In today’s AI landscape, most multimodal systems are built by stitching together specialized models—separate vision encoders, audio processors, and language models—each pretrained independently and fine-tuned in isolation. This approach introduces complexity, inconsistency, and scalability bottlenecks. Enter ONE-PEACE: a unified, general-purpose representation model that natively handles vision, audio, and language within a single architecture—without initializing from any pretrained vision or language models.
Developed by OFA-Sys and detailed in the paper “ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities”, this 4-billion-parameter model delivers state-of-the-art performance across a wide spectrum of unimodal and multimodal benchmarks out of the box. More importantly, it offers a scalable, extensible design that can theoretically support any new modality—making it a compelling choice for technical leaders planning long-term, future-proof AI infrastructure.
A Unified Architecture Built for Extensibility
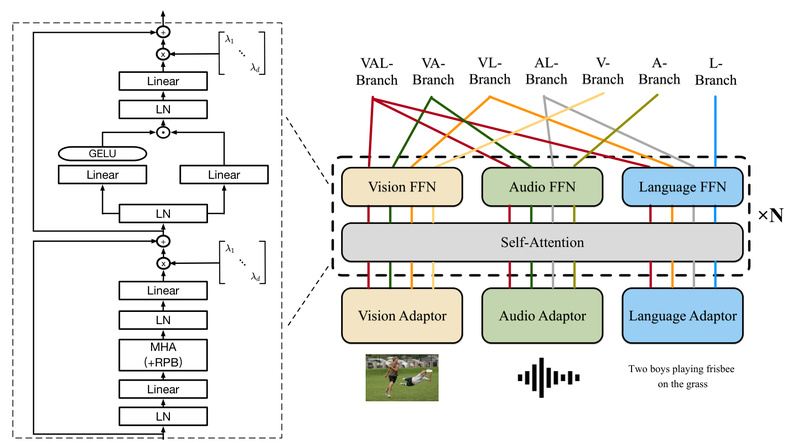
At the heart of ONE-PEACE lies a modality-agnostic transformer backbone composed of three key components:
- Modality Adapters: Lightweight modules that project raw inputs (images, audio waveforms, text tokens) into a shared latent space.
- Shared Self-Attention Layers: A core transformer stack that processes all modalities jointly, enabling rich cross-modal interactions.
- Modality-Specific Feed-Forward Networks (FFNs): Task-tailored layers that preserve modality-specific characteristics while benefiting from shared representations.
This design means adding a new modality—say, LiDAR point clouds or physiological signals—requires only implementing a new adapter and FFN, without retraining the entire model. The shared attention layers inherently support cross-modal fusion, allowing the model to learn relationships even between modalities that never co-occurred during training.
Crucially, ONE-PEACE is trained from scratch using two modality-agnostic pretraining objectives:
- Cross-modal aligning contrast: Pulls semantically related samples from different modalities (e.g., a barking dog image and its audio) closer in embedding space.
- Intra-modal denoising contrast: Encourages the model to reconstruct clean representations from corrupted inputs within each modality, preserving fine-grained details.
Together, these tasks create a cohesive semantic space where vision, audio, and language naturally align—enabling powerful zero-shot capabilities.
Strong Performance Without Specialized Pretraining
Despite starting from random initialization, ONE-PEACE achieves competitive or leading results across diverse benchmarks without relying on pretrained backbones like CLIP, Whisper, or BERT. Here are highlights:
Vision Tasks
- ImageNet-1K classification: 89.8% top-1 accuracy
- ADE20K semantic segmentation: 63.0 mIoU (multi-scale)
- COCO object detection: 60.4 AP (bounding box)
- Kinetics-400 video action recognition: 88.1% top-1 accuracy
Audio Tasks
- ESC-50 zero-shot audio classification: 91.8% accuracy
- AudioCaps text-to-audio retrieval: 51.0% R@1
- AVQA (audio-based visual question answering): 92.2% accuracy
Vision-Language & Cross-Modal Tasks
- Flickr30K image-to-text retrieval: 97.6% R@1
- RefCOCO+ visual grounding: 92.21% accuracy (testA)
- VQAv2 visual question answering: 82.6% accuracy
Notably, ONE-PEACE excels in emergent zero-shot retrieval—successfully aligning modalities never paired during training, such as retrieving images using only audio queries, even when the training data contained no audio-image examples for those concepts.
Real-World Applications That Benefit from ONE-PEACE
For technical decision-makers, ONE-PEACE solves three critical pain points:
1. Unified Infrastructure for Multimodal Products
Instead of maintaining separate pipelines for image search, voice commands, and text understanding, teams can deploy a single model that handles all three. This reduces operational overhead, simplifies versioning, and ensures consistent semantic alignment across features.
2. Cross-Modal Search Without Paired Data
Imagine enabling users to search a photo library using a sound clip (“find pictures of barking dogs”) or combining spoken queries with rough sketches. ONE-PEACE’s zero-shot cross-modal alignment makes this possible—even if your training data lacks direct audio-image pairs for those queries.
3. Future-Proof Extensibility
If your roadmap includes new sensor modalities (e.g., thermal imaging, radar, or biomedical signals), ONE-PEACE’s adapter-based architecture allows non-disruptive integration. You extend the model without discarding existing investments.
Getting Started Is Simple
ONE-PEACE provides a clean, Pythonic API for rapid experimentation. With just a few lines, you can extract embeddings, compute cross-modal similarities, or run downstream tasks:
from one_peace.models import from_pretrained
model = from_pretrained("ONE-PEACE", device="cuda")
text_feats = model.extract_text_features(model.process_text(["dog"]))
image_feats = model.extract_image_features(model.process_image(["dog.jpg"]))
similarity = image_feats @ text_feats.T # Cosine similarity
The repository includes:
- Pretrained and task-specific checkpoints (e.g.,
ONE-PEACE_Grounding,ONE-PEACE_VGGSound) - Fine-tuning scripts for vision, audio, and multimodal tasks
- An interactive Hugging Face Spaces demo supporting queries like audio + text → image
Installation requires Python 3.6–3.10, PyTorch ≥1.10, and CUDA ≥10.2—standard for most deep learning environments.
Key Limitations and Practical Considerations
While powerful, ONE-PEACE isn’t a one-size-fits-all solution:
- Model size: At 4B parameters, it demands significant GPU memory (~24GB+ for inference in float32). Quantization or distillation may be needed for edge deployment.
- No CPU-first design: Optimized for GPU inference; real-time CPU usage is impractical.
- Python version constraints: Requires Python ≤3.10, which may conflict with newer toolchains.
These trade-offs are typical for large multimodal models, but they mean ONE-PEACE is best suited for cloud-based applications or research environments with access to capable hardware.
Summary
ONE-PEACE redefines what’s possible in multimodal AI by proving that a single, from-scratch model can outperform specialized systems across vision, audio, and language—while offering a clear path to support any future modality. For teams building next-generation AI products that demand semantic consistency, operational simplicity, and long-term extensibility, ONE-PEACE isn’t just an option—it’s a strategic enabler.
With its open-source release, comprehensive APIs, and strong zero-shot capabilities, it lowers the barrier to deploying truly integrated multimodal intelligence—today.