If you’re building or evaluating text-to-image systems that demand both speed and visual fidelity, Decoupled DMD offers a breakthrough in…
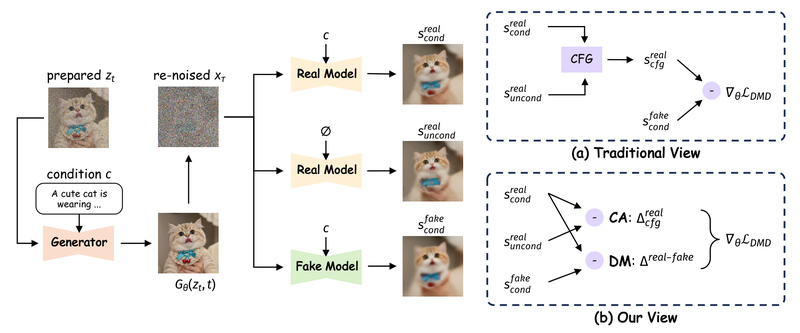
If you’re building or evaluating text-to-image systems that demand both speed and visual fidelity, Decoupled DMD offers a breakthrough in…
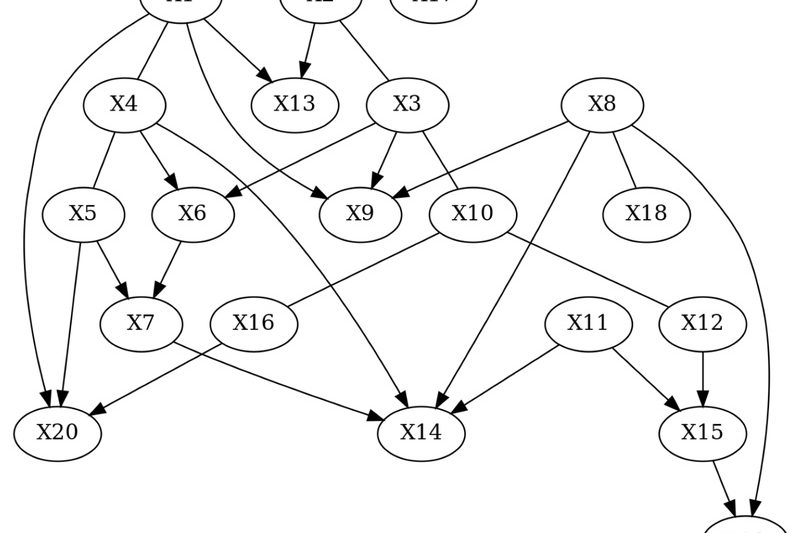
In many real-world scenarios—whether you’re analyzing patient outcomes in healthcare, consumer behavior in economics, or system failures in engineering—you can’t…
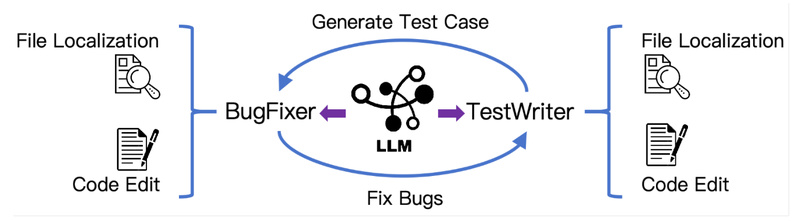
Kimi-Dev is a state-of-the-art open-source large language model (LLM) purpose-built for software engineering tasks. Unlike generic coding assistants that generate…

