Image-to-image translation is a powerful capability in computer vision—but real-world applications often face two stubborn roadblocks: the absence of aligned…

Image-to-image translation is a powerful capability in computer vision—but real-world applications often face two stubborn roadblocks: the absence of aligned…

If you’re building applications that involve comparing, aligning, searching, or evaluating text—whether in natural language processing (NLP), bioinformatics, or computational…
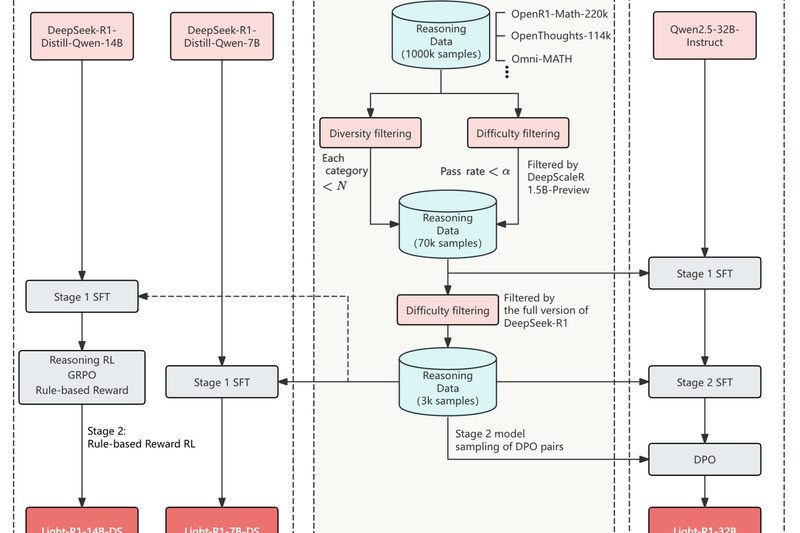
If you’re building AI systems that require reliable, step-by-step mathematical reasoning—but don’t have access to proprietary datasets, massive compute budgets,…
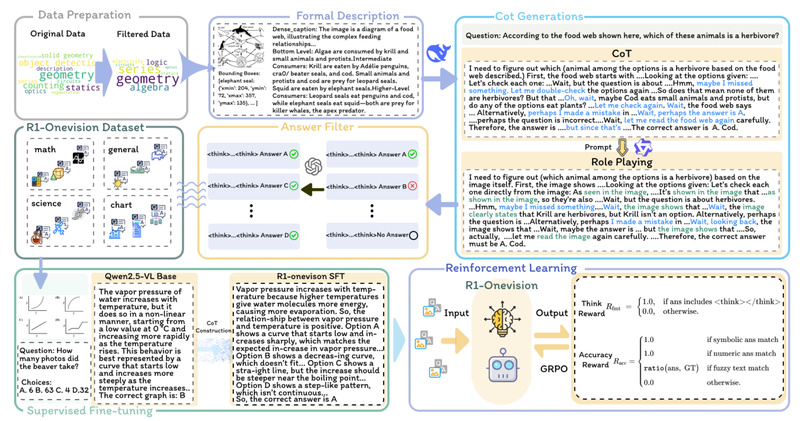
In today’s AI landscape, most multimodal models can describe what’s in an image—but few can reason through it. If your…

In an era where AI systems are increasingly tasked with more than just answering questions—writing code, debugging, and even conducting…
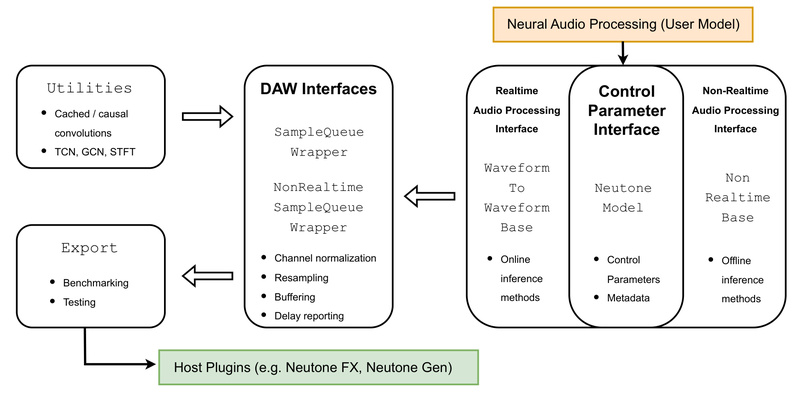
Bringing neural audio models from research notebooks into real-world creative environments has long been a bottleneck for AI audio developers.…
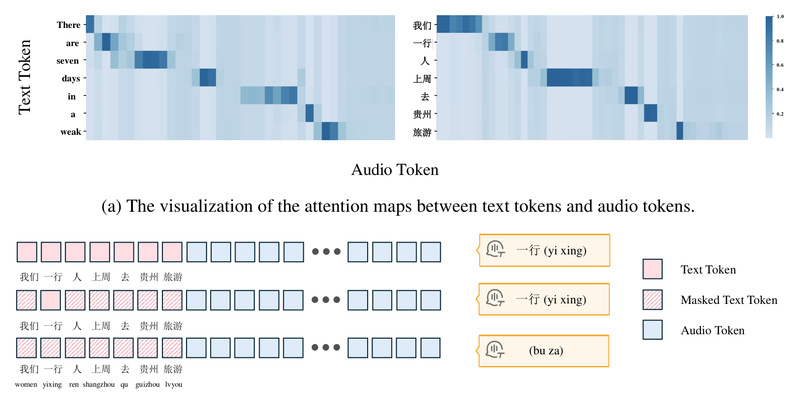
Voice interaction is becoming a cornerstone of modern human-computer interfaces—whether through smart assistants, customer service bots, or real-time translation tools.…
Neural Radiance Fields (NeRF) have revolutionized photorealistic 3D scene reconstruction—but they come with well-known limitations. One major pain point: when…
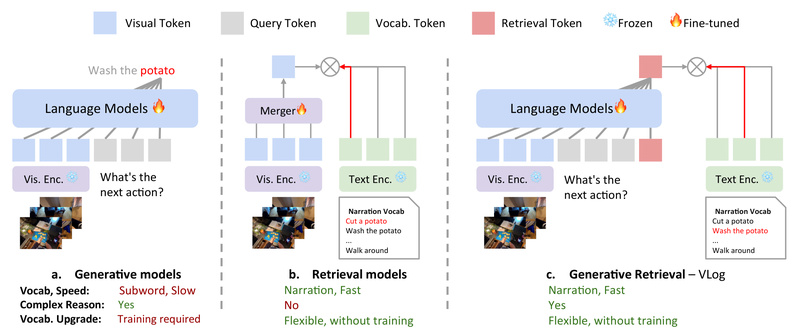
Understanding what happens in videos—especially those capturing everyday human activities—is a core challenge in AI. Most existing video-language models generate…

As Large Vision-Language Models (LVLMs) grow increasingly capable—and increasingly complex—evaluating their multimodal reasoning, perception, and reliability has become a significant…