Imagine running a single model that can answer complex reasoning questions, understand images and text together, and generate high-quality images from prompts—all without switching between specialized architectures. That’s exactly what MMaDA (Multimodal Large Diffusion Language Models) delivers.
As AI systems grow more capable, the fragmentation of models for different modalities—text, vision, multimodal reasoning—has become a major bottleneck for developers, researchers, and product teams. Each new task often demands a separate model, increasing infrastructure costs, deployment complexity, and alignment challenges. MMaDA solves this by introducing a unified diffusion foundation model that operates seamlessly across text and images using one shared architecture.
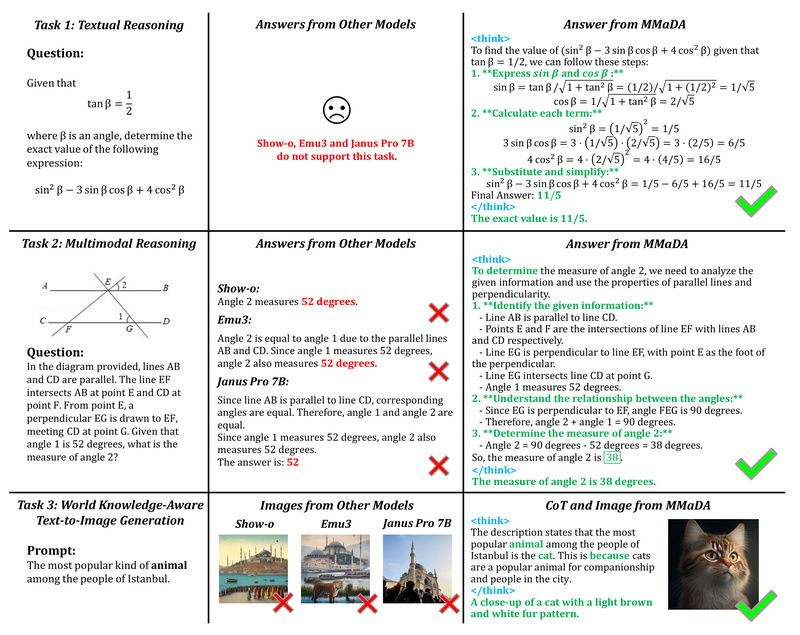
Built upon cutting-edge diffusion principles and reinforced with novel training strategies, MMaDA demonstrates strong performance across diverse benchmarks: it outperforms LLaMA-3-7B and Qwen2-7B in textual reasoning, surpasses Show-o and SEED-X in multimodal understanding, and beats SDXL and Janus in text-to-image generation. And best of all—it’s open source.
Why MMaDA Stands Out: Three Technical Breakthroughs
A Truly Modality-Agnostic Diffusion Architecture
Unlike traditional multimodal systems that stitch together separate encoders, decoders, or adapters for each data type, MMaDA uses a single, unified diffusion framework with a shared probabilistic formulation. This modality-agnostic design treats text tokens and image patches through the same generative process, enabling coherent cross-modal interactions without handcrafted bridges or modality-specific modules. The result? Simpler pipelines, fewer failure points, and smoother scaling.
Mixed Long Chain-of-Thought (CoT) Fine-Tuning
Reasoning in multimodal settings is hard—especially when models struggle to align logical steps between what they “see” and what they “say.” MMaDA tackles this with a mixed long CoT fine-tuning strategy that curates a consistent reasoning format across text-only and vision-text tasks. By standardizing how the model constructs intermediate thoughts—whether analyzing a graph or describing a scene—MMaDA ensures robust cold-start performance before reinforcement learning even begins. This alignment dramatically improves zero-shot and few-shot capabilities on complex tasks.
UniGRPO: Reinforcement Learning Built for Diffusion Models
Most RL algorithms are designed for autoregressive models, not diffusion-based ones. MMaDA introduces UniGRPO, a policy-gradient method specifically tailored for diffusion foundation models. UniGRPO leverages diversified reward signals—from factual accuracy to visual fidelity—to jointly optimize reasoning and generation in a single post-training phase. This unification eliminates the need for separate RL pipelines for text and image tasks, ensuring consistent quality improvements across the board.
Practical Applications: Where MMaDA Delivers Real Value
MMaDA isn’t just a research prototype—it’s a practical tool for real-world AI development:
- Intelligent assistants that can reason over user-uploaded screenshots, diagrams, or photos while answering follow-up questions in natural language.
- Creative workflows where designers describe complex scenes (“a cyberpunk street at dusk with neon signs in Japanese and rain-slicked pavement”) and get photorealistic outputs in one step.
- Multimodal QA systems for education, customer support, or medical imaging, where combining visual cues with textual context leads to more accurate answers.
- Model consolidation for teams tired of managing separate LLMs, vision models, and text-to-image pipelines. With MMaDA, one checkpoint handles it all.
Getting Started Is Simple
MMaDA is designed for accessibility. After cloning the repository from GitHub, you can be up and running in minutes:
- Install dependencies:
pip install -r requirements.txt
- Launch a local demo with Gradio:
python app.py
- Run inference for your use case:
- Text generation:
python generate.py - Multimodal generation: Use
inference_mmu.pywith a config and prompt file - Text-to-image: Run
inference_t2i.pywith your prompt list and generation parameters
- Text generation:
The codebase supports local inference on Apple M-series chips (via MPS) and integrates with Weights & Biases for experiment tracking—ideal for both prototyping and evaluation.
Choosing the Right MMaDA Variant
The MMaDA series offers multiple checkpoints tailored to different stages of development:
- MMaDA-8B-Base: Ideal for getting started. Supports basic text generation, image captioning, and simple image synthesis. Includes foundational “thinking” capabilities after pretraining and instruction tuning.
- MMaDA-8B-MixCoT: The go-to version for complex reasoning. Fine-tuned with mixed long CoT data, it handles intricate multimodal logic and high-fidelity generation.
- MMaDA-Parallel (A/M): Enables thinking-aware image editing, where text and image co-evolve throughout the denoising process—perfect for iterative creative tasks.
- MMaDA-8B-Max (coming soon): The full RL-finetuned powerhouse, combining UniGRPO with MixCoT for state-of-the-art performance in both reasoning and visual generation.
For most users exploring MMaDA’s potential, MMaDA-8B-MixCoT offers the best balance of capability and readiness.
Current Limitations and Practical Considerations
While MMaDA represents a major leap forward, it’s honest to note its constraints:
- Training requires significant GPU resources, especially during the multi-stage pretraining and CoT fine-tuning phases. The provided
accelerateconfigs help, but large-scale training remains compute-intensive. - Some inference workflows depend on Weights & Biases for result logging and visualization. If your environment restricts external logging, minor script adjustments may be needed.
- The UniGRPO-finetuned “Max” version is not yet public, though the Base and MixCoT checkpoints already deliver impressive results across domains.
These considerations are typical for cutting-edge foundation models—but thanks to MMaDA’s modular design and open-source release, they’re manageable for well-resourced labs or cloud-based experimentation.
Summary
MMaDA redefines what’s possible in multimodal AI by unifying text reasoning, vision understanding, and image generation into a single, coherent diffusion architecture. Its innovations—modality-agnostic design, aligned CoT reasoning, and diffusion-native RL—solve real engineering pain points: model fragmentation, inconsistent reasoning, and disjointed training pipelines.
Whether you’re building next-generation AI assistants, creative tools, or research prototypes, MMaDA offers a streamlined, high-performance foundation that’s both powerful and accessible. With open-source code, clear training stages, and multiple ready-to-use checkpoints, it’s never been easier to experiment with a truly unified multimodal model.