Optimizing complex systems—whether machine learning models, database configurations, or compiler flags—often feels like navigating a dark room: you know the…
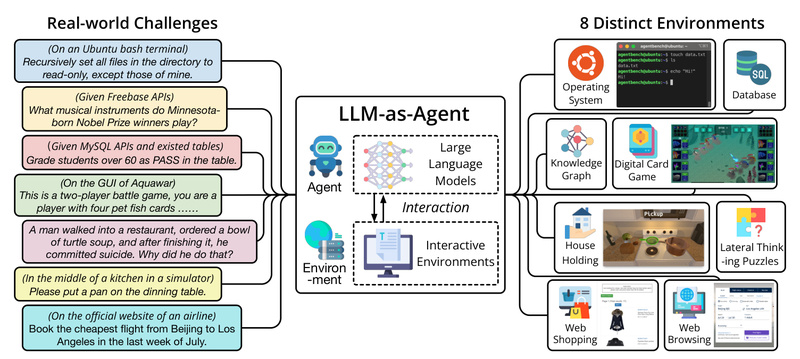
As large language models (LLMs) increasingly power autonomous agents—from customer service bots to system administration tools—a critical question arises: Can…
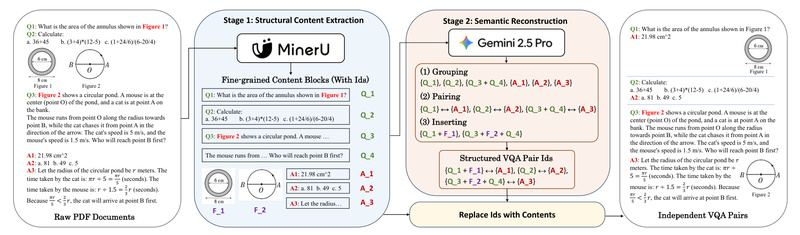
Large Language Models (LLMs) and multimodal systems increasingly demand high-quality, human-authored supervision data—especially for tasks requiring reasoning, visual understanding, and…

For decades, automatic speech recognition (ASR) has flourished in high-resource languages like English, Spanish, or Mandarin. But for the vast…
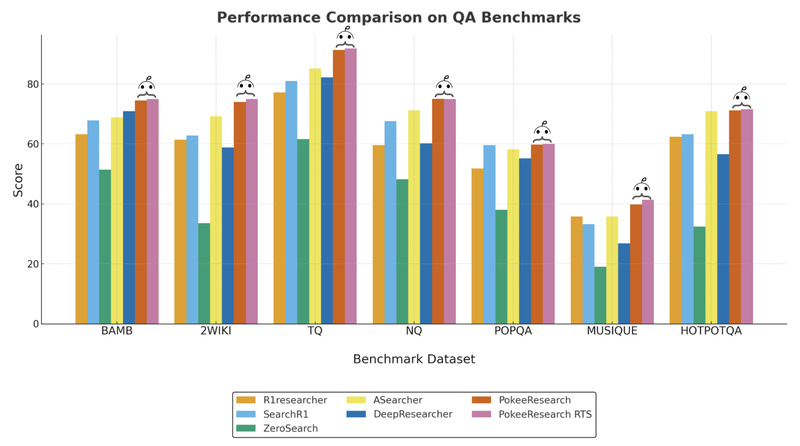
In today’s fast-moving technical and research environments, teams need reliable, up-to-date answers to complex questions—without the black-box limitations or high…

Imagine needing realistic, physics-compliant character movement for a game, simulation, or robotics project—but without the months of trial, error, and…
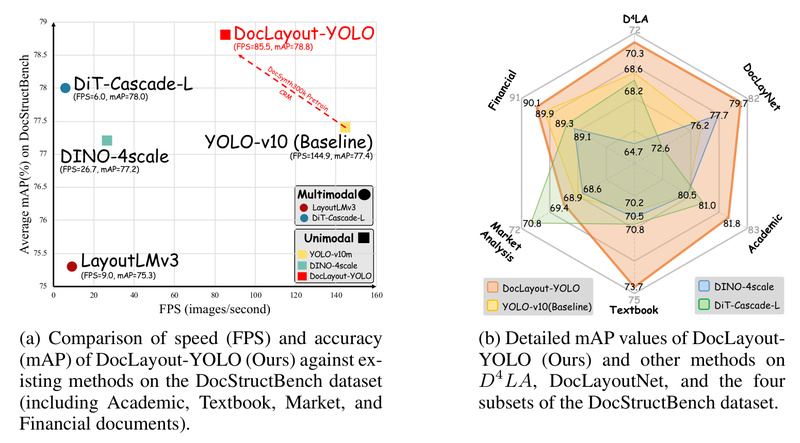
Document layout analysis (DLA) is a foundational task in building real-world document understanding systems—whether you’re extracting structured data from invoices,…