FastViT is a high-performance hybrid vision transformer designed to deliver exceptional speed and accuracy—especially on resource-constrained platforms like mobile phones and edge devices. Developed by Apple researchers and introduced at ICCV 2023, FastViT rethinks how convolutional and transformer architectures can be combined to minimize latency without sacrificing model quality. For practitioners building real-time vision applications—whether for image classification, object detection, segmentation, or even 3D mesh regression—FastViT offers a compelling alternative to established models like EfficientNet, ConvNeXt, and CMT, with benchmark results that demonstrate clear advantages in both efficiency and robustness.
Why FastViT Matters for Real-World Deployment
In practical computer vision systems, latency and accuracy are rarely independent goals. A model might be highly accurate in the lab but too slow to deploy on-device, or fast but unreliable under real-world conditions like image corruption or domain shifts. FastViT directly addresses this tension by optimizing for the latency–accuracy trade-off from the ground up.
According to official benchmarks on the iPhone 12 Pro:
- FastViT is 3.5× faster than CMT,
- 4.9× faster than EfficientNet, and
- 1.9× faster than ConvNeXt—all at comparable ImageNet Top-1 accuracy.
Even more impressively, at similar latency to MobileOne, FastViT achieves 4.2% higher Top-1 accuracy. These gains aren’t limited to classification: FastViT consistently outperforms competitors across detection, segmentation, and 3D regression tasks on both mobile and desktop GPUs. Additionally, it shows superior robustness to out-of-distribution data and common corruptions—critical for production systems.
Core Innovations Behind FastViT
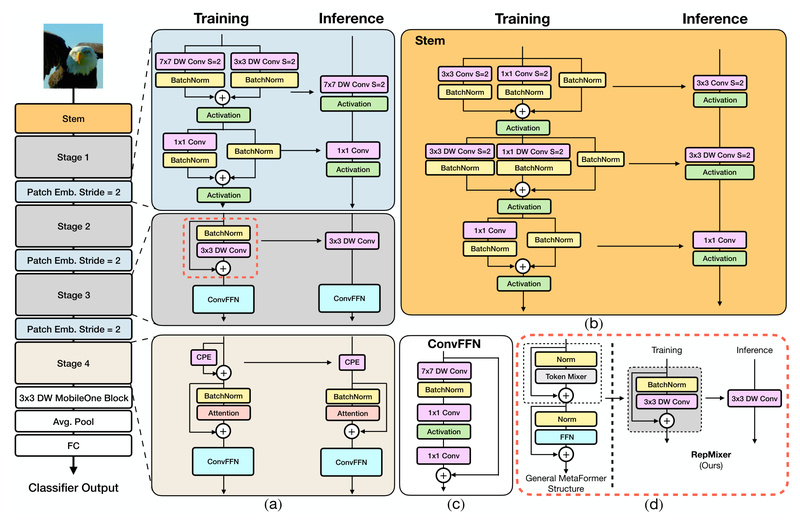
RepMixer: A Memory-Efficient Token Mixer
At the heart of FastViT is RepMixer, a novel token mixing operator that replaces traditional skip connections with a structurally reparameterized design. During training, the model uses an overparameterized architecture to maximize representational capacity. But at inference time, these redundant structures are fused into a single, streamlined layer—significantly reducing memory access costs and improving runtime speed without altering the model’s output.
This approach draws inspiration from techniques like MobileOne but adapts them for hybrid transformer–CNN architectures, enabling both high throughput and strong generalization.
Large-Kernel Convolutions Without Latency Penalty
FastViT integrates large-kernel convolutions (e.g., 7×7 or larger) in early stages to capture broader spatial context. Typically, such operations increase computational load—but thanks to structural reparameterization and careful hardware-aware design, FastViT absorbs their cost with minimal impact on latency. This design choice directly contributes to its improved accuracy, especially on fine-grained visual tasks.
