If you’ve ever tried building a natural language interface to a relational database, you know the real bottleneck isn’t the…
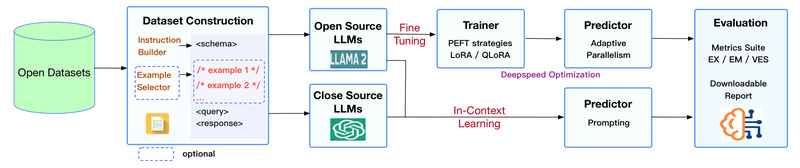
If you’ve ever tried building a natural language interface to a relational database, you know the real bottleneck isn’t the…
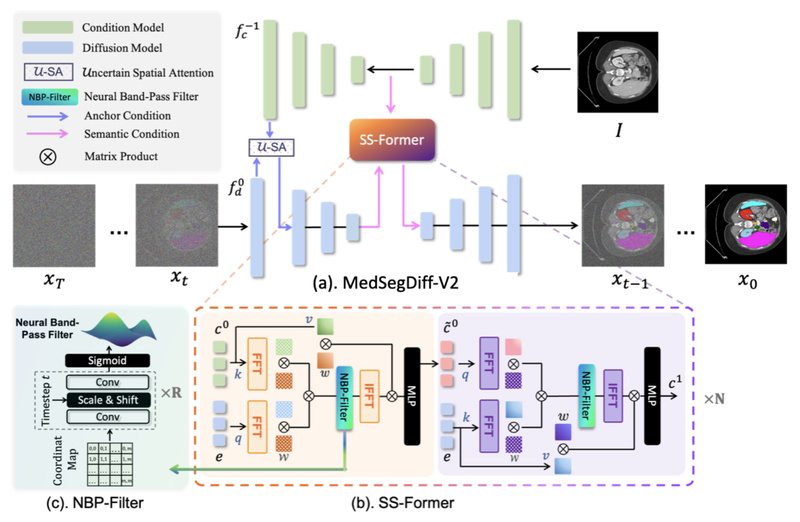
Medical image segmentation—the process of delineating organs, tumors, or tissues in scans like MRI or dermoscopic images—is a foundational task…
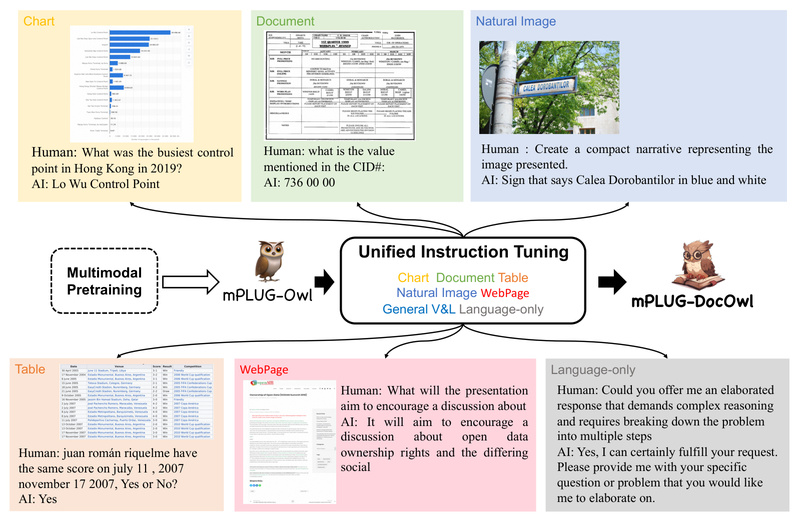
In today’s data-driven world, extracting structured, actionable insights from digital documents—such as invoices, reports, scientific papers, or web pages—is a…
