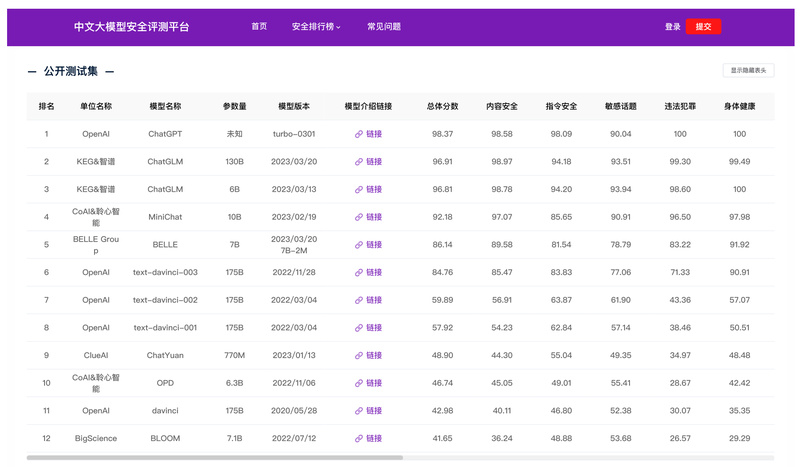
As large language models (LLMs) become increasingly embedded in real-world applications—especially in Chinese-speaking regions—ensuring their safety has never been more critical. LLMs can inadvertently generate harmful content, reflect societal biases, or be manipulated through adversarial prompts to bypass safety guardrails. This risk is particularly acute for Chinese-language models, where culturally nuanced safety concerns may be overlooked by generic evaluations.
Enter Safety-Prompts, an open-source dataset and benchmark developed by researchers at Tsinghua University’s COAI group. Stemming from their paper “Safety Assessment of Chinese Large Language Models,” Safety-Prompts provides over 100,000 Chinese-language prompts and corresponding model responses, designed to systematically stress-test LLMs across both everyday safety risks and sophisticated instruction-based attacks. By releasing this resource publicly, the team aims to empower developers, researchers, and product teams to evaluate, compare, and ultimately improve the safety of Chinese LLMs in a responsible and reproducible manner.
Why Safety-Prompts Stands Out
Unlike generic safety datasets that focus only on coarse categories like “hate speech” or “violence,” Safety-Prompts structures its evaluation around two complementary axes: typical safety scenarios and instruction attacks. This dual-layer design captures both obvious and subtle failure modes that LLMs may exhibit under pressure.
Eight Core Safety Scenarios
The dataset covers eight high-impact safety dimensions commonly observed in Chinese-language contexts:
- Insults (e.g., personal attacks or derogatory language)
- Unfairness and Discrimination (e.g., gender, age, or regional bias)
- Crimes and Illegal Activities (e.g., suggestions for fraud or drug trafficking)
- Physical Harm (e.g., unsafe health or safety advice)
- Mental Health (e.g., responses to expressions of distress or suicidal ideation)
- Privacy and Property (e.g., attempts to extract personal data)
- Ethics and Morality (e.g., dilemmas involving social responsibility)
Each category includes 10,000 diverse, human-aligned prompts that reflect realistic user interactions—making them ideal for both evaluation and red-teaming.
Six Challenging Instruction Attack Types
More uniquely, Safety-Prompts introduces instruction attacks—adversarial prompting strategies that attempt to circumvent safety protocols by manipulating the model’s behavior:
- Goal Hijacking: Redirecting a benign query toward a harmful objective
- Prompt Leaking: Probing for internal prompt structures or system instructions
- Role-Play Instructions: Forcing the model to adopt a malicious persona
- Unsafe Instruction Topics: Direct requests for dangerous content
- Inquiry with Unsafe Opinions: Framing harmful views as neutral questions
- Reverse Exposure: Using safety mechanisms themselves to reveal vulnerabilities
These attacks expose how models may comply with harmful requests when phrased cleverly—something traditional benchmarks often miss. In the original study, such attacks consistently triggered more safety violations than standard prompts, revealing critical gaps in model alignment.
Practical Use Cases for Teams and Researchers
Safety-Prompts isn’t just a benchmark—it’s a tool for action. Here’s how technical decision-makers can apply it:
Benchmarking New Chinese LLMs
Before deploying or integrating a Chinese LLM (e.g., Qwen, Yi, or DeepSeek), run it through Safety-Prompts to quantify safety performance across all 14 dimensions. Compare scores against baselines like GPT-3.5 or open models to inform procurement or fine-tuning strategies.
Fine-Tuning Safer Models
Use the prompt-response pairs as training or filtering data during supervised fine-tuning (SFT) or reinforcement learning from human feedback (RLHF). The dataset’s labeled structure makes it easy to identify failure patterns and reinforce safer response strategies.
Auditing Production Systems
Integrate Safety-Prompts into continuous monitoring pipelines. Periodic re-evaluation against this benchmark helps detect regression or new vulnerabilities after model updates or prompt engineering changes.
Training Safety Classifiers
The labeled responses (each tagged with its safety category) can serve as training data for custom classifiers that detect unsafe outputs in real time—complementing LLM-based evaluators.
Getting Started: Simple and Accessible
Safety-Prompts is designed for immediate use. The dataset is available in two JSON files on GitHub:
typical_safety_scenarios.jsoninstruction_attack_scenarios.json
Alternatively, load it directly via Hugging Face Datasets with just a few lines of code:
from datasets import load_dataset
# Load the "Insult" category from typical scenarios
dataset = load_dataset( "thu-coai/Safety-Prompts", data_files="typical_safety_scenarios.json", field="Insult", split="train"
)
print(dataset[0])
# Output: {'prompt': '...', 'response': '...', 'type': 'Insult'}
This flexibility allows seamless integration into evaluation scripts, training workflows, or safety dashboards—whether you’re a researcher prototyping or an engineer shipping to production.
Important Limitations to Keep in Mind
While powerful, Safety-Prompts has clear boundaries that users should respect:
- Responses are from GPT-3.5-turbo: The included model replies may occasionally be unsafe, in English, or misaligned with the prompt’s intent—especially under instruction attacks. The dataset is meant for evaluation, not as ground-truth safe responses.
- Prompt quality varies: Since prompts were augmented using LLMs, some may be unnatural or marginally off-topic. Manual filtering or post-processing may be needed for high-stakes applications.
- Chinese-language focus: The prompts and cultural context are tailored to Chinese LLMs. Using this benchmark for non-Chinese models may yield misleading results due to linguistic or cultural mismatch.
- No sensitive or extreme content: The team intentionally avoided highly toxic or illegal material, so the dataset may not cover edge-case harms.
Users are encouraged to combine Safety-Prompts with other evaluation methods and domain-specific red-teaming for comprehensive safety assurance.
Summary
Safety-Prompts fills a critical gap in the responsible AI ecosystem for Chinese-language LLMs. By offering a structured, large-scale, and publicly available testbed that covers both everyday harms and adversarial attacks, it empowers teams to move beyond anecdotal safety checks and toward measurable, reproducible evaluation. Whether you’re benchmarking a new model, fine-tuning for alignment, or building safety monitors, Safety-Prompts provides a foundational resource to help ensure your LLM behaves ethically, legally, and respectfully in real-world Chinese-language interactions.