Imagine you need to generate a cohesive set of images—say, a film storyboard, a series of product design mockups, or…
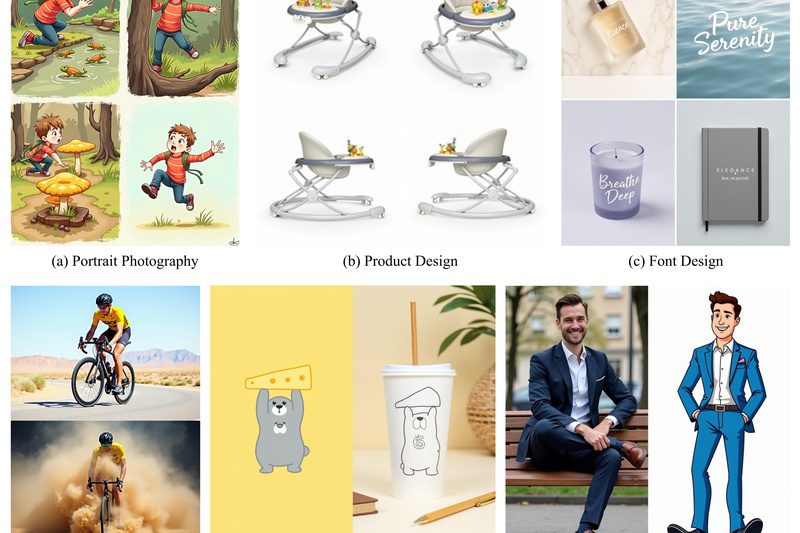
Imagine you need to generate a cohesive set of images—say, a film storyboard, a series of product design mockups, or…
BiRefNet (Bilateral Reference Network) is a state-of-the-art deep learning model designed specifically for high-resolution dichotomous image segmentation (DIS)—a task that…
If you’re a technical decision-maker evaluating options for building or fine-tuning a conversational AI system, you know that high-quality instruction-following…
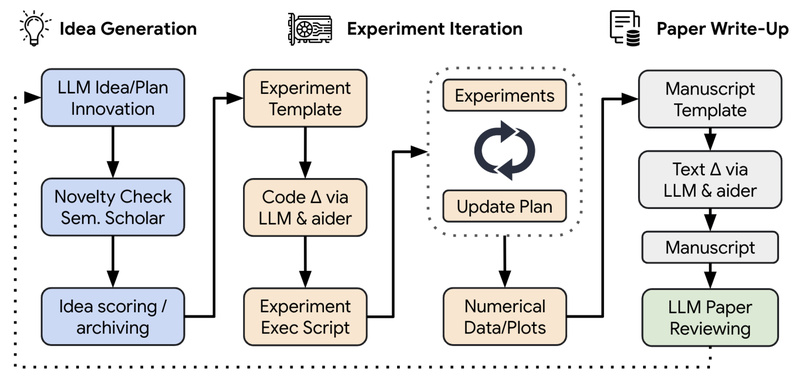
Imagine a system that doesn’t just assist scientists—but acts as one. It generates novel research hypotheses, writes executable code, runs…
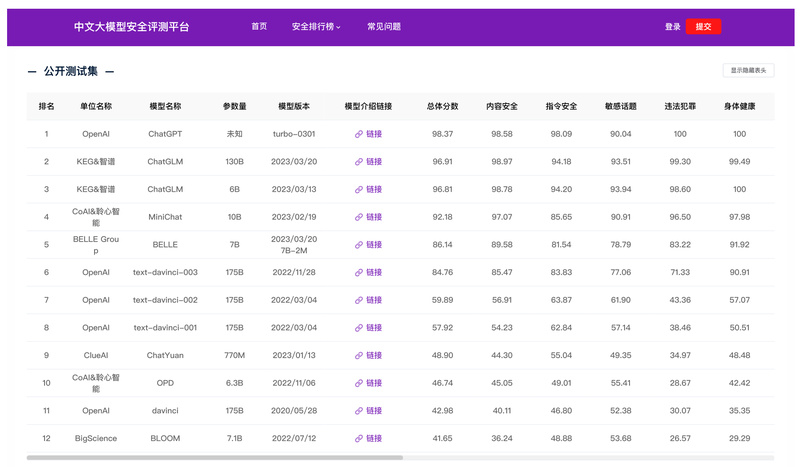
As large language models (LLMs) become increasingly embedded in real-world applications—especially in Chinese-speaking regions—ensuring their safety has never been more…