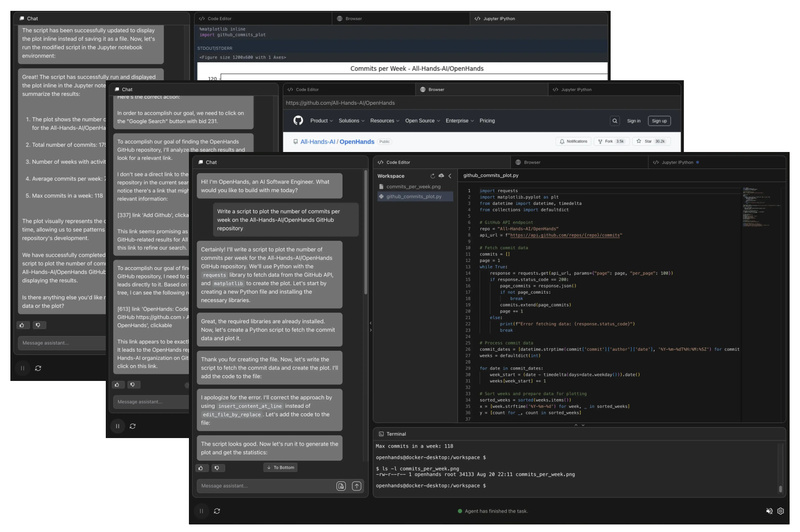
In today’s fast-paced software landscape, developers are under constant pressure to write, test, debug, and deploy code faster than ever—often…
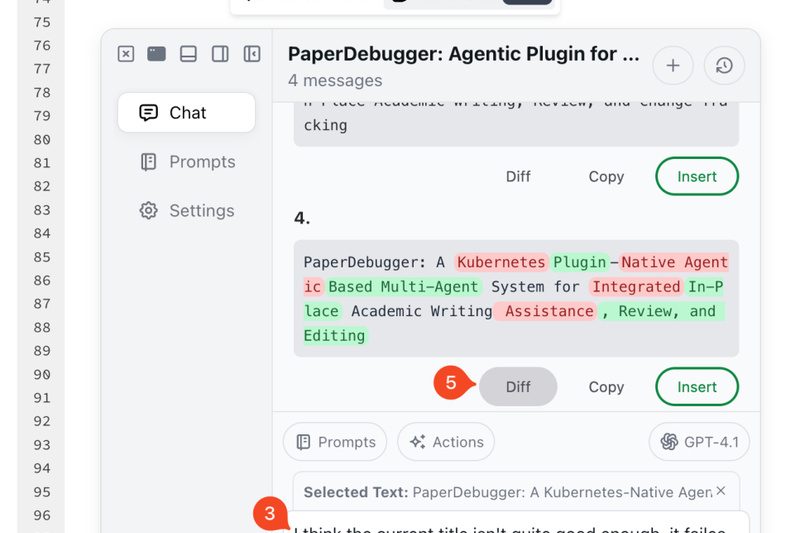
Academic writing is a deeply iterative and often fragmented process. Researchers routinely juggle LaTeX editors like Overleaf, reference managers, peer…
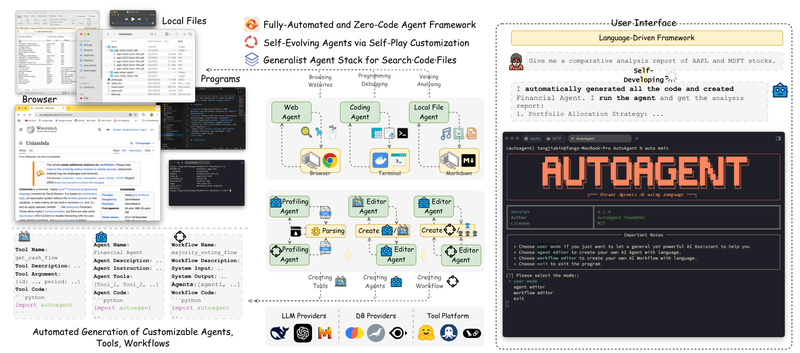
Building AI agents today usually means writing code. Frameworks like LangChain and AutoGen have unlocked incredible capabilities—but they also demand…
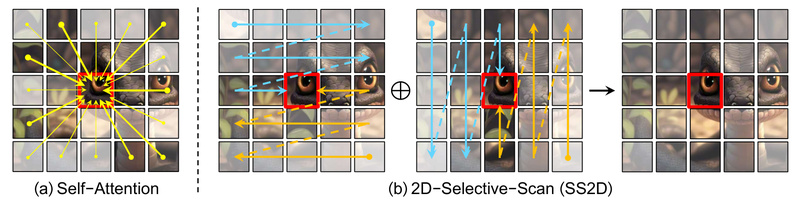
In the rapidly evolving landscape of computer vision, model efficiency and scalability are no longer optional—they’re essential. Enter VMamba, a…
