Natural Language Processing (NLP) has been revolutionized by pre-trained language models (PLMs), but turning these powerful models into real-world applications…
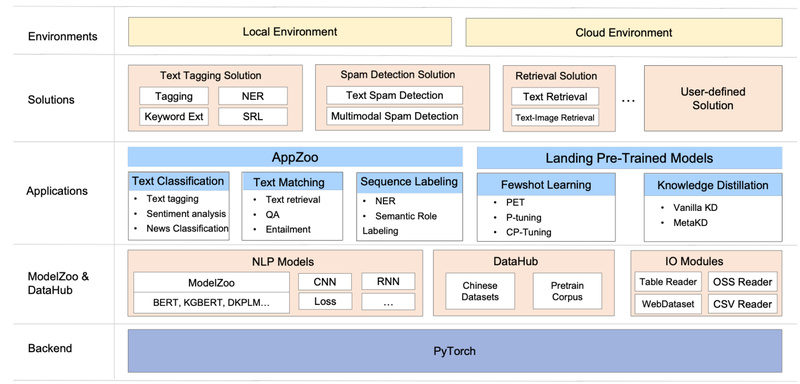
Natural Language Processing (NLP) has been revolutionized by pre-trained language models (PLMs), but turning these powerful models into real-world applications…
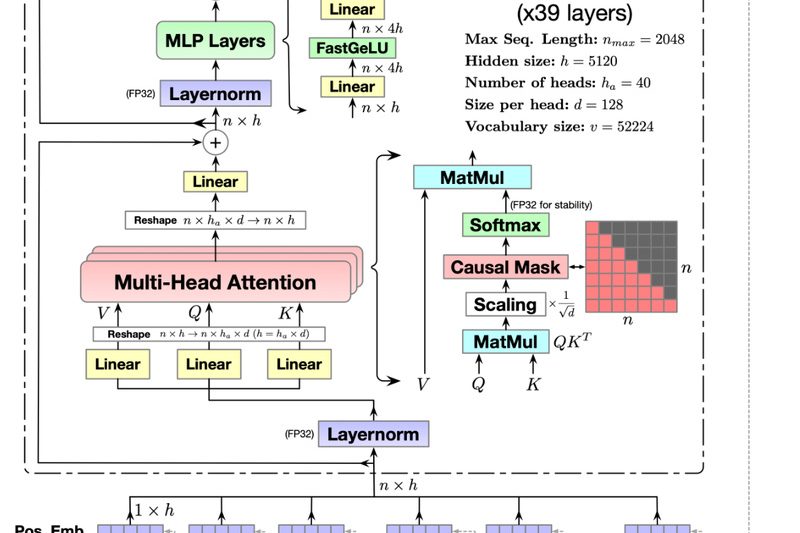
For software teams working across multiple programming languages—or developers tired of vendor lock-in with proprietary AI coding tools—CodeGeeX offers a…
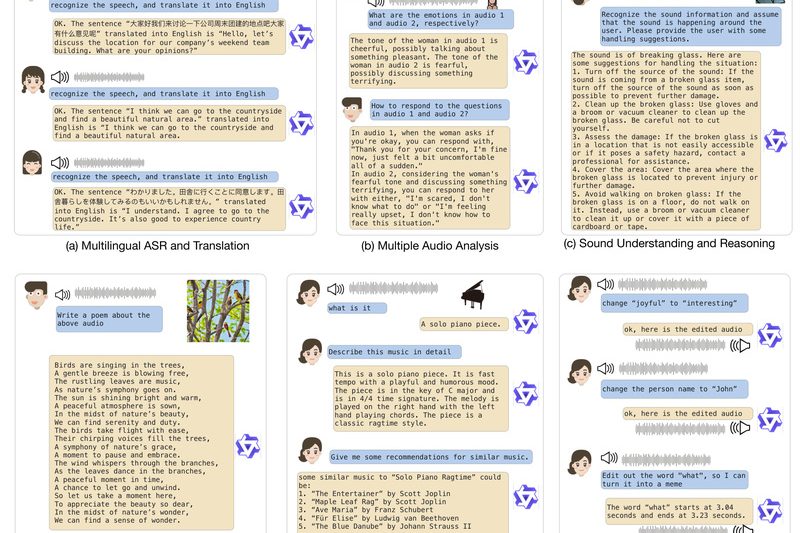
Audio is one of the richest yet most fragmented modalities in artificial intelligence. Traditional systems often require separate models for…
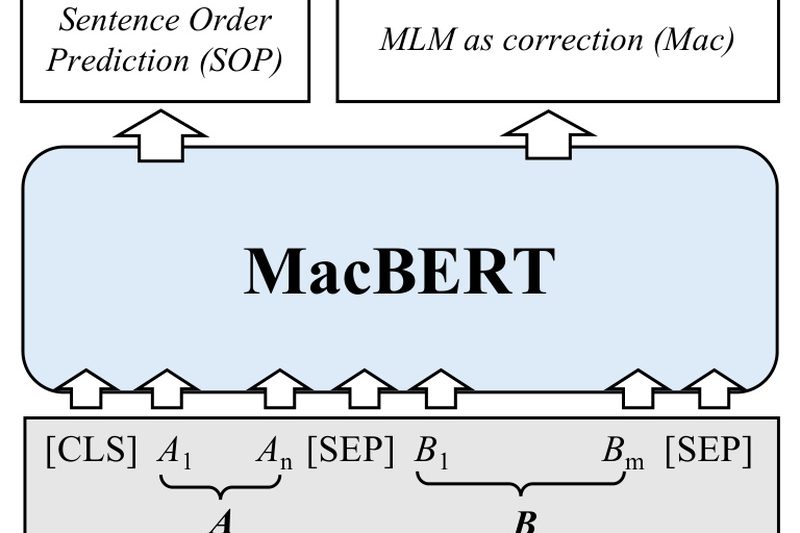
Chinese-BERT-wwm is a family of pre-trained language models specifically engineered to overcome a key limitation of the original BERT when…

