Traditional language model (LM) development follows a two-stage process: unsupervised pre-training on massive raw text corpora, followed by instruction tuning or fine-tuning to align the model with human intent. While effective, this pipeline often leaves the base model “task-naïve”—capable of predicting the next token, but unprepared for structured reasoning or diverse instruction-following scenarios out of the box.
Instruction Pre-Training flips this script. Introduced in the paper “Instruction Pre-Training: Language Models are Supervised Multitask Learners” by Microsoft’s LMOps team, this approach integrates supervised instruction-response pairs directly into the pre-training phase—not as an afterthought, but as a foundational component. By doing so, it enables language models to learn task structure, intent, and response formatting during pre-training, rather than retrofitting it later.
The result? Base models that are not only stronger in zero-shot settings but also more responsive to subsequent instruction tuning—effectively raising the performance floor for both small and large architectures.
Why It Works: Blending Supervision with Scale
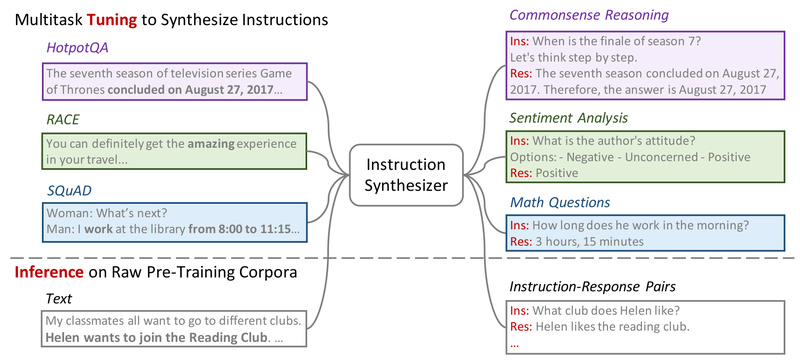
At the heart of Instruction Pre-Training is a simple yet powerful insight: pre-training doesn’t have to be purely unsupervised to be scalable. The method uses an efficient instruction synthesizer—built on open-source models—to automatically generate high-quality instruction-response pairs from raw text. These pairs span over 40 task categories, from question answering and summarization to code generation and logical reasoning.
In total, the team synthesized 200 million instruction-response examples, which were then mixed with conventional raw corpora during pre-training. This hybrid data strategy ensures the model develops both broad linguistic knowledge and task-aware reasoning capabilities from the very beginning.
Crucially, this isn’t just academic—empirical results show tangible gains:
- Models pre-trained from scratch with Instruction Pre-Training consistently outperform standard baselines.
- When applied to continual pre-training, an Llama3-8B model enhanced with this method matches or even surpasses Llama3-70B in several benchmarks—despite being nearly 9x smaller.
- These models also demonstrate greater gains from later instruction tuning, suggesting they’re better primed to absorb supervised signals.
Real-World Pain Points It Solves
For practitioners, Instruction Pre-Training addresses three persistent challenges:
1. Weak Zero-Shot Generalization
Standard base models often struggle with unseen tasks unless heavily fine-tuned. Instruction Pre-Training builds in multitask awareness early, significantly improving out-of-the-box performance without any task-specific tuning.
2. The Cost of Post-Hoc Instruction Tuning
Instruction tuning is expensive—requiring curated datasets, compute, and iteration. By front-loading task understanding into pre-training, Instruction Pre-Training reduces the data and tuning effort needed later, accelerating development cycles.
3. The Small-vs-Large Model Gap
Small models are attractive for deployment but typically lag far behind larger ones in reasoning ability. Instruction Pre-Training narrows this gap dramatically, enabling compact models like Llama3-8B to compete with much larger counterparts—making high performance more accessible and cost-effective.
Practical Use Cases for Teams and Researchers
This method shines in several real-world scenarios:
- Building custom foundation models from scratch: If you’re training a new base model, integrating instruction-response data from day one yields a more capable, instruction-ready foundation.
- Upgrading existing open-weight LLMs: Through continual pre-training, you can enhance models like Llama3-8B with multitask supervision—boosting their reasoning and instruction-following abilities without retraining from zero.
- Creating general-purpose assistants: Teams developing AI agents or chat interfaces benefit from base models that already understand how to parse and respond to instructions, reducing reliance on extensive fine-tuning.
Getting Started
All artifacts—code, synthesized data, and trained models—are publicly available via the LMOps GitHub repository. The project is part of Microsoft’s broader LMOps initiative, which focuses on foundational technologies for building AI products with large and generative models.
Typical integration paths include:
- Initializing a new pre-training run with the provided instruction-augmented corpus.
- Continuing pre-training on an existing checkpoint (e.g., Llama3) using the Instruction Pre-Training data mixture.
- Using the released models as stronger starting points for downstream fine-tuning or RAG pipelines.
The repository also includes tooling for instruction synthesis, enabling teams to adapt the framework to domain-specific corpora if needed.
Limitations and Considerations
While powerful, Instruction Pre-Training isn’t a silver bullet:
- The quality of the final model depends heavily on the instruction synthesizer—if the generated tasks are noisy or misaligned, performance may suffer.
- Large-scale pre-training remains computationally intensive, requiring significant GPU/TPU resources.
- The method complements but doesn’t replace later-stage alignment techniques like RLHF or DPO. Final production models will still need safety tuning, preference optimization, and domain adaptation.
That said, by shifting supervision earlier in the pipeline, it redefines what a “base model” can be—not just a language predictor, but a multitask learner from inception.
Summary
Instruction Pre-Training represents a strategic evolution in language model development: instead of treating instruction-following as a post-hoc add-on, it bakes task understanding into the foundation. For teams seeking stronger zero-shot performance, more efficient tuning, or smaller models that punch above their weight, this approach offers a compelling path forward. With open access to models, data, and code via LMOps, adopting this technique is now within reach for researchers and engineers alike.