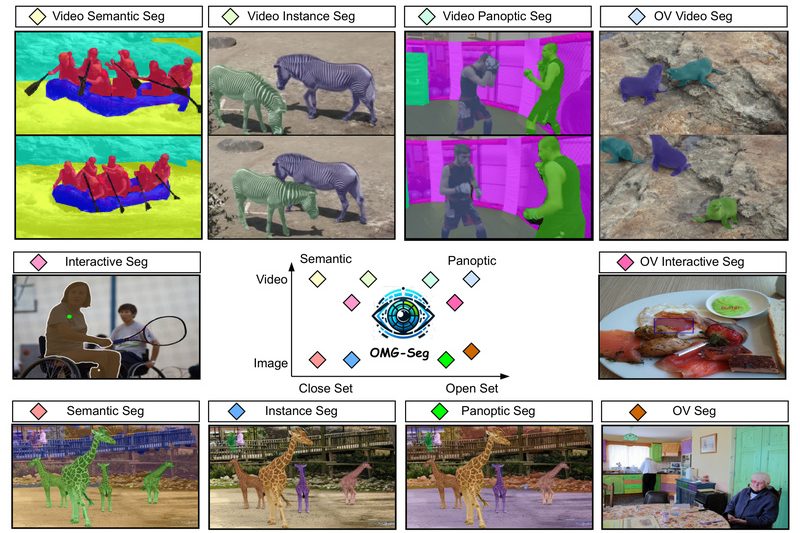
For years, computer vision practitioners have juggled a patchwork of specialized models to tackle different segmentation tasks—semantic, instance, panoptic, video,…
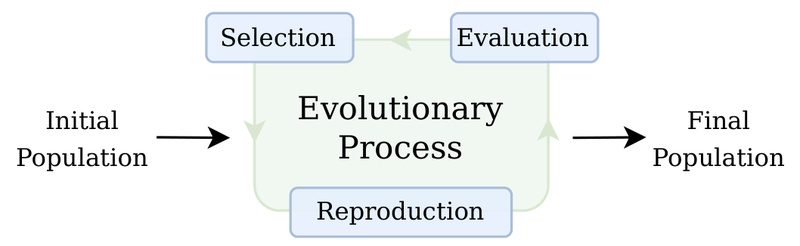
Evolutionary Computation (EC) has long been a powerful approach for solving complex optimization problems—especially where gradients are unavailable, environments are…
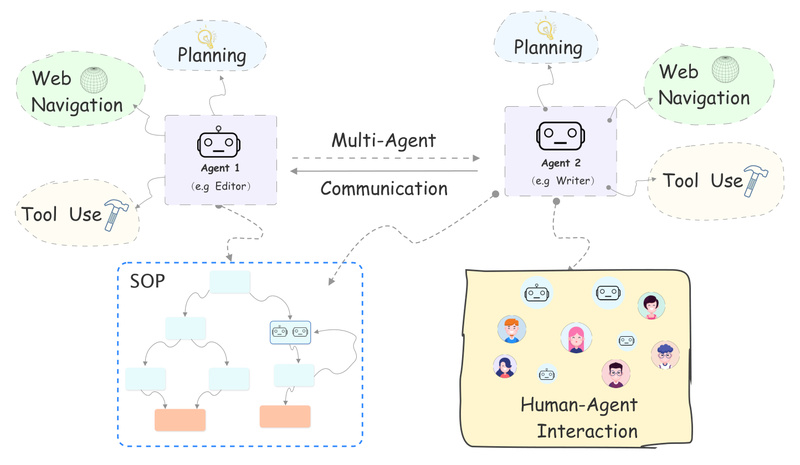
In today’s fast-moving AI landscape, organizations and researchers increasingly need intelligent systems that don’t just respond to commands—but plan, collaborate,…