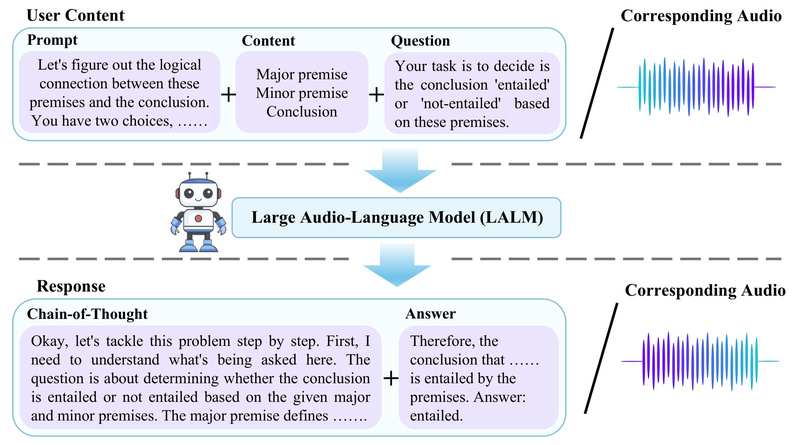
Most large language models (LLMs) today excel at reasoning over text—but what happens when the input includes sounds? Can an AI system hear a sequence of beeps, a siren, or a mechanical rattle and logically infer what’s happening, why it matters, and how to respond? This is the core challenge that SoundMind tackles.
SoundMind is not just another audio captioning tool. It is a research-driven framework specifically designed to equip audio-language models (ALMs) with the ability to perform logical reasoning across both audio and text. Unlike traditional speech-to-text systems that transcribe what is said, SoundMind helps models understand what is happening based on auditory cues and reason about it in natural language. This capability opens doors to more intelligent, context-aware assistants, diagnostic tools, and safety systems that truly “listen and think.”
At its foundation, SoundMind includes two tightly integrated components:
- A purpose-built dataset of 6,446 high-quality audio-text samples, each annotated with detailed chain-of-thought reasoning paths.
- SoundMind-RL, a novel, rule-based reinforcement learning (RL) algorithm that trains ALMs to follow logical structures when reasoning about audio inputs.
Together, they enable models like Qwen2.5-Omni-7B to significantly outperform existing baselines on audio logical reasoning (ALR) tasks—proving that specialized data and tailored training matter.
Why Audio Logical Reasoning Matters
Today’s multimodal AI systems often treat audio as a secondary signal—something to be transcribed and then processed like text. But real-world audio contains rich, non-verbal information: the pitch of an alarm, the rhythm of footsteps, the irregular hum of a failing motor. Extracting meaning from these signals requires more than pattern matching—it demands reasoning.
For example:
“The engine made a knocking sound three times, then stopped. The dashboard showed no warning lights. What’s the most likely cause?”
Answering this requires integrating auditory observation (“knocking sound”), temporal sequencing (“three times, then stopped”), and contextual knowledge (“engine mechanics”)—a task well beyond transcription or simple classification.
SoundMind addresses this gap by providing both the data and the training methodology needed to teach models how to reason—not just listen.
Key Innovations That Make SoundMind Stand Out
1. The SoundMind Dataset: Reasoning, Not Just Recognition
The dataset contains 6,446 carefully curated samples where each audio clip is paired with a multi-step reasoning chain in natural language. These aren’t just labels like “car engine” or “dog barking.” Instead, they explain how to interpret the sound:
“The intermittent screeching suggests worn brake pads. The timing aligns with wheel rotation, not electrical systems.”
This design forces models to move beyond associative learning into causal and deductive reasoning—critical for real-world decision-making.
2. SoundMind-RL: Rule-Guided Reinforcement Learning
Rather than relying solely on supervised fine-tuning, SoundMind introduces SoundMind-RL, a rule-based RL framework. It uses predefined logical rules (e.g., “if a sound repeats at regular intervals, consider mechanical causes”) to shape reward signals during training. This encourages the model to generate reasoning steps that align with human-like logic, not just statistical patterns.
When applied to Qwen2.5-Omni-7B, this approach yields consistent gains over state-of-the-art baselines on the SoundMind benchmark—proving that structured reasoning can be learned through targeted RL.
3. End-to-End Multimodal Integration
SoundMind doesn’t treat audio and text as separate streams. It leverages the Qwen2.5-Omni architecture, which natively fuses audio and text tokens, enabling true cross-modal reasoning. The result? Models that don’t just “hear and describe,” but “hear, contextualize, and infer.”
Ideal Use Cases for SoundMind
SoundMind is ideal for applications where understanding why a sound occurs is as important as recognizing what it is. Consider these scenarios:
- Industrial Diagnostics: An AI assistant listens to factory equipment and reasons about potential failures: “The high-frequency whine correlates with bearing wear, not lubrication issues.”
- Smart Home Safety: A system hears glass breaking followed by silence and infers a possible intrusion, triggering appropriate alerts.
- Educational Tools: A tutoring app explains scientific phenomena through sound: “This resonance frequency matches the natural vibration of the wine glass—here’s why it shattered.”
- Accessibility Aids: For visually impaired users, a device not only identifies sounds (“siren”) but explains their implications (“emergency vehicle approaching from the left”).
In each case, the value lies not in detection alone, but in interpreting and explaining—exactly what SoundMind enables.
Getting Started with SoundMind
SoundMind is open-source and publicly available on GitHub. Here’s how to begin:
-
Download the Dataset
The SoundMind dataset is available via Hugging Face or Dropbox. It includes train, validation, and test splits with JSON metadata and audio files. -
Set Up the Environment
- Use Python 3.10+ and CUDA 12.4+
- Install dependencies:
verl,vLLM,SGLang,transformers==4.52.3, andqwen-omni-utils - Create a dedicated Conda environment to avoid package conflicts
-
Preprocess Data
Convert the raw dataset into Parquet format using one of three modes:- Dual-modality (audio + text)
- Text-only (for ablation studies)
- Audio-only (for modality-specific analysis)
-
Run Training or Inference
- Use the provided checkpoint for immediate evaluation
- Or fine-tune from the base Qwen2.5-Omni-7B model using
main_grpo.sh, which implements the SoundMind-RL training loop
The codebase is built on verl, a flexible RL framework, making it modular and extensible for researchers who want to experiment with alternative reward designs or base models.
Limitations and Practical Considerations
While powerful, SoundMind comes with important constraints:
- Hardware Requirements: Training requires 8× NVIDIA H800 or H100 GPUs (80GB each)—making it unsuitable for small labs or individual developers without cloud access.
- Model Dependency: The current implementation is tightly coupled with Qwen2.5-Omni-7B. Adapting it to other architectures would require significant engineering effort.
- Task Specialization: The dataset focuses exclusively on logical reasoning tasks, not general audio processing (e.g., speech recognition, music classification). It won’t improve performance on unrelated audio benchmarks.
That said, for teams focused on reasoning-rich audio-language applications, SoundMind offers a rare combination of high-quality data, a novel training algorithm, and strong empirical results.
Summary
SoundMind represents a meaningful step toward auditory intelligence in multimodal AI. By combining a reasoning-centric dataset with a rule-guided reinforcement learning framework, it empowers audio-language models to do more than transcribe—they can now analyze, infer, and explain.
If your project demands AI that understands not just what is being said or heard, but why it matters, SoundMind provides both the foundation and the methodology to make it happen. With public access to code, data, and models, it’s ready for adoption in research labs and advanced R&D teams pushing the boundaries of multimodal reasoning.