Multimodal AI models like OpenAI’s CLIP have transformed how developers build systems that understand both images and text. But there’s…

XLNet is a breakthrough in language modeling that effectively bridges the gap between autoregressive (AR) and autoencoding (AE) pretraining paradigms.…

In the rapidly evolving landscape of multimodal artificial intelligence, developers and technical decision-makers need models that go beyond basic image…
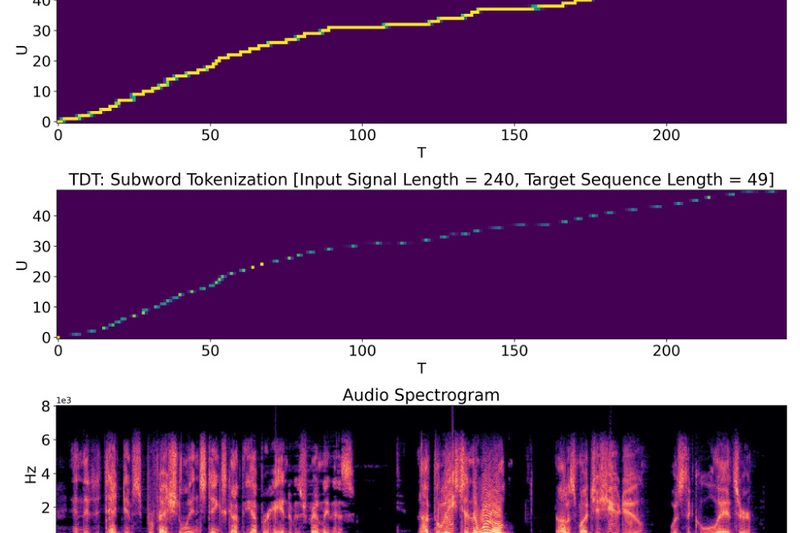
NVIDIA NeMo is a cloud-native, open-source framework designed for developers, research engineers, and technical decision-makers who need to build, customize,…
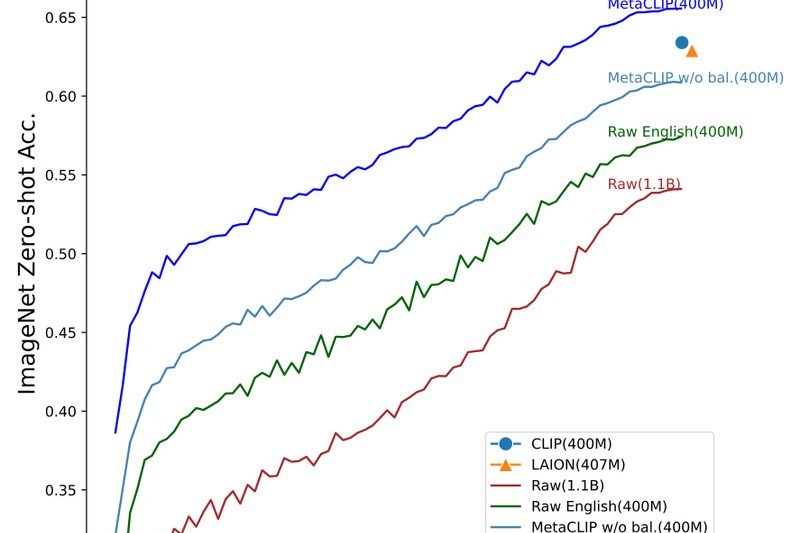
If you’ve worked with OpenAI’s CLIP, you know its power—but also its opacity. CLIP revolutionized zero-shot vision-language understanding, yet it…

Imagine you’ve fine-tuned a language model using a standard Supervised Fine-Tuning (SFT) dataset—like Zephyr-7B on UltraChat—but you don’t have access…