In modern data-driven operations—whether monitoring industrial sensors, analyzing financial transactions, or securing IT infrastructure—unexpected anomalies can signal critical failures, fraud,…
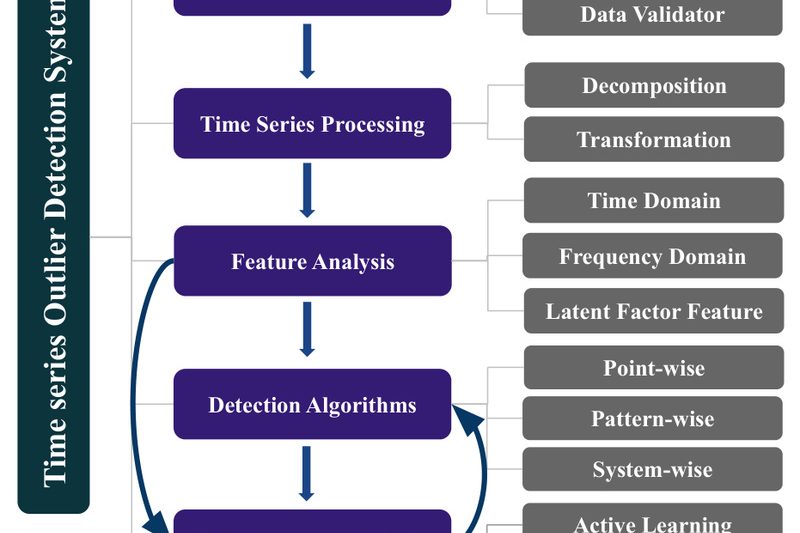
In modern data-driven operations—whether monitoring industrial sensors, analyzing financial transactions, or securing IT infrastructure—unexpected anomalies can signal critical failures, fraud,…
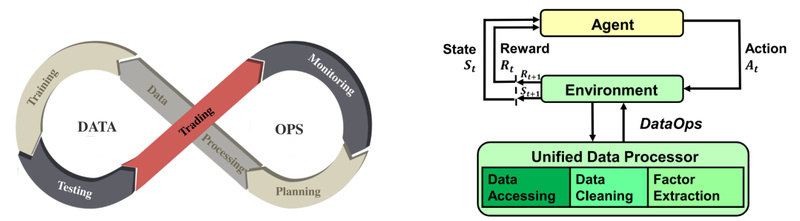
Financial markets are among the most complex and noisy environments for deploying reinforcement learning (RL) agents. Unlike simulated games or…
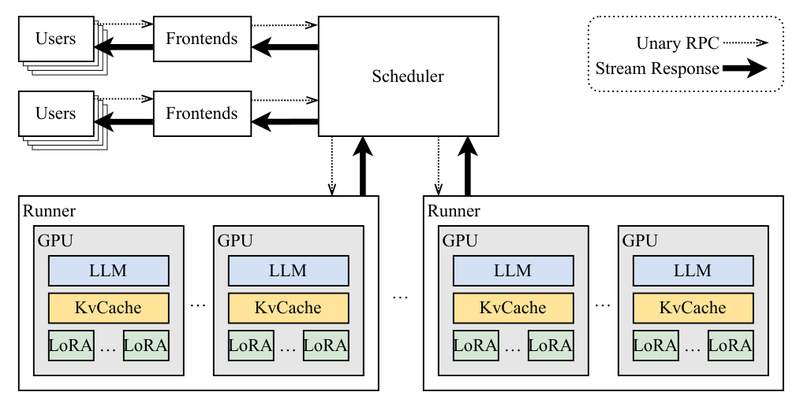
Deploying multiple fine-tuned large language models (LLMs) used to mean multiplying your GPU costs—until Punica arrived. If you’re managing dozens…

Video generation using diffusion models has long suffered from a crippling bottleneck: speed. Even the most advanced models can take…
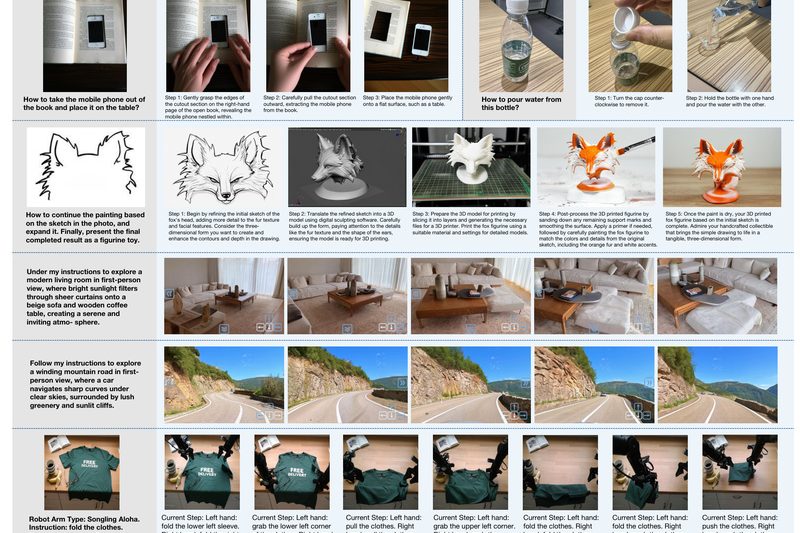
