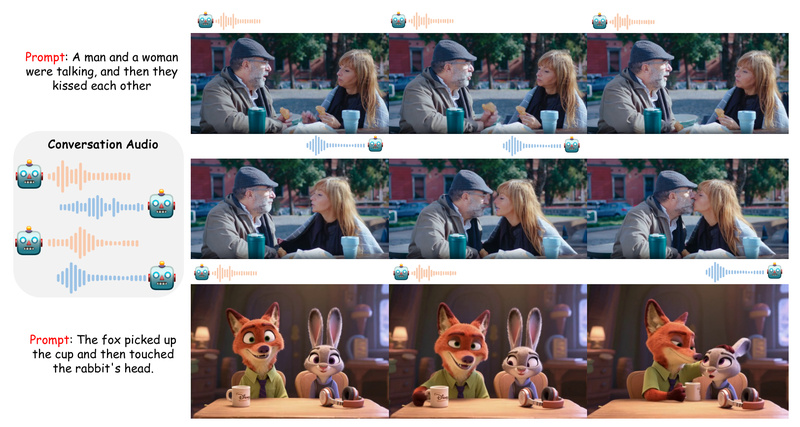
Creating lifelike videos of people talking has long been dominated by “talking head” technologies—tools that animate a single face from a reference image and an audio clip. But what if you need two, three, or more people to hold a natural conversation on screen? Traditional methods stumble here: they can’t reliably bind each audio stream to the correct speaker, often resulting in mismatched lip movements or chaotic visual output.
Enter MultiTalk, an open-source framework introduced in the NeurIPS 2025 paper “Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation.” MultiTalk isn’t just another talking-head generator—it’s the first system designed from the ground up to handle multi-person, multi-audio conversational video synthesis with accurate speaker-to-audio alignment, prompt-guided interaction control, and support for diverse content types including singing and animated characters.
For project leads, researchers, and engineers evaluating tools for synthetic media generation, MultiTalk solves a critical gap: scalable, controllable, and synchronized video creation for multi-agent scenarios—without requiring manual post-editing or complex choreography.
Why MultiTalk Solves a Real Industry Problem
Most existing audio-driven animation systems assume a 1:1 mapping: one audio track, one person. That works for solo presentations or voiceovers—but fails completely in dialogues, interviews, debates, or ensemble scenes. The core issue is incorrect audio-person binding: when multiple voices are present, older models often assign the wrong utterance to the wrong face, breaking realism.
MultiTalk introduces a novel technical solution: Label Rotary Position Embedding (L-RoPE), which explicitly encodes speaker identity into the audio conditioning pipeline. This ensures that each person in the video only speaks when their corresponding audio stream is active, with precise lip-sync and natural head/body motion.
Beyond correctness, MultiTalk also preserves instruction-following capabilities—a feature many generative video models lose during fine-tuning. By using partial parameter training and multi-task learning, it retains the ability to interpret high-level text prompts like “two scientists discussing climate data calmly” or “a cartoon duo singing a duet.”
Key Capabilities That Make MultiTalk Stand Out
Accurate Multi-Speaker Lip-Sync with Identity Binding
Unlike generic video diffusion models, MultiTalk’s L-RoPE mechanism disambiguates who is speaking at any moment, even in overlapping or rapid-turn conversations. This is essential for applications like dubbing or synthetic training data where speaker consistency matters.
Prompt-Guided Interaction Control
You don’t just feed it audio—you also provide a text prompt that defines the scene’s tone, emotion, and behavior. Want your characters to gesture while arguing? Or stay still while reciting poetry? The prompt guides body language, gaze direction, and interaction dynamics, not just lip motion.
Broad Content Generalization
MultiTalk isn’t limited to photorealistic humans. It supports:
- Realistic conversational videos
- Singing performances (with pitch and rhythm awareness)
- Stylized cartoon characters
This flexibility stems from its foundation on the Wan2.1-I2V-14B base model, which was trained on diverse visual domains.
Production-Friendly Output Options
- Resolution: 480p (single GPU) or 720p (multi-GPU)
- Aspect ratio: Arbitrary (no fixed 16:9 constraint)
- Duration: Up to 15 seconds (201 frames at 25 FPS)
- Frame rate: 25 FPS, matching broadcast standards
Hardware-Efficient Inference
Thanks to community and developer optimizations, MultiTalk can run in surprisingly lean environments:
- Single RTX 4090: Full 480p generation with TeaCache acceleration (~2–3× speedup)
- As low as 8GB VRAM: Via the Wan2GP community adaptation
- INT8 quantization: Reduces memory use while preserving sync quality
- LoRA acceleration: Achieves usable results in just 4–8 sampling steps with FusionX or lightx2v adapters
Practical Use Cases Where MultiTalk Delivers Value
1. Multi-Character Video Dubbing
Film localization teams can generate dubbed scenes with multiple actors speaking in sync, avoiding costly manual re-animation. Each voice track maps cleanly to its character.
2. Educational & Training Simulations
Create interactive dialogue videos for language learning (“Practice this job interview with two speakers”) or soft-skills training (“Observe how this negotiation unfolds”).
3. Synthetic Data for AI Research
Generate large-scale datasets of multi-person interactions for training perception models in robotics, surveillance, or social AI—complete with ground-truth audio-visual alignment.
4. Gaming & Virtual Avatars
Build dynamic NPC conversations in games or customer service bots where multiple virtual agents respond coherently to user input, driven by real-time TTS.
5. Animated Content Creation
Indie creators can produce short animated dialogues or music videos without frame-by-frame animation—just provide character designs, voice lines, and a behavioral prompt.
Getting Started: What You Need to Provide
Using MultiTalk is straightforward:
- Reference images: One per speaking character (real or cartoon).
- Audio inputs: Separate WAV files for each speaker (or use built-in TTS with text-to-speech prompts).
- A text prompt: Describes the interaction (e.g., “two friends excitedly discussing a concert”).
The system then generates a video where each person moves naturally, speaks only when their audio plays, and behaves according to your prompt.
For rapid prototyping, a Gradio demo is available, and integration into ComfyUI and Replicate simplifies deployment. Even low-resource users can run it via community-provided Colab notebooks or the Wan2GP toolchain.
Limitations and Practical Considerations
While powerful, MultiTalk has realistic constraints:
- 720p output currently requires multi-GPU setups (e.g., 8× A100). Single-GPU users are limited to 480p.
- Optimal prompt fidelity occurs at 81 frames (~3.2 seconds). Longer videos (up to 15s) are possible but may show reduced adherence to complex prompts.
- Color drift in long sequences can occur, though the built-in APG (Adaptive Prompt Guidance) module mitigates tone inconsistencies.
- Pre-trained audio encoders are optimized for Chinese, though the architecture is language-agnostic. Users working with other languages may need to adapt or fine-tune the wav2vec2 component.
These trade-offs are well-documented, and the project’s active roadmap (including LCM distillation and sparse attention) suggests ongoing improvements in speed and quality.
Summary
MultiTalk represents a significant leap in audio-driven video generation—not by making single-person animation better, but by solving the multi-person problem correctly. With its speaker-binding innovation, prompt-aware control, and support for real-world production constraints, it fills a void that traditional talking-head systems cannot address.
For anyone building applications involving multi-agent interactions—whether in entertainment, education, research, or AI training—MultiTalk offers a robust, open, and increasingly accessible path to realistic, synchronized conversational video.