Document layout analysis (DLA) is a foundational task in building real-world document understanding systems—whether you’re extracting structured data from invoices, converting scanned reports into editable formats, or enriching retrieval-augmented generation (RAG) pipelines with layout-aware context. Historically, this task has been caught in a frustrating trade-off: multimodal approaches that fuse visual and textual cues achieve high accuracy but suffer from slow inference, while purely visual models deliver speed at the cost of precision.
Enter DocLayout-YOLO, a breakthrough solution that shatters this dichotomy. Built on the efficient YOLO-v10 architecture and enhanced with document-specific innovations, DocLayout-YOLO delivers both real-time inference speed and state-of-the-art accuracy across diverse document types—from dense academic papers to sparse business forms.
What makes it especially compelling for technical decision-makers is its practical design: it requires no multimodal inputs (just an image), integrates easily into existing workflows, and comes with production-ready pre-trained models. If you need reliable, scalable layout detection that doesn’t force you to choose between performance and efficiency, DocLayout-YOLO is worth serious consideration.
Why DocLayout-YOLO Stands Out
Solving the Core Dilemma: Speed Meets Accuracy
Unlike prior approaches that compromise on one dimension to optimize the other, DocLayout-YOLO achieves both through two key innovations:
-
Large-Scale Synthetic Pre-Training with DocSynth-300K
The team behind DocLayout-YOLO introduced Mesh-candidate BestFit, an algorithm that treats document synthesis as a 2D bin-packing problem. This enables the automatic generation of DocSynth-300K, a diverse, high-quality synthetic dataset containing 300,000 annotated document layouts. Pre-training on this dataset dramatically improves generalization across real-world document types—even on domains not seen during fine-tuning. -
Global-to-Local Controllable Receptive Module
Documents contain elements at wildly different scales: a full-page table, a tiny footnote, or a narrow column of text. To handle this variability, DocLayout-YOLO incorporates a novel receptive field module that adaptively captures both global context and fine-grained local details. This architectural tweak significantly boosts detection accuracy for multi-scale components without adding computational overhead.
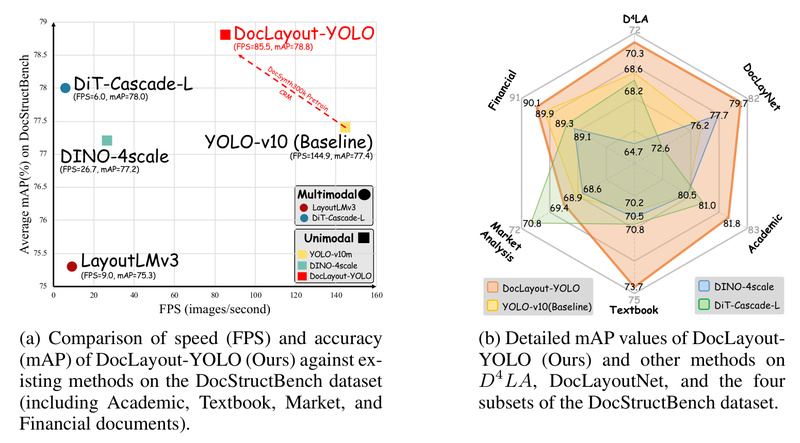
Together, these enhancements allow DocLayout-YOLO to outperform existing methods on standard benchmarks like D4LA and DocLayNet—achieving AP50 scores above 93% on DocLayNet while maintaining real-time processing capabilities.
Where DocLayout-YOLO Delivers Real Value
Practical Use Cases for Teams and Products
DocLayout-YOLO isn’t just a research prototype—it’s built for deployment. Here’s where it excels in real-world scenarios:
- Enterprise Document Automation: Automatically parse invoices, contracts, and forms to extract structured fields, reducing manual data entry and human error.
- PDF Content Extraction: When paired with tools like PDF-Extract-Kit, DocLayout-YOLO provides precise bounding boxes for paragraphs, tables, figures, and headers—enabling high-fidelity reconstruction of document semantics.
- RAG and Knowledge Retrieval Systems: Improve context relevance in retrieval-augmented generation by preserving document structure; for example, distinguishing between a caption and body text prevents hallucinated associations.
- OCR Pipeline Enhancement: Feed layout-aware regions into downstream OCR engines to improve text recognition accuracy, especially in complex layouts with mixed content types.
Critically, because DocLayout-YOLO operates solely on visual input (no need for embedded text or OCR preprocessing), it works reliably on scanned or image-based documents—a common pain point in production environments.
Getting Started Is Surprisingly Simple
Zero to Inference in Under Five Minutes
You don’t need a GPU cluster or a PhD to try DocLayout-YOLO. The project provides multiple frictionless entry points:
Option 1: Try the Online Demo
An interactive demo is hosted on Hugging Face Spaces—ideal for quick validation.
Option 2: Install and Run Locally
For integration into your own system, installation is as straightforward as:
pip install doclayout-yolo
Then, run inference in just a few lines of Python:
from doclayout_yolo import YOLOv10
model = YOLOv10.from_pretrained("juliozhao/DocLayout-YOLO-DocStructBench")
results = model.predict("your_document.jpg", imgsz=1024, conf=0.2)
annotated = results[0].plot(pil=True)
The pre-trained model—fine-tuned on the DocStructBench benchmark—handles a wide variety of document layouts out of the box, making it ideal for prototyping or production use without custom training.
For batch processing, simply pass a list of image paths to the predict method. And if you’re working with PDFs, combine DocLayout-YOLO with PDF-Extract-Kit or MinerU for end-to-end document understanding.
Limitations and Things to Keep in Mind
While DocLayout-YOLO offers impressive capabilities, it’s important to understand its boundaries:
- Visual-Only Input: It does not leverage embedded text or font metadata, so it cannot distinguish between visually identical but semantically different elements (e.g., a heading that looks like body text). This is by design—enabling use on scanned documents—but may limit performance in text-rich digital PDFs where multimodal signals could help.
- PDF Handling Requires External Tools: DocLayout-YOLO processes images, not PDFs. You’ll need a separate tool to rasterize PDF pages before inference.
- Pre-Training Resource Demands: While inference is lightweight, training from scratch on DocSynth-300K requires significant GPU memory and may encounter data-loading memory leaks (mitigated via checkpoint resumption). Most users will benefit more from fine-tuning or using the provided models.
These constraints are typical for visual layout models, and the project documentation offers clear guidance on workarounds and integrations.
Summary
DocLayout-YOLO redefines what’s possible in document layout analysis by delivering high accuracy and real-time speed in a single, easy-to-deploy package. Its foundation in synthetic data diversity and adaptive perception architecture makes it robust across document genres, while its YOLO-v10 backbone ensures practical inference performance.
For project leads, engineering managers, or researchers evaluating layout detection solutions, DocLayout-YOLO lowers the barrier to adoption—offering a pre-trained, well-documented, and actively maintained model that integrates seamlessly into document AI pipelines. If your use case involves turning unstructured documents into structured, actionable data—fast and accurately—DocLayout-YOLO deserves a place in your toolkit.