If you’ve ever struggled with diffusion models failing to follow detailed prompts—like “a golden retriever sitting to the left of two stacked red books under a hanging lamp”—you’re not alone. Off-the-shelf text-to-image models often stumble on compositional reasoning, precise object counts, or legible text rendering. Enter Flow-GRPO, the first method to successfully integrate online reinforcement learning (RL) into flow matching models for text-to-image generation.
Unlike traditional fine-tuning, Flow-GRPO doesn’t just adjust model weights—it actively learns from human-aligned rewards (e.g., PickScore, OCR accuracy, or GenEval) to improve instruction following while preserving image quality and diversity. This means your model gets significantly better at complex tasks without drifting into reward hacking or producing unnatural outputs.
Backed by impressive results—such as GenEval accuracy jumping from 63% to 95% and text rendering accuracy rising from 59% to 92%—Flow-GRPO is designed for practitioners who need reliable, controllable, and high-fidelity image generation.
How Flow-GRPO Works: Core Innovations
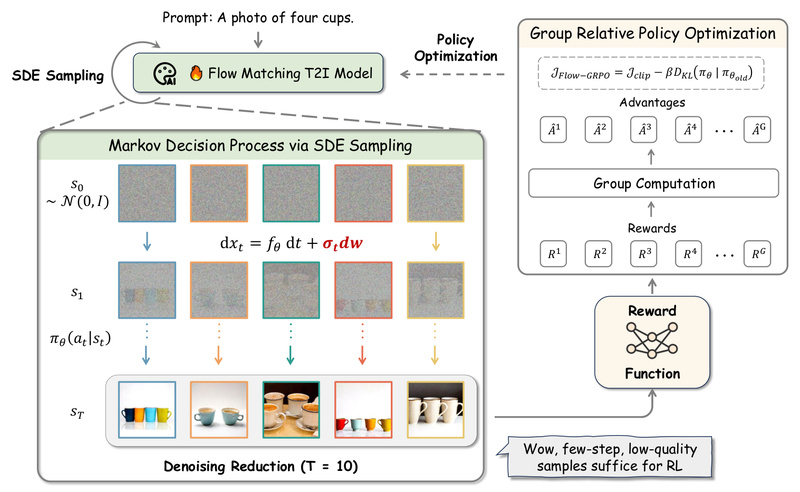
Flow-GRPO bridges a critical gap: RL requires stochasticity for exploration, but flow matching models are deterministic. To solve this, it introduces two foundational techniques.
ODE-to-SDE Conversion: Enabling Safe RL Exploration
Flow matching models typically use Ordinary Differential Equations (ODEs) for deterministic sampling. Flow-GRPO converts this into an equivalent Stochastic Differential Equation (SDE) that preserves the model’s marginal distribution at every timestep. This subtle transformation allows the model to generate multiple stochastic trajectories from the same prompt—enabling meaningful policy gradients and exploration—without altering the underlying training objective or inference behavior.
Denoising Reduction: Faster Training, Same Quality
A major bottleneck in RL-based image generation is the cost of backpropagating through dozens of denoising steps. Flow-GRPO introduces Denoising Reduction, which trains on only a subset of denoising steps (e.g., 1–2 steps per trajectory) while keeping the full inference pipeline intact.
This leads to dramatic speedups—up to 10× faster training—without sacrificing final image quality. The key insight? By focusing RL updates on critical noise levels (often mid-to-low noise), the model learns efficient policy adjustments that generalize across the entire generation process.
Ideal Use Cases
Flow-GRPO excels where precision and alignment matter most:
- Compositional Image Generation: Generating scenes with exact object counts, spatial layouts, and attribute combinations (e.g., “three children, each holding a different-colored balloon, standing in front of a white picket fence”).
- Visual Text Rendering: Producing images with accurate, legible text—critical for UI mockups, signage, or educational content. OCR-based rewards ensure text correctness.
- Human Preference Alignment: Tuning models to match subjective quality metrics like aesthetics, safety, or realism using reward models such as PickScore, UnifiedReward, or ImageReward.
If your application demands more than generic “a cat on a sofa,” Flow-GRPO offers a path to structured, reliable control.
Getting Started: Practical Workflow
Flow-GRPO is engineered for usability, with scripts supporting both single-node and multi-node training. Here’s how to begin:
- Set up your environment: Clone the repository and install dependencies. A Python 3.10 environment is recommended.
- Download a base model: Supported models include Stable Diffusion 3.5 Medium, FLUX.1-dev, Qwen-Image, and Bagel-7B.
- Configure reward servers: Since reward models (e.g., OCR, PickScore) often have conflicting dependencies, Flow-GRPO isolates them in separate services—similar to the DDPO architecture. For example:
- Use PaddleOCR for text-rendering tasks.
- Deploy UnifiedReward via
sglangfor multimodal preference scoring.
- Launch training: Use provided bash scripts like
scripts/single_node/grpo.shfor quick experiments, or scale out withscripts/multi_node/sd3.shfor large runs.
For faster iteration, try Flow-GRPO-Fast, which trains on only 1–2 denoising steps per sample and matches full Flow-GRPO performance on rewards like PickScore—while cutting training time significantly.
Limitations and Practical Considerations
While powerful, Flow-GRPO has real-world constraints:
- Hardware demands: Full-parameter fine-tuning requires at least 8×80GB GPUs. For smaller setups, LoRA-based configs (e.g.,
pickscore_bagel_lora) are available. - Precision sensitivity: Use fp16 where possible for stable log-probability estimates—but switch to bf16 for models like FLUX that don’t support fp16 inference.
- On-policy consistency: Sampling and training must use identical batch sizes and model wrappers; otherwise, importance ratios drift, destabilizing RL updates.
- Reward design: Poorly calibrated rewards can still lead to misalignment. Always validate reward behavior with
beta=0before full training.
Advanced Safeguards: GRPO-Guard
One subtle risk in RL-based generation is over-optimization: proxy rewards keep rising while actual image quality degrades. Flow-GRPO’s team observed this stems from biased importance ratios—especially at low-noise steps—where clipping fails to constrain overconfident updates.
To fix this, they introduced GRPO-Guard, which:
- Applies RatioNorm to correct distributional bias in importance weights across timesteps.
- Uses Gradient Reweight to balance contributions from different noise levels.
The result? Stable, long-horizon training where proxy and gold scores rise together—ensuring your model improves without sacrificing fidelity or diversity.
Summary
Flow-GRPO redefines what’s possible in controllable text-to-image generation. By merging online RL with flow matching through ODE-to-SDE conversion and Denoising Reduction, it delivers unprecedented accuracy on structured tasks—without the usual trade-offs in quality or diversity. With support for multiple models, reward types, and accelerated training modes, it’s a robust choice for researchers and engineers pushing the boundaries of generative AI.
Whether you’re building a design assistant, an educational content generator, or a visual reasoning benchmark, Flow-GRPO gives you the tools to make diffusion models truly understand complex instructions.