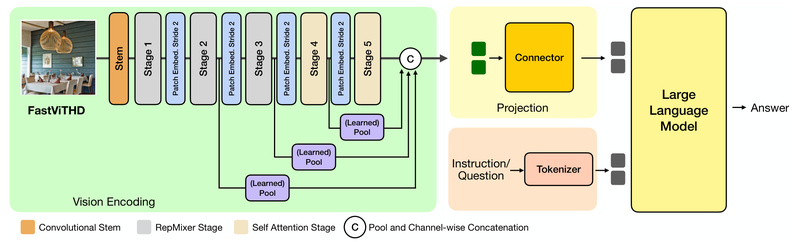
Vision Language Models (VLMs) are increasingly central to real-world applications—from mobile assistants that read documents to AI systems that interpret complex diagrams. Yet, as image resolution increases to capture fine-grained visual details (especially text), standard VLMs suffer from two critical bottlenecks: slow visual encoding and excessive token generation that bloats downstream language model processing.
FastVLM, introduced in the CVPR 2025 paper FastVLM: Efficient Vision Encoding for Vision Language Models, directly addresses these pain points. It achieves state-of-the-art efficiency without sacrificing accuracy by rethinking how high-resolution images are encoded. Unlike prior approaches that rely on post-hoc token pruning or complex multi-stage compression, FastVLM leverages a novel hybrid vision encoder—FastViTHD—that inherently produces fewer tokens while dramatically cutting encoding latency. The result? Up to 85× faster Time-to-First-Token (TTFT) and a vision encoder 3.4× smaller than leading alternatives, all while matching or exceeding performance on key benchmarks like DocVQA, MMMU, and SeedBench.
For developers, researchers, and product teams building real-time multimodal systems—especially on resource-constrained devices like smartphones—FastVLM offers a rare combination: high-resolution visual understanding, low latency, and deployment simplicity.
Why FastVLM Delivers Real-World Efficiency
A Smarter Vision Encoder: FastViTHD
At the heart of FastVLM lies FastViTHD, a hybrid architecture that blends strengths of CNNs and Vision Transformers (ViTs) to handle high-resolution inputs more efficiently. Traditional ViTs process images by dividing them into a dense grid of patches, leading to quadratic growth in tokens (and self-attention cost) as resolution scales. FastViTHD avoids this by strategically reducing token count during encoding—without requiring additional token selection or pruning modules.
This design means FastVLM achieves an optimal trade-off between image fidelity and computational load simply by scaling the input resolution, streamlining both training and inference pipelines.
Benchmark-Leading Speed Without Accuracy Sacrifice
In the widely used LLaVA-1.5 framework, FastVLM achieves 3.2× faster TTFT while maintaining competitive scores across standard VLM evaluation suites. More impressively, when compared to LLaVA-OneVision at 1152×1152 resolution:
- FastVLM outperforms it on text-heavy and reasoning-intensive benchmarks (DocVQA, MMMU, SeedBench)
- Uses the same 0.5B-parameter LLM
- Delivers 85× faster TTFT
- Employs a vision encoder that’s 3.4× smaller in model size
For applications where latency directly impacts user experience—like live camera-based assistants—this speedup is transformative.
Practical Use Cases Where FastVLM Shines
FastVLM isn’t just a research prototype—it’s engineered for deployment. Ideal scenarios include:
- Mobile document understanding: Parsing invoices, forms, or scanned textbooks on iOS devices with minimal delay.
- On-device multimodal assistants: Powering real-time image captioning or visual question answering on iPhones, iPads, or Macs.
- Edge AI systems with limited compute: Deploying VLMs in environments where memory and power are constrained, yet high-resolution input is non-negotiable.
- Batch processing of high-res media: Accelerating inference pipelines for datasets rich in fine visual details (e.g., medical imagery with annotations, engineering schematics).
Notably, the project includes a demo iOS app and full support for Apple Silicon, signaling strong readiness for consumer-facing products.
Getting Started: Simple Setup and Flexible Inference
FastVLM builds on the popular LLaVA codebase, making adoption straightforward for teams already familiar with that ecosystem. The workflow is minimal:
-
Environment Setup
conda create -n fastvlm python=3.10 conda activate fastvlm pip install -e .
-
Download Pretrained Models
The repository provides three model sizes (0.5B, 1.5B, and 7B LLM backends) across two training stages. Run:bash get_models.sh
Checkpoints are saved to the
checkpoints/directory. -
Run Inference
A single command generates a response:python predict.py --model-path /path/to/checkpoint-dir --image-file /path/to/image.png --prompt "Describe the image."
-
Deploy on Apple Devices
For iPhone, iPad, or Mac deployment, themodel_exportsubfolder provides tools to convert PyTorch checkpoints into Apple Silicon–optimized formats. Pre-exported models (stage-3 variants) are included for immediate testing.
This end-to-end support—from research-grade inference to on-device execution—lowers the barrier for integrating FastVLM into real products.
Limitations and Practical Considerations
While FastVLM excels in efficiency and ease of deployment, prospective users should note a few constraints:
- Training dependency: Model training and fine-tuning require the LLaVA framework, which may limit flexibility for teams using alternative VLM bases.
- Limited LLM variants: Current releases pair specific vision encoders with fixed LLM backbones (e.g., Qwen2-7B for the 7B variant). Custom LLM swaps aren’t natively supported.
- Apple-specific export steps: On-device performance on iOS or macOS requires additional conversion via the provided export tools—though documentation and pre-built models ease this process.
These are not blockers but rather considerations for integration planning.
Summary
FastVLM redefines what’s possible in efficient vision-language modeling. By co-designing image resolution, token count, and encoder architecture through FastViTHD, it eliminates the traditional latency-accuracy trade-off that has hindered real-world VLM deployment. With 85× faster TTFT, smaller model footprint, strong benchmark results, and first-class Apple device support, FastVLM is a compelling choice for anyone building responsive, high-resolution multimodal applications—especially where speed, size, and user experience matter most.