and text—but also video, audio, infrared (thermal), and depth data—all…
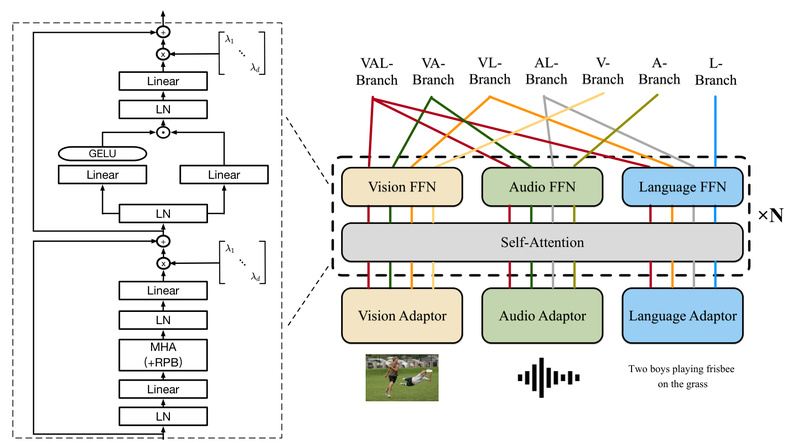
In today’s AI landscape, most multimodal systems are built by stitching together specialized models—separate vision encoders, audio processors, and language…