Imagine a single AI model that doesn’t just “see” or “read”—but seamlessly blends images and text in both input and…
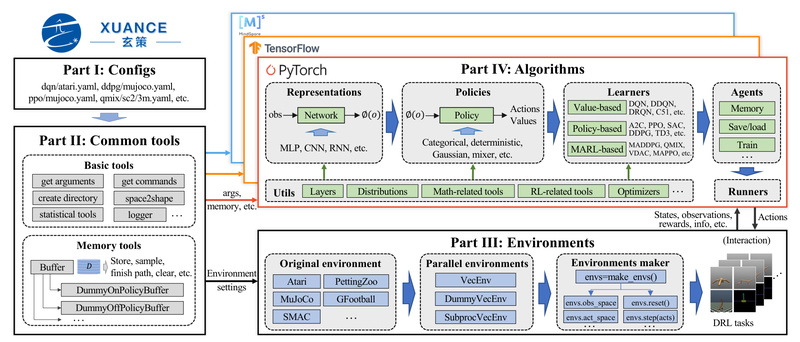
Deep reinforcement learning (DRL) holds immense promise—from robotic control and autonomous systems to multi-agent coordination and game AI. Yet for…
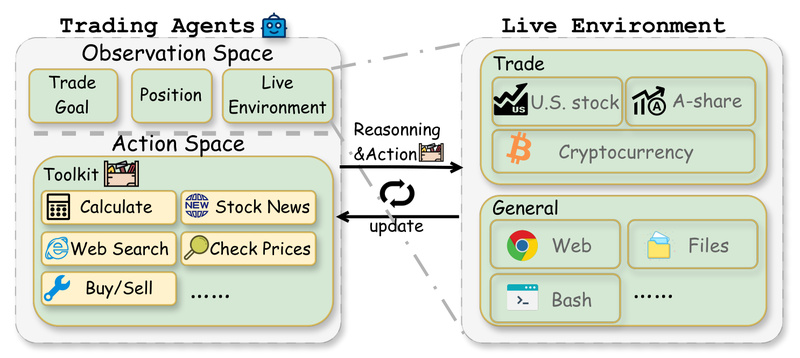
Evaluating whether large language models (LLMs) can truly function as autonomous decision-makers in dynamic, real-world environments remains a fundamental challenge…

OmDet is a breakthrough in open-vocabulary object detection (OVD)—a vision-language paradigm that enables models to recognize not just pre-defined object…
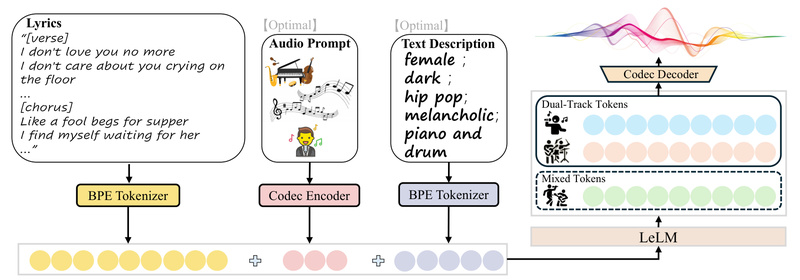
LeVo is a breakthrough in open-source AI music generation. Unlike many existing tools that produce fragmented, low-quality, or inconsistent audio,…
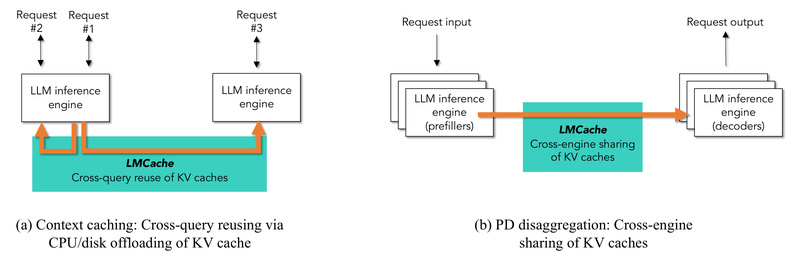
Deploying large language models (LLMs) at scale introduces a familiar bottleneck: the growing size of Key-Value (KV) caches rapidly outpaces…