If you’ve ever struggled to generate marketing visuals with legible multilingual text—or tried to edit a product image only to…

HunyuanImage-3.0 is a groundbreaking open-source image generation model developed by Tencent. Unlike traditional diffusion-based approaches, it builds a native multimodal…
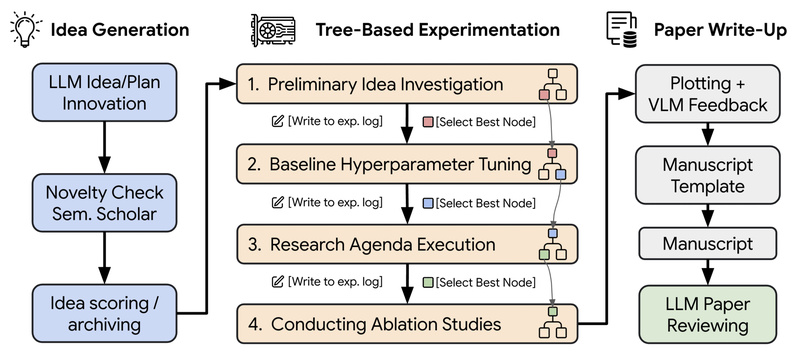
In an era where AI is reshaping how knowledge is created, AI-Scientist-v2 emerges as a breakthrough system that autonomously conducts…
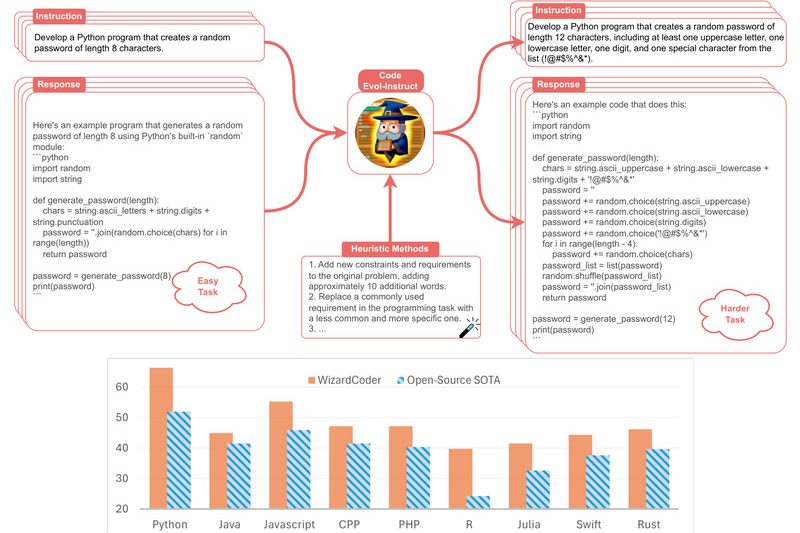
WizardCoder is a state-of-the-art open-source Code Large Language Model (Code LLM) that delivers exceptional performance on code generation tasks—often surpassing…
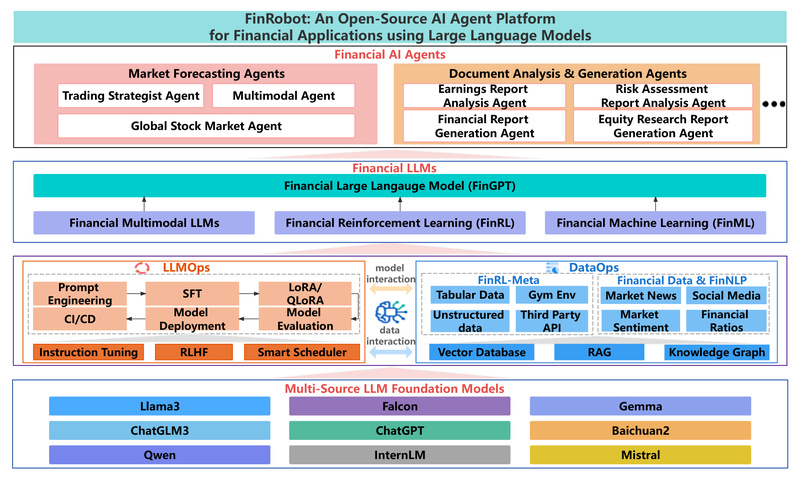
In today’s fast-moving financial landscape, professionals and developers alike are eager to harness the power of large language models (LLMs).…