Large language models (LLMs) like ChatGPT are transforming how we interact with AI—but they often “make things up.” These fabricated, factually incorrect, or unverifiable outputs are known as hallucinations, and they pose serious risks in real-world applications where accuracy matters. Enter HaluEval: a rigorously constructed, large-scale benchmark designed specifically to help developers, researchers, and technical decision-makers evaluate how prone their LLMs are to generating hallucinations.
HaluEval isn’t just another dataset. It’s a complete toolkit—including 35,000 high-quality hallucination samples, evaluation scripts, data generation pipelines, and analysis utilities—that enables you to test, compare, and understand model reliability across critical tasks like question answering, knowledge-grounded dialogue, and text summarization. Whether you’re deploying an AI customer support agent or building a research prototype, HaluEval gives you actionable insights into one of LLMs’ most persistent failure modes.
What Makes HaluEval Different?
While many benchmarks focus on general performance, HaluEval targets hallucination head-on—a growing concern as LLMs move into production environments. Here’s what sets it apart:
1. Realistic, High-Quality Hallucination Samples
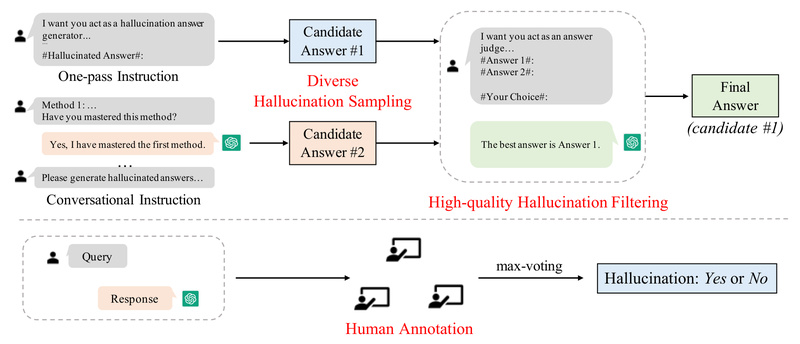
HaluEval combines human-annotated data with ChatGPT-generated hallucinations that have been carefully filtered for plausibility and difficulty. This ensures the benchmark reflects real-world failure patterns, not synthetic or obvious errors.
- 5,000 general user queries from the Alpaca instruction dataset, paired with ChatGPT responses and human-labeled hallucination flags (Yes/No).
- 30,000 task-specific samples evenly split across:
- Question Answering (based on HotpotQA)
- Knowledge-Grounded Dialogue (based on OpenDialKG)
- Text Summarization (based on CNN/Daily Mail)
Each sample includes both the ground-truth output and a hallucinated counterpart, enabling precise evaluation of detection capabilities.
2. End-to-End Tooling for Evaluation and Beyond
You don’t just get data—you get ready-to-run code for:
- Generating new hallucinated samples from your own task data
- Evaluating any LLM’s ability to detect hallucinations
- Analyzing failure patterns by topic using techniques like LDA
This means you can replicate the benchmark methodology or adapt it to your domain—without rebuilding infrastructure from scratch.
3. Practical Focus on Actionable Insights
HaluEval answers critical questions:
“Does my model hallucinate?”
“In which topics or tasks is it most prone to do so?”
“How often does this happen?”
These insights directly inform decisions about model selection, prompt engineering, or whether to integrate mitigation strategies like retrieval-augmented generation (RAG).
When Should You Use HaluEval?
HaluEval shines in scenarios where factual reliability is non-negotiable:
- Model Selection: Compare hallucination rates across LLMs (e.g., GPT-3.5 vs. open-source alternatives) before committing to a production model.
- Pre-Deployment Auditing: Test your fine-tuned or RAG-enhanced system against known hallucination patterns to catch weaknesses early.
- Research on Mitigation: Evaluate whether techniques like chain-of-thought reasoning or knowledge grounding actually reduce hallucination susceptibility.
- Domain-Specific Validation: Use HaluEval’s generation pipeline to create hallucinated samples from your internal datasets—ideal for verticals like legal, medical, or financial AI systems.
If your application involves answering user questions, summarizing documents, or holding knowledge-based conversations, HaluEval provides a standardized way to quantify risk.
Getting Started Is Straightforward
HaluEval is designed for quick adoption:
- Download the data: Four JSON files in the
data/directory contain all 35K samples with clear field labels (e.g.,hallucinated_answer,right_summary,hallucination_label). - Run evaluation: Use the provided script to test any model with OpenAI-compatible APIs:
cd evaluation python evaluate.py --task qa --model gpt-3.5-turbo
- Extend or customize: Generate hallucinations for your own seed data using the
generate.pyandfiltering.pytools—simply point them to your dataset and specify the task type.
No complex dependencies: just Python and access to an LLM API. The MIT license also allows commercial use.
Limitations to Keep in Mind
While powerful, HaluEval has boundaries worth noting:
- ChatGPT-Centric Generation: Most hallucinated samples were created and filtered using
gpt-3.5-turbo. While this reflects real-world usage, results may not generalize perfectly to models with very different behaviors (e.g., smaller open-weight LLMs). - Task Coverage: The benchmark focuses on three core tasks plus general queries. It may not capture hallucination patterns in niche domains like code generation or multimodal reasoning.
- Detection, Not Correction: HaluEval evaluates whether a model can recognize hallucinations—it doesn’t provide built-in mitigation. You’ll still need complementary approaches (e.g., RAG, fact-checking modules) to reduce hallucinations in your system.
These aren’t flaws—they’re clear scope boundaries that help you apply HaluEval where it adds the most value.
Summary
HaluEval solves a real and urgent problem: we can’t trust what we can’t measure. By providing a large-scale, task-diverse, and tool-supported benchmark for hallucination evaluation, it empowers technical teams to move beyond anecdotal “does it make stuff up?” checks and toward data-driven reliability assessments. Whether you’re building a customer-facing AI, conducting academic research, or hardening an enterprise LLM deployment, HaluEval gives you the foundation to understand—and ultimately reduce—the risks of LLM hallucinations.
With open access to both data and code, it’s not just a benchmark—it’s a springboard for building more trustworthy AI systems.