In today’s data-driven world, extracting structured, actionable insights from digital documents—such as invoices, reports, scientific papers, or web pages—is a common yet challenging task. Traditional approaches rely heavily on optical character recognition (OCR) to convert document images into machine-readable text before analysis. However, OCR pipelines are brittle: they struggle with complex layouts, low-resolution scans, multilingual content, and visual elements like tables or charts.
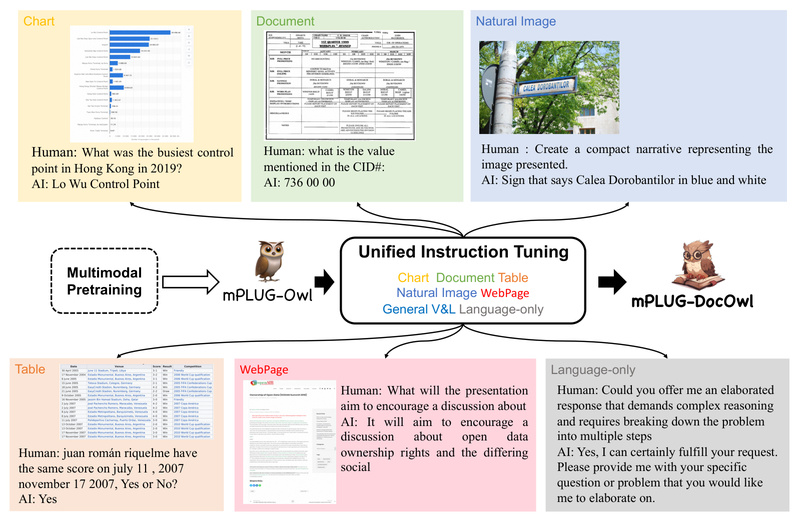
Enter mPLUG-DocOwl, a modularized multimodal large language model (MLLM) developed by Alibaba Group specifically for OCR-free document understanding. Unlike general-purpose vision-language models, mPLUG-DocOwl is purpose-built to comprehend rich visual-textual document structures directly from images—no OCR preprocessing required. Based on the foundational mPLUG-Owl architecture, it delivers strong zero-shot performance on real-world document tasks while maintaining broad generalization across downstream applications.
For technical decision-makers evaluating AI solutions for document automation, knowledge extraction, or intelligent assistants, mPLUG-DocOwl offers a compelling combination of accuracy, flexibility, and open accessibility.
Why OCR-Free Document Understanding Matters
Many enterprise and research workflows involve processing document images where text is embedded within complex visual contexts—think multi-column PDFs, financial statements with nested tables, or scientific diagrams with captions and annotations. OCR-based systems often fail to preserve spatial relationships, misread stylized fonts, or completely miss non-text elements critical to understanding.
mPLUG-DocOwl bypasses these limitations by treating the entire document image as a visual input to a multimodal model trained to “read” and reason about layout, typography, and semantics simultaneously. This approach preserves the document’s original structure and meaning, enabling more reliable question answering, information extraction, and content summarization—especially in zero-shot or few-shot settings.
Key Capabilities and Technical Strengths
Unified Instruction Tuning Across Diverse Tasks
mPLUG-DocOwl is trained using a unified instruction tuning strategy that combines three data sources:
- Pure language instructions
- General vision-and-language pairs
- A large-scale, in-house document instruction tuning dataset covering tables, forms, charts, and dense text blocks
This heterogeneous training enables the model to follow complex instructions like “Extract the total amount from this invoice” or “Compare the trends shown in these two charts” without task-specific fine-tuning.
Strong Zero-Shot and Generalization Performance
Evaluated on benchmarks such as DocVQA, InfoVQA, ChartQA, and TextVQA, mPLUG-DocOwl outperforms existing MLLMs in OCR-free settings. Notably, it generalizes well to unseen document types and downstream tasks—even without additional training—making it ideal for rapid prototyping or deployment in dynamic environments.
Multiple Model Variants for Different Needs
The mPLUG-DocOwl family includes several specialized versions:
- mPLUG-DocOwl 1.5: An 8B-parameter model achieving state-of-the-art results on single-page document understanding (e.g., DocVQQA: 82.2)
- mPLUG-DocOwl2: Optimized for multi-page documents, compressing each page into just 324 visual tokens while preserving high-resolution detail
- TinyChart: A compact 3B model excelling at chart understanding with program-of-thought reasoning (ChartQA score: 83.6, surpassing GPT-4V and Gemini Ultra)
- mPLUG-PaperOwl: Specialized for scientific diagram analysis, trained on 447K high-resolution figures
These variants allow teams to choose the right balance of performance, speed, and resource usage.
Practical Use Cases for Technical Leaders
mPLUG-DocOwl is particularly valuable in scenarios where documents are visually rich, structurally complex, or arrive in image/PDF form without editable text. Ideal applications include:
- Automated invoice and form processing in finance or logistics, where layout-aware field extraction reduces manual review
- Enterprise knowledge management, enabling semantic search and Q&A over scanned manuals, contracts, or research reports
- Scientific literature analysis, with PaperOwl extracting insights from figures and diagrams in academic papers
- Business intelligence from charts, where TinyChart interprets bar graphs, line plots, and infographics and generates executable reasoning traces
- Regulatory compliance monitoring, by analyzing dense legal or policy documents with minimal preprocessing
Critically, these use cases require no OCR pipeline setup, reducing engineering overhead and failure points.
Getting Started: Models, Code, and Fine-Tuning
Alibaba has open-sourced nearly all components of the mPLUG-DocOwl ecosystem:
- Pre-trained models are available on both Hugging Face and ModelScope, including DocOwl1.5, DocOwl2, and TinyChart
- Inference and evaluation code is publicly released, along with the LLMDoc benchmark for testing instruction compliance and document understanding
- Training datasets like DocStruct4M and DocReason25K are shared to support reproducibility
- For custom use cases, fine-tuning is supported via DeepSpeed (for DocOwl1.5) and ms-swift (for DocOwl2), enabling adaptation to proprietary document formats
Local demos can be launched using the provided scripts, and online demos are hosted on ModelScope (recommended for stability) and Hugging Face Spaces.
Limitations and Practical Considerations
While powerful, mPLUG-DocOwl is not a universal solution:
- Input quality matters: Extremely low-resolution, blurry, or heavily compressed images may degrade performance
- Specialized domains (e.g., handwritten notes, non-Latin scripts in unusual layouts) may require fine-tuning with domain-specific data
- The larger 8B models demand significant GPU memory—TinyChart or distilled variants may be preferable for edge or latency-sensitive deployments
- The Hugging Face demo, while convenient, can be unstable due to dynamic GPU allocation; ModelScope offers a more consistent experience
Nonetheless, its open nature and strong baseline performance make it a low-risk, high-reward starting point for document AI initiatives.
Summary
mPLUG-DocOwl redefines what’s possible in document understanding by eliminating dependency on OCR and leveraging multimodal reasoning to extract meaning directly from visual documents. With strong zero-shot accuracy, multiple specialized model variants, and full open-source availability—including data, code, and evaluation tools—it empowers technical teams to build robust, scalable document intelligence systems faster and more reliably. For organizations drowning in PDFs, scans, and reports, mPLUG-DocOwl isn’t just another model—it’s a pathway to automation without compromise.