Train Complex, Deploy Simple
FastViT follows a “train big, deploy lean” philosophy. The training-time model includes auxiliary branches and skip connections that enhance learning. Once training concludes, these are reparameterized into a single, efficient inference graph. This means you get the best of both worlds: high-capacity training dynamics and a lightweight deployment artifact.
Best-Fit Use Cases
FastViT excels in scenarios where low latency, high accuracy, and on-device execution are non-negotiable:
- Mobile image classification: With latency as low as 0.8 ms (FastViT-T8) on iPhone 12 Pro, it’s ideal for camera-based applications.
- Real-time object detection and semantic segmentation: Pre-trained ImageNet checkpoints can be easily fine-tuned for downstream vision tasks using the unfused model format.
- 3D vision tasks: Demonstrated success in 3D mesh regression opens doors for AR/VR and robotics applications.
- Robust vision under uncertainty: Its strong performance on corrupted and out-of-distribution data makes it suitable for safety-critical systems.
All official latency measurements are based on iPhone 12 Pro via the ModelBench app, providing a realistic reference for iOS developers.
Getting Started with FastViT
Setting up and using FastViT is straightforward for practitioners familiar with PyTorch and TIMM:
-
Environment Setup
conda create -n fastvit python=3.9 conda activate fastvit conda install pytorch==1.11.0 torchvision==0.12.0 -c pytorch pip install -r requirements.txt
-
Load and Fine-Tune
Use the unfused checkpoint for training or transfer learning:from timm.models import create_model import torch model = create_model("fastvit_t8") checkpoint = torch.load('/path/to/unfused_checkpoint.pth.tar') model.load_state_dict(checkpoint['state_dict']) # Proceed with fine-tuning -
Optimize for Inference
Reparameterize the model before deployment to fuse branches:from models.modules.mobileone import reparameterize_model model.eval() model_inf = reparameterize_model(model) # Use this for inference
-
Export to Core ML (for iOS)
FastViT provides official support for Core ML export:python export_model.py --variant fastvit_t8 --checkpoint /path/to/fastvit_t8_reparam.pth.tar --output-dir /path/to/export
Pre-trained models for variants like T8, T12, S12, SA12–SA36, and MA36 are available in both standard and knowledge-distilled versions, offering flexible trade-offs between size and accuracy.
Performance at a Glance
The official model zoo reports ImageNet-1K Top-1 accuracy and iPhone 12 Pro latency:
| Model | Top-1 Acc. (%) | Latency (ms) |
|---|---|---|
| FastViT-T8 | 76.2 (77.2*) | 0.8 |
| FastViT-SA12 | 80.9 (81.9*) | 1.6 |
| FastViT-MA36 | 83.9 (84.6*) | 4.6 |
(*Values in parentheses use knowledge distillation.)
These results confirm that even the smallest FastViT models outperform many heavier alternatives in both speed and quality.
Limitations and Practical Considerations
While FastViT offers significant advantages, practitioners should note a few constraints:
- Reparameterization is required for optimal inference performance—you cannot deploy the training-time model as-is.
- Training involves overparameterized architectures, which increases memory usage during training (though not during inference).
- All official models are pre-trained exclusively on ImageNet-1K; support for other datasets or modalities (e.g., video, medical imaging) is not documented.
- Latency benchmarks are specific to iPhone 12 Pro; performance may vary on Android or other hardware, though the architectural efficiency should generalize well.
Summary
FastViT redefines what’s possible in efficient vision modeling by combining structural reparameterization, large-kernel convolutions, and hybrid design to achieve state-of-the-art speed and accuracy. For engineers and researchers deploying vision systems on mobile or edge devices, it provides a ready-to-use, highly optimized foundation that outperforms leading alternatives across multiple tasks—without compromising robustness. With easy integration into PyTorch workflows and official Core ML export support, FastViT lowers the barrier to deploying high-performance vision models in real-world applications.