Video face restoration is a critical yet challenging task in real-world applications—whether you’re enhancing surveillance footage, digitizing decades-old home videos, or cleaning up low-bandwidth video calls. Traditional approaches often treat each degradation type in isolation: one tool upscales blurry faces, another adds color, and a third fills in occluded regions. But this piecemeal strategy breaks down when applied to videos, where temporal consistency, natural motion, and cross-frame coherence are just as important as per-frame quality.
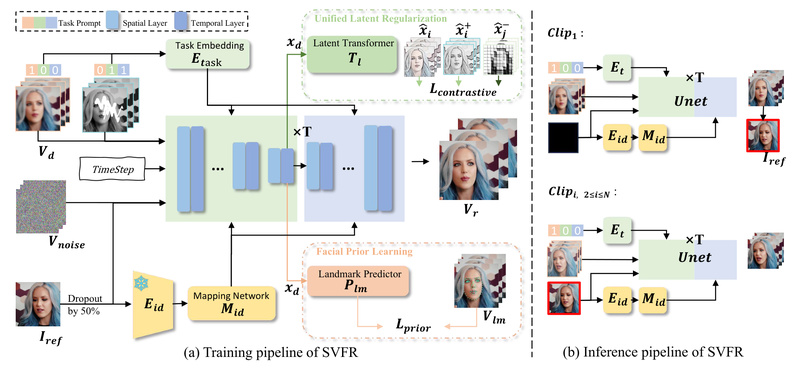
Enter SVFR (Stable Video Face Restoration)—a unified framework that simultaneously handles Blind Face Restoration (BFR), colorization, and inpainting within a single, temporally coherent pipeline. Built on the motion-aware backbone of Stable Video Diffusion (SVD), SVFR doesn’t just improve individual frames—it produces smooth, lifelike face videos that look naturally consistent across time.
Why Existing Tools Fall Short for Video Faces
Most face restoration systems today are designed for static images. When applied frame-by-frame to videos, they often introduce flickering, inconsistent skin tones, or jittery facial features—artifacts that destroy the illusion of realism. Worse, many real-world face videos suffer from multiple degradations at once: they’re blurry and grayscale and partially masked by logos, hands, or poor framing.
Separate tools for each problem compound the issue:
- Running BFR first, then colorization, then inpainting leads to error propagation.
- Each model makes independent decisions, ignoring how tasks can inform one another (e.g., high-frequency texture from BFR helps guide plausible colorization).
- No shared temporal model means no guarantee that the face moves smoothly from frame to frame.
SVFR directly addresses these gaps by treating video face restoration as a generalized, multi-task, and temporally aware problem.
How SVFR Unifies Restoration Tasks Without Compromise
SVFR’s architecture is built around three key innovations that enable high-quality, stable output across diverse degradation scenarios:
1. Leveraging Stable Video Diffusion for Motion Priors
Rather than starting from scratch, SVFR adapts Stable Video Diffusion (SVD)—a diffusion model pretrained on vast video data—to inherit strong priors about natural human motion, head pose dynamics, and temporal smoothness. This foundation ensures that even heavily degraded inputs are restored with realistic motion, not just static “snapshot” quality.
2. Task Embeddings for Flexible Multi-Task Inference
SVFR introduces learnable task embeddings that tell the model which restoration tasks are active (e.g., BFR only, or BFR + colorization + inpainting). This allows the same unified model to:
- Restore a blurry grayscale video in color (task IDs 0,1)
- Fix a video with missing facial regions (task ID 2)
- Or handle all three issues at once (task IDs 0,1,2)
All without retraining or switching between separate models.
3. Unified Latent Regularization (ULR) and Self-Referred Refinement
To encourage synergy between tasks, SVFR uses Unified Latent Regularization (ULR)—a technique that aligns feature representations across subtasks in latent space. Complementing this, facial prior learning and self-referred refinement further boost detail fidelity and temporal stability during both training and inference.
The result? A system where colorization benefits from sharp BFR outputs, inpainting respects motion trajectories, and all tasks collectively produce videos that look naturally restored, not artificially processed.
Where SVFR Delivers Immediate Value
SVFR isn’t just a research prototype—it solves concrete problems across multiple domains:
- Archival & Heritage Media: Restore old family videos or historical interviews that are grainy, monochrome, or partially damaged.
- Security & Surveillance: Enhance low-resolution CCTV footage where faces are small, blurry, or obscured—critical for identification.
- Remote Communication: Improve compressed or poorly lit video calls by jointly sharpening faces, recovering skin tones, and removing artifacts.
- Content Creation: Prepare user-generated content (e.g., social media clips) for professional use by automatically correcting multiple visual flaws in one pass.
Crucially, users aren’t forced into an “all-or-nothing” workflow. Need only BFR? Use --task_ids 0. Need full restoration? Use --task_ids 0,1,2. The framework adapts to your specific need.
Getting Started: From Installation to Inference in Minutes
SVFR is designed for practical adoption, not just academic benchmarking. Here’s how to run it—even without deep learning expertise:
Prerequisites
- A GPU with 16GB+ VRAM (required for smooth inference)
- Python 3.9+ and basic command-line familiarity
Setup
conda create -n svfr python=3.9 -y conda activate svfr pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pip install -r requirements.txt
Model Download
SVFR builds on Stable Video Diffusion and includes custom face restoration checkpoints. You’ll need to:
- Clone the SVD base model from Hugging Face
- Download SVFR-specific weights (e.g.,
unet.pth,id_linear.pth) and place them in themodels/directory as specified in the repo
Running Inference
Restore a blurry video with BFR only:
python3 infer.py --config config/infer.yaml --task_ids 0 --input_path input.mp4 --output_dir ./results/ --crop_face_region
Or restore a grayscale, occluded video with all three tasks:
python3 infer.py --task_ids 0,1,2 --input_path input.mp4 --mask_path mask.png --output_dir ./results/ --crop_face_region
The --crop_face_region flag automatically crops to the face region—essential for focusing processing power where it matters most.
For quick experimentation, SVFR also includes a Gradio web demo (python3 demo.py) that requires no coding.
Limitations and Practical Considerations
Before integrating SVFR into your pipeline, note these constraints:
- Hardware: Requires a GPU with ≥16GB VRAM; not suitable for CPU-only or edge devices.
- Scope: Optimized for facial regions only—not full-body or general scene restoration.
- Licensing: The provided pretrained models are for non-commercial research use only, per the project’s license.
- Input Format: Best results come from square videos (equal width/height). Non-square inputs are automatically cropped to the face region when
--crop_face_regionis enabled.
These limitations reflect SVFR’s focused mission: delivering state-of-the-art video face restoration, not general-purpose video enhancement.
Summary
SVFR redefines what’s possible in video face restoration by unifying BFR, colorization, and inpainting into a single, temporally coherent framework. Instead of chaining error-prone, single-purpose tools, you get one model that leverages task synergy, motion-aware diffusion priors, and refined facial representations to produce natural-looking results. Whether you’re digitizing archival footage or enhancing real-time communication, SVFR offers a practical, flexible, and high-fidelity solution—backed by open-source code and ready for real-world deployment.